When does a lifeboat look like a Scotch Terrier? It would appear that, if you’re an AI, the difference is a few pixel-shifts, and that’s got interesting implications.
I’m not particularly worried about AI-based facial recognition, because it’s like worrying about gravity after you’ve been pushed off a bridge: you may as well compose yourself and try to enjoy the ride down. Because certain things are going to happen.

self-portrait, 2017
I do think there’s some fun to be had trying to interfere with facial recognition algorithms, and I did some personal camouflage this fall, when I was farting around over at the studio – since I know that facial recognition systems render down our features into abstract elements, then do fuzzy matches against those elements and a database (generated with similar renderings) – there is a certain value to being able to invalidate the down-rendering algorithm. Especially if the database caches its own down-rendered versions; suppose someone had to update the renderer to recognize non-skin texture and change how it reduces the features: now they’d have to re-scrub the entire database of 50 million faces. Jamming these algorithms might be good, healthy, passive-aggressive fun.
Janelle Shane posted a link to a really interesting article on “adversarial noise” – the idea being, to produce carefully-designed noise that fuzzes the AI recognizer but not a human’s evolved-in recognizer. It turns out the human’s recognizers are evolved to defeat natural attempts at noise injection (also known as “camouflage”) as practiced by Bunny. You can see that what Bunny is doing is aligning with the landscape to blend in, and breaking the characteristic outlines of its body (nose, ears, eyes) by hiding them behind pieces of grass that break the outlines. Bunny is adding noise to what my eyes see and – it works! Bunny is nearly invisible.

Camouflage theory is pretty neat stuff. Back around the Franco-Prussian War, nations began to realize that being super-visible on battlefields or at sea was not such a great idea. Suddenly warships got exotic paint-jobs instead of polished brass, and soldiers (except for the French) began to blend in to their surroundings. One of the rules of camouflage was to “break lines” wherever possible – because the human eye/mind appears to do exactly what I described above: part of it tries to down-render a scene into edges, then we analyze based on the edges. Meanwhile, another analysis engine appears to analyze based on color. We don’t really understand how it all works, because we can’t pop the human algorithms into a debugger and look at all the various weightings and edge-detection routines and so forth – like we can in Photoshop.
Correctly tuned noise appears to devastate some image recognition algorithms.

I wonder how the algorithms’ designers will respond? My guess is, looking at that with my human eyes and brain, it’ll recognize certain areas as unusually noisy and ignore them. Poof. When I see that chunk of noise in the lower right, I immediately think “nothing there” and go back to looking at Lifeboat McLifeboatFace and wondering why it doesn’t have solar panels.
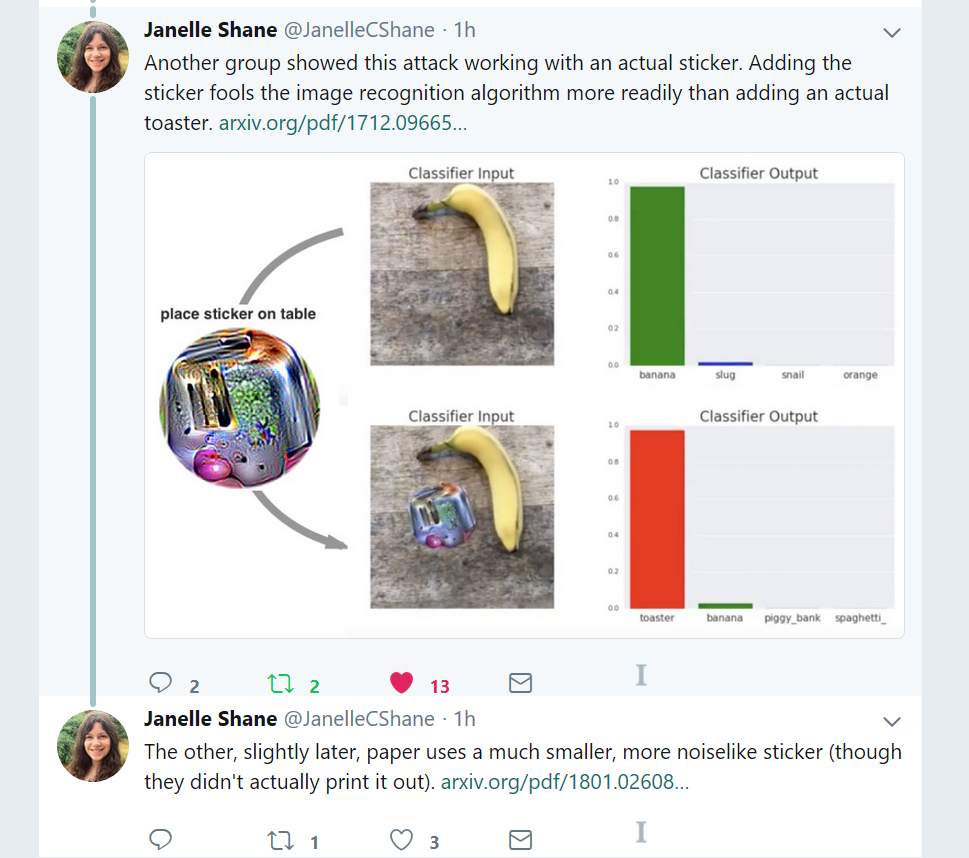
Here’s a link to the paper on adversarial noise. It’s got some neat illustrations. [arx]
The WWI-era camouflage was called “Dazzle” camouflage and I … I’m not impressed at its ability to hide ships. It looks cool as all get-out, though! When I was a kid there was an exhibit at Les Invalides with some of the original watercolor designs for the French Navy and they’re really quite beautiful. [wikipedia] The theme seems to be the same as Bunny’s camouflage: break edges, add noise. Perhaps the German U-boat commander will think that they are seeing a gigantic Scotch Terrier.

Yes, it’s a Scotch Transport. Wait, “terrier” not “transport.”

I am a toaster oven.
One of the other alleged values of dazzle camouflage was that it would interfere with an attacker’s ability to compute the range to the target ship. I’m highly skeptical of that, since naval ships, by WWI, used triangulating range-finders, which would actually work better against a target in dazzle camouflage, since lining up the image of the dazzle-painted ship accurately would be even easier. Those range-finders work by having two lenses a known distance apart, which you overlap the images from on a screen; then you can calculate the range using simple trigonometry (it’s how our eyes and brains do range estimation, too!)

Janelle Shane’s twitter feed is pretty cool. She does a lot of play with neural networks, mostly programming them to produce surrealistic results.
Searching for “Dazzle camouflage” brought me this amazing image:

Yeah, baby.
With all this stuff, I think you can defeat it with a bit of introspection around “what does my brain do?” The edges, in my edge-detected self-portrait, are too sharp. The variety of tones in the adversarial noise is too dense for the size of the region; things in reality don’t have such large shifts in a small area. If you think about how your brain is defeating the adversarial noise, that’s what the algorithm designers of the AIs are going to try to do next.
This probably goes without saying, but I think mis-classification is what’s going on when our brains are on drugs. So, you take a dose of LSD or some shrooms and they mess with your norepinephrine levels in your brain. Some of that is going to result in spurious signals in your visual system, and your visual pattern-matching system takes over and goes, “right, now, what is that pulsating blobby thing!?” And, because it’s messed up, too, it goes, “yes, Cthulhu really is in your refrigerator!”
Some background on what exactly is going on here (with some math): Neural networks just construct a partition of the data space (i.e. the space of possible n-by-m-pixel images, represented as an n*m*3-dimensional vector space) by hyperplanes, and then assign a value (‘dog’, ‘cat’, ‘banana’) to each chamber of the partition. Each image is a point in that space, which then gets labelled according to which chamber it is in. (For a 2-D visualisation, draw some straight lines on a piece of paper, you’ll get the idea about chambers right away. Notice that the chambers on the edges are open outwards, and so very big compared to the inner ones.)
What you’re doing when you add noise is to translate your image (point) to somewhere else in the data space, which can easily put it in a different chamber. If you happen to know the label of a big open chamber, it’s not too hard to find a bit of noise (a.k.a. a direction vector in your vector space) that will reliably put you in that chamber, regardless of where you start.
Scotch Terrier => Scottish Terrier
@Reginald Selkirk: Damn. I was imagining a drunk dog…
Surely these noise patches are crafted especially for their particular classifier, in its current state of learning. I’m sure that more training with a larger data set would eliminate, or at least dilute, their effect.
This highlights one of the fundamental problems of such classifiers: not being inteligent, they are not able to extract salient traits. They use everything in the image to learn what a badger looks like, including the background, lighting, or particular accidents of texture. They over-learn meaningless details.
What the article shows is that, with access to a little more detail than just the “yes, it’s a badger” output, one can exploit this over-learning to create a strong signal that obliterates the one from the image.
Something like this happens in nature, too. Look up supernormal stimulus. Simple recognizers or classifiers are fooled by it: seagull chicks prefer the stick with two bright red spots to their parent with a single spot, even though pecking on the parent’s spot results in food and pecking on the stick results in nothing at all. As long as there aren’t many objects with red spots around seagull nests, that dumb response is good enough and there’s no pressure to evolve anything more precise than that.
One word for a herd of zebra is “dazzle”.
To be fair to bright-colored military uniforms, in the black-powder era being able to see other soldiers and tell which side they were on even with a lot of smoke around was important for minimizing “friendly” fire, and that advantage may have outweighed the disadvantages of being unable to conceal oneself from the enemy. It’s probably no accident that the move toward more neutral tones really picked up when smokeless powder came into use.
Speaking of LSD, I must give a link to one of my favorite talks, which also happens to be on this subject.
A talk about synesthesia
> V.S. Ramachandran at Beyond Belief 2007 Part 1 (of several parts)
Aww, I was thinking of posting on this. Oh well, this gives me an excuse to share an even better example of fooling AI.
I thought the point of dazzle camoflage was to give the ship a periodic appearance, so the guy trying to line up the two images would match one part of the ship to a completely different, similar-looking, part?
dorlfl@#9:
I thought the point of dazzle camoflage was to give the ship a periodic appearance, so the guy trying to line up the two images would match one part of the ship to a completely different, similar-looking, part?
Yes, there was that, too. Mess up range-finders, etc. It turns out that just didn’t work very well and improved radar made it all completely irrelevant anyway.
cvoinescu@#4:
Surely these noise patches are crafted especially for their particular classifier, in its current state of learning. I’m sure that more training with a larger data set would eliminate, or at least dilute, their effect.
They are algorithm and data-state dependent. So, for them to really work, you need “insider information.”
Ketil Tveiten’s explanation@#1: is good – the data-set is a digest, or a probability map of the inputs and the algorithm matches the current input to the best digest that it has in its collection. By the time the digests have been made, the input has (usually) been thrown away, so the algorithm doesn’t have another way to check the input against the data from which the digest was created. That’s why, for example, the NSA’s data-farm in Utah keeps everything – if they needed to, they could come up with multiple recognizers and then do a first order check, then retrieve the best couple matches and compare them in turn with other recognizers. That appears to be what our brains do.
I thought the main advantage of the dazzle camoflage was in obscuring the ship’s heading? A u-boat commander could know the exact bearing and range, but if you don’t know where the ship’s going to be when his torpedo arrives, he isn’t going to hit it? But it’s possible I would have made a very poor u-boat commander…and an even worse convoy ship captain!
AsqJames@#12:
I thought the main advantage of the dazzle camoflage was in obscuring the ship’s heading? A u-boat commander could know the exact bearing and range, but if you don’t know where the ship’s going to be when his torpedo arrives, he isn’t going to hit it?
It’s possible it may have helped a tiny bit for a little while in WWI but by WWII I believe the systems in submarines had evolved pretty far – you could get an idea of a target’s heading by doing 2 rangings – which is why convoys started to maneuver in unpredictable turns. There was a lot of co-evolution taking place on the high seas!
(I’m going out on a limb, here but from reading too many books by Edward L. Beach as a kid, it probably didn’t make much difference anyway since most Uboat attack plans involved taking a rear shot against the target, in which case the target is just receeding slightly from your spread of torpedoes.)
EnlightenmentLiberal@#7:
Thank you for posting that. Ramachandran is a pretty good source of cool ideas (I love how he explains things) and I am looking forward to giving that a watch next time I am someplace with good bandwidth.
I’m betting its all about activation levels…
With an AI, recognition is a probability game, and my understanding of how memories appear to work is that the nerves have varying probabilities of firing (“a memory”) based on how often they fired before, which is altered by caffeine, alcohol, amphetamines, pretty much anything. I know someone who is mildly synaesthetic who went full-blown the first time he tried mushrooms. That must have been interesting.