Corporatism favors the rights of corporations ahead of those of their customers; right now we’re in the middle of a complex shouting-match regarding what companies like Facebook can decide to provide to marketing partners; are we trusting them too much with our data? Are they going to handle it responsibly? What makes people imagine that companies are not going to immediately have a strategy meeting and ask, “what is the worst thing we can do with our customer data? Because: let’s do that!”

I did a google image search for “retroscope” and look at this beauty!
The worst of it gets done under the rubric of service-level agreements or “shrink wrap” licenses – some document that says (down in the fine print) “use of our system is taken as consent for us to provide data to partners, as we see fit.” As much as I loathe “targeted advertisement” systems, they’re not really the problem. The problem is: what happens when the data you thought was private gets fed into the retro-scope?
Once it’s in there, it’s never coming out – even if it’s wrong or partial. One of the big concerns some of us have, is that the information is going to wind up in some great big data-dump somewhere, and matching algorithms will trawl through it, looking for new relationships that can be constructed, then added back into the data-pile (as possibly inaccurate “conclusions”) – it’s bad enough when it’s done in the name of marketing, but what if some corporate executive just decides to give the data away to be helpful? Imagine the terms of service say “we will never sell your data!” (that’s right: we’ll give it away) and “we are not a medical service provider” (so we are not covered by medical privacy regulations like HIPAA or HITECH). Once a copy of the data has been shared, it’s now part of someone else’s data pile and they will never delete it, because they don’t have to.
Some organizations have particularly nasty habits regarding data deletion and aggregation. Not surprisingly, those are the same organizations that build retro-scopes – the FBI, the NSA, and the rest of the world’s equivalents. But Amazon.com isn’t so great, either – their Rekognition system has a huge, unregulated, backing store of images to match against. So does the FBI’s face recognition database; thanks to “voluntary sharing” between state motor vehicle databases, they have at least everyone’s driver’s license photo(s) going back years. Amazon’s got a gigantic data set, too. [rekognition]
Amazon Rekognition makes it easy to add image and video analysis to your applications. You just provide an image or video to the Rekognition API, and the service can identify the objects, people, text, scenes, and activities, as well as detect any inappropriate content. Amazon Rekognition also provides highly accurate facial analysis and facial recognition on images and video that you provide. You can detect, analyze, and compare faces for a wide variety of user verification, people counting, and public safety use cases.
Amazon Rekognition is based on the same proven, highly scalable, deep learning technology developed by Amazon’s computer vision scientists to analyze billions of images and videos daily, and requires no machine learning expertise to use. Amazon Rekognition is a simple and easy to use API that can quickly analyze any image or video file stored in Amazon S3. Amazon Rekognition is always learning from new data, and we are continually adding new labels and facial recognition features to the service.
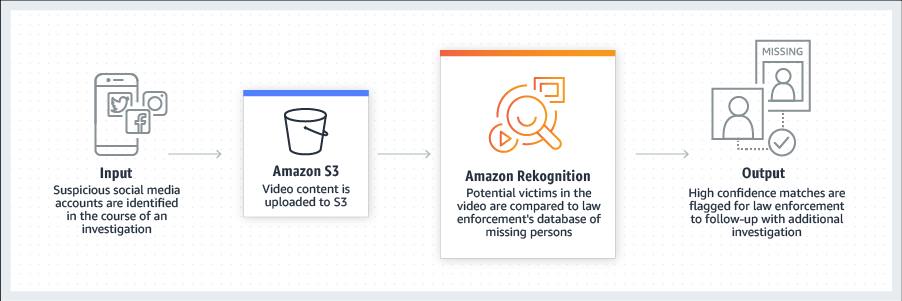
The “adding new labels and features” part is what ought to worry you. These systems, like the FBI’s face recognition database, are being built with inadequate regulation: the algorithms get changed and they may affect you and you’ll never know.
That all sets the stage for why this worries me: [reg]
Some would argue he has broken every ethical and moral rule of his in his profession, but genealogist Bennett Greenspan prefers to see himself as a crime-fighter.
“I spent many, many nights and many, many weekends thinking of what privacy and confidentiality would mean to a genealogist such as me,” the founder and president of FamilyTreeDNA says in a video that appeared online yesterday.
He continues: “I would never do anything to betray the trust of my customers and at the same time I felt it important to enable my customers to crowd source the catching of criminals.”
His “customers” are not the people who are interested in catching criminals. His customers use his service to see who they are related to, or whether their DNA contains the markers for possible disorders. Perhaps they are racists, who want to discover their ancestry is human. Almost certainly his “customers” are not the FBI.
And so, by crowd sourcing, what Greenspan means is that he has reached an agreement with the FBI to allow the agency to create new profiles on his system using DNA collected from, say, corpses, crime scenes, and suspects. These can then be compared with genetic profiles in the company’s database to locate and track down relatives of suspects and victims, if not the suspects and victims themselves.
I understand and appreciate the idea, but not the implementation. The FBI is not trustworthy. There are well-documented incidents in which the FBI has used DNA evidence to convict, while ignoring DNA evidence that exonerates. Allowing them to do this sort of thing in secret is allowing them to control the knowledge about their searches; in other words they might automatically check to see if you’re implicated as a serial killer. There’s an asymmetry of knowledge problem if the FBI is checking to see if you’re a serial killer, but they are not checking to see if everyone who is in prison as a serial killer may actually be exonerated by DNA evidence. Since this was all happening in semi-secret, nobody was able to question the FBI’s approach.
I’m also curious as to whether or not the database was protected against large-scale scraping. The FBI generally isn’t technically sophisticated enough, but if you gave the NSA access to a database like that, they’d slurp the whole thing down into some classified database someplace else, and probably eventually leak it to every other intelligence agency in the world. Does this matter? I don’t know. It ought to be a matter of public policy that is examined a bit more closely before someone decides to “just do it.”
“In order for the FBI to obtain any additional information, they would have to provide a valid court-order such as a subpoena or search warrant.”
The problem is that the FBI won’t need a search warrant against a particular database – all they need to know is that somewhere, out there, is a DNA sample that matches someone. The rest of the data they want is in the NSA’s database; they just need to know where to look.
What are the public policy problems with this? I’m not asking rhetorically – I have no idea. Off the top of my head, I think it’s not unreasonable to let the FBI discover if there may be a DNA record that points to a serial killer, rapist, or whatever. But can we/should we also require that the FBI check for exonerating DNA information for any prisoner that requests it? The scenario as it’s presented appears to be: someone gets a knock on the door, answers, and is handcuffed and arrested because new DNA evidence pinned a murder on them. Shouldn’t that scenario be counter-balanced by a prisoner being informed “we’re releasing you because we just found out that you really didn’t do that crime you’ve been saying you didn’t do.” What if you have someone on death row for a crime they say they didn’t commit, and the FBI uses a DNA database to discover that, in fact, someone else did the crime? Obviously, the guy on death row is exonerated and the state owes them a huge apology for convicting them on false evidence. Does that sound incredible? It’s not. In the US, racist policing practices and selective prosecution have resulted in exactly that sort of situation in the past. It seems to me that someone needs to be telling the FBI, “OK, so now you’ve got access to DNA databases: we want you to spend as much time trying to exonerate people as you spend trying to convict people.” How would that work?
There’s also a public policy issue in this story that really concerns me: corporations have way too much leeway to make decisions regarding data that they have been entrusted. Once you move past the “catch serial killers!” argument, basically the assertion is that a corporate executive can unilaterally change the terms under which their users gave them data. That’s exactly what many people are complaining about Facebook doing. What if the FBI is trolling Amazon.com’s user data to see if anyone is buying books that might indicate that they’re a communist? Oh, sorry, the FBI stopped doing that kind of thing in the 1960s, right? They don’t care about communists, anymore, of course – now it’s terrorism and drugs. We’ve seen with Facebook that a company can constantly tweak its privacy policy (which nobody reads anyway) to the point where the policy is: “you have no privacy.”
Summary: perhaps we are trusting corporations too much, and perhaps we are trusting the FBI too much.
On Facebook, I’ve seen images get flagged as “inappropriate” when it’s an image of a plastic model horse. On a Facebook group I’m in, people have had their ads flagged and taken down so many times as “selling live animals” (they are actually selling plastic model horses) that they have to resort to either posting a link, sending people elsewhere to see the ad, or change the wording of the ad such that it’s hard to tell what they’ve got for sale. Sometimes even putting the word “toy” in the ad does not stop the ad being flagged and taken down. Since the algorithm can’t even differentiate between a plastic model horse and a living breathing horse, despite words like “toy” and other giant clues in the ad, why would I trust the algorithm to work properly for other things? I mean, it’s kind of funny when it’s just about plastic model horses, and we all have a laugh at the creativity of some of the authors of the ads for thwarting the algorithm, but it’s not all that hilarious when a human being gets deprived of credit, loses their house, or experiences some other real-life consequence via the same type of mechanism.
Being a suspicious person, I wouldn’t send in my DNA to a genetic testing site. I’d be interested to learn more about my background and any family tree stuff, but I don’t trust that they wouldn’t sell it to insurance companies looking for a way to “reduce risk” by looking for markers of targeted disorders. I hadn’t considered law enforcement apparatus getting a hold of the information. The opportunity for partial or haphazard application of enforcement due to bias is disconcerting. I don’t know that I have any genetic risks and I’m not planning on engaging in serial murder, but trusting corporations and agencies good intentions to look out for my well being is not something I’m interested in doing.
When Facebook first introduced facial recognition it really wasn’t very sophisticated, a friend of mine had a habit of pointing at things with thumb up first finger pointing and the rest curled under – the way you would make a ‘gun’ – and for a while she was marked as appearing in hundreds of pictures where anyone else had made that shape and had any connection at all to her. I know the systems are better now, but one of the things that genuinely concerns me is that not enough markers are used for DNA matching to always be sure you have your person, after all while a million to one match sounds impressive at first glance even in the UK that means there are probably several tens of other people who might match (“and still they come”). The impression given by law enforcement is that a DNA conclusively rules a person in or out, but unless a complete profile is done that is not the case and complete profiles are simply not done for any of the DNA databases we are talking about, it’s still far too expensive.
And I did have another point to make, but it’s gone, I’ll return if it comes back.
David Milgaard is a well known Canadian man who spent 23 years in prison for a murder he didn’t commit. He was eventually exonerated by DNA evidence, but he had a long hard fight just to make the review happen. Why such a fight? Shouldn’t any relevant DNA data be automatically reviewed?
Is it because the system is so overwhelmed with new cases that it can’t divert resources to the review of older, already settled cases? Maybe in part, but I suspect it has more to do with wanting to hide mistakes and keeping up appearances. So what if a few innocent people languish in prison. “They were probably scumbags anyway. Don’t worry, you can totally trust us.”
If I open my cynics eye just a little bit wider, though, it looks like the only thing that really matters is keeping the prisons full and profitable.
It’s happening all the time. And for most people it’s been far more of a fight than it should be.
This is the really scary part. Funny thing, though, it seems to be a USAmerican worry. A lot of privacy laws in Europe don’t allow for the kind of familial searching allowed for here. Which, of course, doesn’t mean that it isn’t happening in some ways, or that people’s data isn’t compromised simply by participating in a commercial DNA test. But the issue is practically non-existent in Europe, even after the capture of the Golden State Killer.
I do wish they’d work harder on exonerations, though.
Jazzlet
I can’t remember your professional specialty, so please forgive me if I’m saying things you already know, but I heard my field calling out to me.
Million to one matches these days are considered poor matches, for the reason that you state. Matches these days are made to the order of 10^15 and higher, 10^21 not being excessive, depending on the system you use and legislation in your home country. What it still means is that this is statistics, and statistics still leaves that chance for a random match, especially when working with human populations (which by their very nature are not always as completely unrelated as the statistics would require). During my time in the lab, we’ve gone from 4 to 6 to 10 now 16 standard loci, with some countries working with 20. And that number will increase, decreasing the random match probability for any given person. There’s ways to discern twins these days, too. (The reason people might be thinking “million to one” is the current limit is because this is kind of the industry standard language: the idea being that, once you get past that million to one, the numbers get so excessively high, you lose a sense of the scale, and the lay-person’s sense of scale maxes out at a million. * This is not my idea and I’m not sure about the entire reasoning behind it, but when I go to seminars about presenting to courts, this is more or less the reason for the “million to one” statements. The actual numbers are quite a bit higher, these days.)
I have to ask what you mean by ‘complete profile’. Do you mean a sequence of the entire genome? Because when talking about DNA profile in the forensic sense, there’s a very specific meaning to both ‘DNA profile’ and ‘complete profile’. Your DNA profile is (most commonly) made up of the selected STR (short tandem repeat) loci, which are small segments of DNA that do not contain personal information (like eye colour, propensity for disease, etc.). A complete profile is the current standard requirement to be considered complete – these days I think it’s at least 10 loci for international data exchange, with variation between countries, because (say) for our database needs, a complete profile is 20 loci, but for casework, 16 is considered complete. If by ‘complete’ you mean whole genome sequencing, then… well, that gets into all the privacy issues.
The idea being that your STR profile is as personal as your fingerprint – it can be used to identify you to some degree of certainty, but it can’t provide private medical information (for example). (And the definition of private information varies from country to country as well, some consider phenotyping to be too private to be used for police purposes, other countries are A-OK with taking a guess at ancestry to help an investigation along.) Commercial DNA tests for ancestry and other fun have to use private information by definition, otherwise they can tell you nothing about yourself or your diseases – they specifically examine the parts of your DNA that provide actual functional information, the complete opposite of what STRs do.
Current technologies also work with SNPs (single nucleotide polymorphisms) which are pretty incredibly tiny things to work with, but these get more personal; and then there’s the new MPS (multiple parallel sequencing), which is brand new and expensive and not just a little bit scary. And as it is currently developing, there is a lot of internal discussion about privacy, public trust, utility, and cost. Not sure where it will end up yet, but if the chemistry used to develop an STR profile simply couldn’t/can’t do any more than develop that STR profile (it’s the way all the thingies work), then with MPS, it’s a completely different story because you can do anything with only minor adjustments.
I could go on.
rq
Thank you, I have a biological sciences degree from more than thirty years ago, but I have tried to keep up with the basics. My intake of drugs doesn’t always help me communicate accurately, particularly when it comes to using the right nouns – I wonder if anyone has done any work on which kinds of words people ‘lose’ under different circumstances? – anyway I meant the number of loci used in an STR profile. I didn’t know there was that much variation in what number of loci were considered to provide an adequate STR profile and I hadn’t realised SNPs were being used in law enforcement work, let alone MPS … thanks for filling in some bits and reminding me of the proper nouns!
Maybe I’m even slower than usual today, but I don’t get the point. It sounds just like “guilt by association” which I dimly recall to be a bad idea. The warrant requirement mentioned is all very well but I vaguely suspect that’s what rubber stamps with integrated ink pads were made for. This post certainly doesn’t inspire any positive thinking with resepect to US law enforcement.
—
Regarding deep learning and facial recognition:
I while back I attended a presentation about reverse-engineering neural networks to figure out how they arrived at their conclusions. It seems algorithms / networks can frequently latch on to the wrong features without anyone noticing. One example I remember was a test-set of images where the objective was to identify horses. After careful analysis it turned out one network didn’t acutally pick up very many “horse-like” features, but instead was looking for a copyright stamp that happened to be included on every photo with an actual a horse in it.
While this (or the gun-fingers mentioned above) is at first glance an issue with poor training data it shows that you really need to be able to work out where the results came from. If you can’t verify an algorithm you’re basically gambling that it either works perfectly or will fail in an obvious manner as soon as you start using it.