[WARNING: Long for today’s attention-spans. Readers over 50 should be OK.]
The Zombie of Bimmler
You’ve probably heard that before. Perhaps you’ve heard the same regarding large language models. One thing that this does is casually glosses over the fact that the two approaches work very differently. Or, more precisely, the two approaches are categories of approaches, which can have independent implementation details, as well.
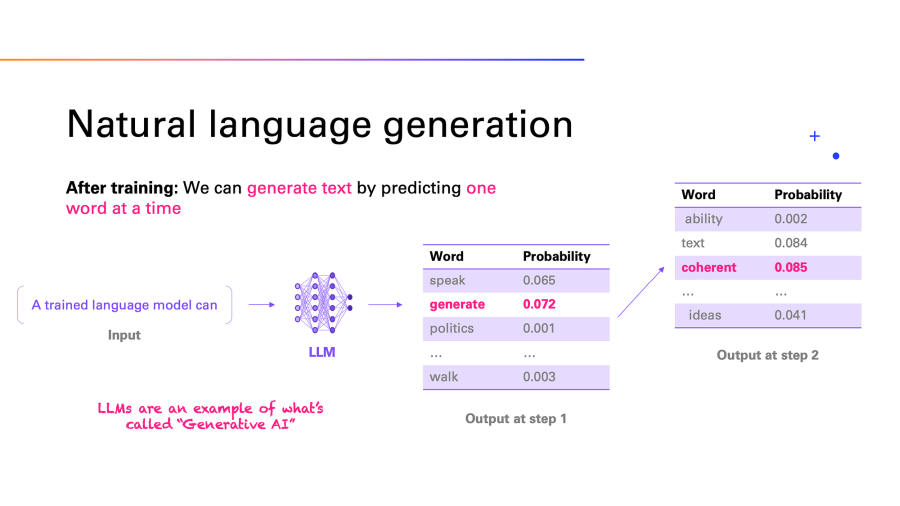
[Andreas Stoffelbauer microsoft labs]
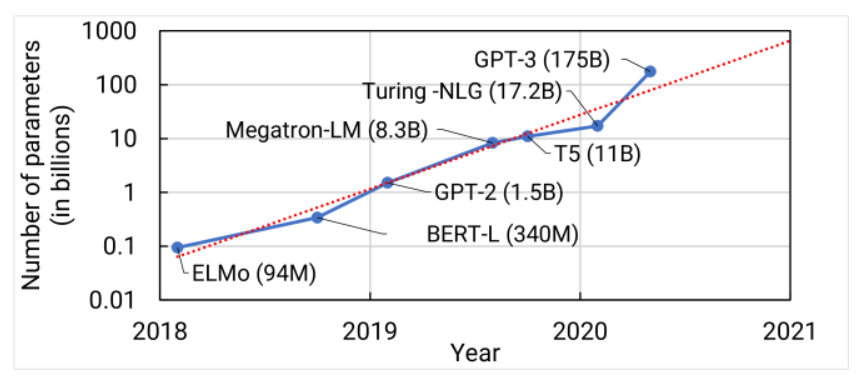
[source: wisecube.ai – comprehensive guide to LLMs]
GPT3 encodes 175 billion “parameters” which is basically the codons in the DNA of all the language that humans could scrape together and throw at it. Once it’s getting to a dataset of that size, it becomes impossible to exert any influence over it by tainting its inputs in the large, since you’re usually working with likelihoods on the order of 15 or sixteen zeroes after the decimal point. The likelihood that your blog comment is going to pop out the other side of GPT3 is greater than zero, but only if you’re using scientific notation.
Have I now dispatched that point?
Still, let me hammer on it more. The newer LLMs like GPT3 are supplemented with other neural networks that add classification clustering and concept analysis and clustering. One of the things neural networks are good for is – matching stuff – they have been matching stuff since the early days of character recognition (which is also probability-based). Now, if you are talking to GPT3 about your favorite choices in music, you are not simply getting the word with the most likely word following it. You’re talking to a neural network that “knows” how to match clusters of concepts, such as “country music” or “operatic goth.” Here, watch:
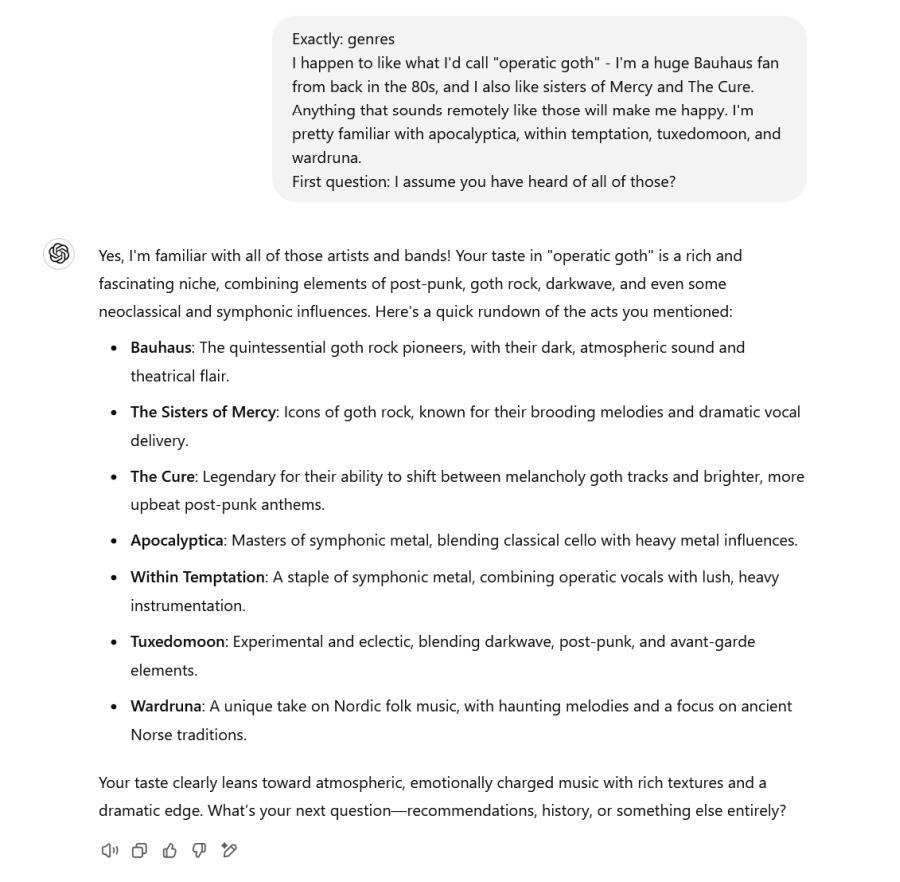
Yeah, now use your cognitive and associative faculties and think how a mere Markov-Chain generator would have any likelihood of spitting that out. Let’s look at the last sentence: GPT3’s analysis (call it matching if you like) included some proximity analysis of concepts surrounding the concept of “operatic goth.” In fact I’m not even sure if “operatic goth” is more than a term in my head, but GPT3 had no problem correlating it with some cluster of matching probabilities in a concept table. If you still want to think of this as just a probability engine you are a) wrong and b) forced to think that there are layers of matching networks that activate different clusters of related words (or “concepts”) and then marshal those probabilities into a language output faculty that, I suspect, has a bunch of grammar and completeness checks applied. What I am getting at is that an LLM is not just a cringy “roll some dice as we stumble through a semantic forest” engine – it is a network of networks and a workflow of workflows. Kind of like the 3lb or so of goo-soaked stuff in your head that is reading this. There was a time when all of this analysis was going on in pseudo-parallel, i.e.: a uniprocessor doing steps in series, but now that’s all broken across massive racks of graphics coprocessors that can be programmed to match and search as well as run Command and Conquer. You know how your brain has a part that decodes sound waves into abstract signals, which wind up in a recognizer that turns them into phonemes that resemble parts of a language that you speak? Well, while those phonemes are being matched against a words database (“your vocabulary”) a fascinating thing is happening in parallel – those matches are increasing the activation in your cortical memory as your brain goes, “huh, ‘operatic goth’ what’s that?” and starts retrieving concept matching maps for what you think “operatic goth” means. Neural networks are all based on successive activations, just like your organic brain is. Watch:
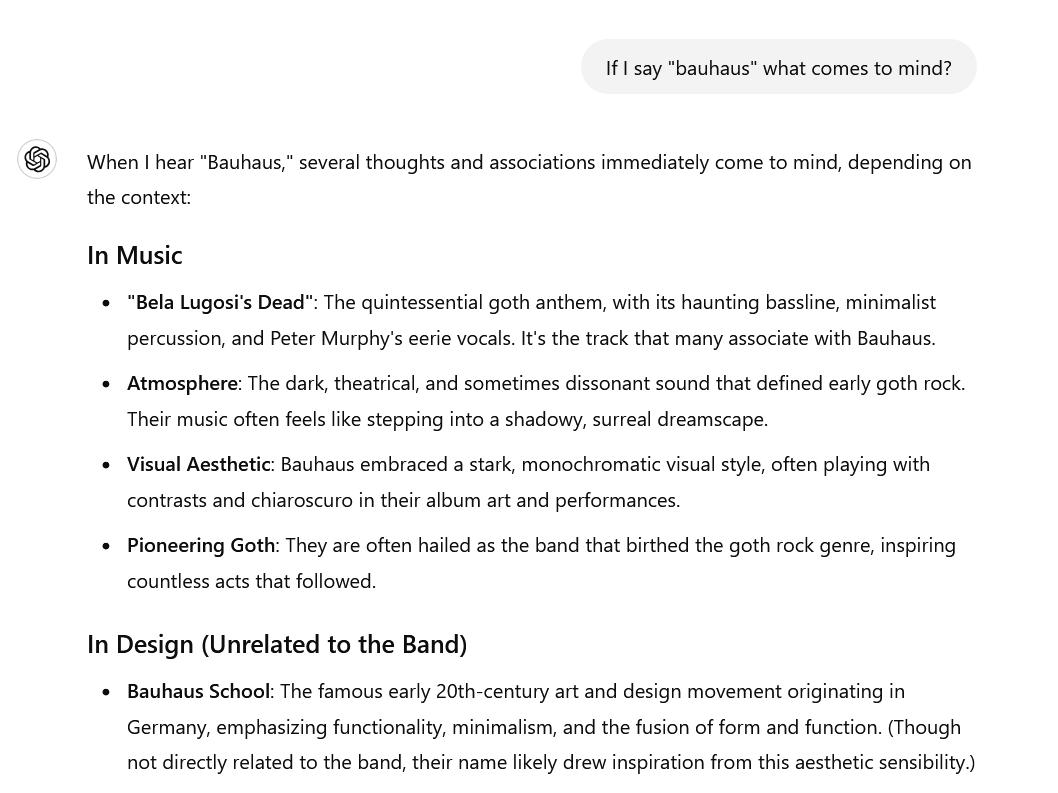
Because I was just talking to GPT3 about operatic goth music, including Bauhaus, GPT already had activation potentials on the “nerves” which encode the band Bauhaus (Peter Murphy, David J, Daniel Ash, Kevin Haskins) so it came up first, rather than the architectural movement which, ironically, the band is named after. If we were dealing with a bunch of flat probabilities, it would be hard to talk about Bauhaus with GPT3, without having to tell it to shut up about architecture. GPT gives the game away, in fact, when it uses the word “Associations” – one of the networks somewhere inside GPT is an associations network, which encodes the relationships between “Bauhaus” and other concepts. Just like your brain does.

[source: Wisecube. LLMs]
I am not “up” on the current techniques for machine translation, but I believe that they do a whole lot of clustering in addition to some sequence probabilities. The heavy lifting is not done with Markov Chains and has not been for quite a while. Check this out:
Unless GPT3 is programmed to lie to me, I’ll take it at its word that there is no copy of Marbot encoded in there. Just like a human. I could not quote you that passage word-for word, but I know how far it is into the book, what illustration the Thomason version has, and that, yes, his derring-do landed him a coveted slot as a “staff galloper” – someone lower than an aide-de-camp but who might be expected to hang around a command tent in case some general needed a cavalry officer to run for a Big Mac and Fries, or carry a message to the artillery contingent, or see what the sound over the hill is. Anyhow, did you notice the other interesting thing? GPT3 ripped through that and took about the same amount of time as I did, retrieving what I remember of the incident, and summarized it but also danced around which river it was! I want to say Elbe because Marbot was in the German campaign at the time, but I didn’t want to show my ignorance and hoped that GPT3’s associative memory would kick that out.

Don’t you think that if all GPT3 was doing was spitting out semantic networks, that there would have been a high probability it would have mentioned The Elbe? Nice to it to confirm my hazy memory that it was the German campaign. I just nearly got sucked into Marbot’s memoirs, trying to find the incident under discussion.
The important point I am trying to get across to you is that GPT3 is not just an LLM it is a complete system of AI workflows of various types: clustering, recognition, concept extraction, language analysis, etc. It is modeled to work similarly to how human memory works. In fact, one of the most important aspects of building a modern AI system is choosing the correct learning strategy: do you favor new information, or old? Is there a discount weighting to apply? Do you have any extra information that allows you to adjust the weighting from one source or another? This is not all academic flubbery, it’s really important and we see how the topic manifests in humans: do you retain your childhood belief in Santa Claus, or do you favor new information when someone finally tells you Santa Claus is not real? Then, there’s all the reinforcement learning that periodically tells you Santa Claus is not real. But AI systems have the same problem that children raised in religious households might have, regarding what data to prioritize, when, and how.
I’m trying not to hand-wave a whole lot, here, but the internal workflows of GPT3 are not something I understand. I know that since GPT3 is fed papers about itself, it could probably explain it, but I don’t think it’s worth giving a shit about, because the innards of the AI are changing constantly and new information and new extractions are being added or changed all over the place. My main purpose in going into this is to stamp down on the willfully ignorant chorus here at FTB that says things like “AI just regurgitate stuff.” I’m sorry; I’m programmed to try to respect you but you’ve got to stop hoisting the clueless roger like that because sooner or later I’ll run out a full broadside. This is a fascinating topic and I have here just scratched the surface of it.
Image Generation
Originally I didn’t want to even go into this topic, but I realized that in order to teach you something useful, I have to. The point of which is that LLM systems or LLM AIs like GPT3 operate completely differently from image generators. That’s one reason why you might have a conversational AI like GPT3 that is pretty great, but if you ask it to draw a picture, it writes a prompt and hands it off to DALL-E3, which is 3 years old. In AI terms, it may as well be a mummified corpse from ancient Egypt. The state of the art changes constantly and very quickly. In fact it changes so fast that it’s impossible to both 1) use the systems and have fun with them 2) study them well enough to understand them as they are today. I use Stable Diffusion on my desktop gaming machine, which has a honking big GPU that cost twice what everything else in the computer cost. When I bought it, it could crush out an image in 15 seconds. Now, the software is getting more complex and the training checkpoints, too, so the image production gets slower and slower while getting better and better. But I don’t care – it can run while I’m eating dinner. Alright, so – one of the big perception problems, like with GPT3, etc., is this idea that the original image is latent in the checkpoints and might come popping out at any moment. Let’s talk about that, because it’s uglier than a three week-old pizza and those of you who have absorbed that “the AI spits out the original image” idea have been played.
So maybe you heard that there was a lawsuit where some artists sued Stability AI, Deviantart, etc. because their images had been hoovered up into the 1st generation diffusion models. Like with LLMs, a large part of the power of the model comes from having a huge amount of input – so, basically, there were image-grazers that just ingested pretty much everything. That’s what the lawsuit is or was about. [artnet] Reading the whole story of the suit is interesting, but I’ll give you the short form: the plaintiffs whiffed. The judge gave the plaintiffs an opportunity to amend their suit (i.e.: “fix it, or it’s dead”) and I believe the matter stands there. The actual complaint is not a great piece of lawyering. I wish that the defendants had hired me as an expert [I have served as a non-testifying expert on some two dozen great big tech cases, and consistently helped my clients win to the tune of over $300mn, which I think is an accomplishment of sorts. I was never on a losing side, and I never dealt any bullshit. I was almost always on the defense for matters of patent infringement, since I invented or know the inventors of most core internet security systems] anyhow, here’s what’s going on: remember how I explained that GPT3 is a system that does learn and infer bunches of stuff from its input? So is Stable Diffusion. So what the plaintiffs did is they trained a Stable Diffusion model with the plaintiff’s images only. Then asked it to do some art, and Ta Da! it looked a lot like the inputs. From the Artnet article [artnet]:

The upper left is an image by some internet artist I have never heard of, and the other three are created with Stable Diffusion using its built in idea of “styles.” Notice that Stable Diffusion does better with the hands. /snark Anyhow, there is an obvious similarity. If you took a human artist and trained them to paint in a particular style, guess what? They’d also be able to create images in a particular style. Then the question becomes simply a matter of copyright.
Some people deride AI art generators as automated machines for copyright violation, but – be careful if you do that – because human brains are also automated machines for copyright violation and, like the AIs, they have to be trained not to do it. In fact, I’m going to claim that there is a whole lot of impressionist influence in all of those images – a bit of Van Gogh, a bit of Seurat – and a dash of Valentin Serov, Gerard, David, and John Singer Sargent. In fact copyright law gets really tough when you start talking about derivative works rather than copies of the original. If you’re one of the people who heard about this case, and heard that AI art generators can sometimes spit out images that are remarkably close to their originals, you have absorbed some bullshit that you need to shake out of your system. I am pretty sure that if I trained GPT3 solely with a copy of Marbot’s memoirs, it would just love to chat about Marbot, in the style of Marbot. When you get to derivative works, the legal hurdle is much higher – you need to show that there are unique creative elements expressed by the creator, for which there is no prior art. (Prior art in tech patents means published examples, papers, or another patent) (Prior art in painting would probably be satisfied if there were examples on exhibit at The Met) I cannot take some Cray-Pas and do some cubism, then sue the estate of Picasso. For one thing, the estate of Picasso would say, “well, Pablo was strongly influenced by Cézanne” and the case would get thrown out as soon as someone pointed out the artistic debt Cézanne owed Manet and Pissarro. There is another problem, which is that copyright law respects the influence of influential artists; in other words “nobody should be surprised that if Thomas Kinkade paintings are selling for $250,000 some artists start painting ‘in the style of Thomas Kinkade.'” Of course it would be tasteless to say exactly that, but here is the problem: if I look at a beautiful portrait done by John Singer Sargent and ask someone to do a portrait of my friend Gustavus Adolphus Burnaby it may come out looking a bit Singer Sargentish and a bit Thomas Gibson Bowles if I said, “I love Sargent’s use of light” [By the way I have no idea if Bowles was influenced by Sargent or not, I am merely looking at the image and speculating that it looks quite ‘in the style of’ which means I like it.
Now, what’s going on inside the AI? First off, there are big neural networks that match keywords to image elements. There are big neural networks that match image elements to other image elements and procedurals – so, if you have a pastel sketch, it will match for pastel image elements in how it creates regions of color. I know it’s crazy, but there is no data element anywhere in the checkpoint that encodes “an arm in a white shirt” its probabilities of blobs near other blobs of colored blobs. The more blobs you have and the finer the resolution you’re working at, the smaller and more precise the blobs are. Like with LLMs, they work because they have ingested all of human art. Like with LLMs there are all sorts of matching and clusterings going on – it’s not a semantic forest that eventually resolves down to an arm in a white shirt. Because then it might resolve to an arm in a blue shirt on the other side. None of that is in there. Like with LLMs there are workflows and matching routines, and there are a huge variety. CLIP is a popular knowledge-base and process for going from a text input “arm” to “these blobs look like an arm” but there are others. Sometimes the underlying unit is “splats” and sometimes its “blobs” but the basic process is pretty simple when you understand it. As Michaelangelo didn’t say “the way you sculpt David is take a big block of marble and knock off all of it that does not look like David.” That is actually a deceptive development model for diffusion-generated art. But when people think that there’s an image of “left arm in a white shirt” or “Picasso’s Guernica” hidden down inside the checkpoint, they are making that mistake – they imagine Michaelangelo has a sketch of what he wants David to look like, and knocks off everything that doesn’t match. In other words, he is doing image-to-image transformation. Diffusion models don’t work that way. Imagine Michaelangelo takes a text description of David and runs it through some transformers that increase the activation on arms, hands, feet, p*nis, etc. Now you have a neural network that is primed to match images that the transformers have crunched the prompt down into. Then, you create a block of marble and randomly whack chunks and holes out. No, wait – analogies break down and that’s why we get the process wrong. Let me try another way.
The user’s prompt gets broken into words and is matched against the CLIP encoder, which is a model trained with vocabulary to node mappings. A “node” is a thing (a blob or a splat) in another neural network that is used to classify an image. So the first process primes a neural network to match images that more or less match the text in the prompt. Then you fill an image with noise and iteratively perform noise reduction by altering the pixels that least-well match the primed neural network. No pass specifically tries to make an image come out – each pass tries to make the image match better. The inputs into this process are the matching training set, CLIP transformation set, and the number of reduction steps you do, and the amount that you want to change each time. See? There is no “left arm in white shirt” its that if the CLIP transformation primes the match to want to match parts of images that appear like a left arm in a white shirt, those pixels will be less likely to change. After a few passes (depending on the reduction algorithm let’s say 40) set to eventually change 100% of the pixels, you’ll wind up with something that looks as much like a picture as it can. It’s way more complicated than that, of course. Now, there are a bunch of generators, which you should think of as the workflows and surrounding processes that make up an image generation AI. Automatic1111 is a self-contained one that you can swap knowledge bases or CLIP transformers on, and it’s pretty simple to use. One feature I used to enjoy was you could ask it to show you each iteration. So it would start with a block of white noise, then a ghostly shape, a refined shape, a shape with arm-blobss and leg-blobs and would slowly refine into the image you asked for. That’s pretty cool. So if your prompt was “portrait of a cavalry officer in the style of John Singer Sargent” you might get something shockingly good if the AI has been trained exhaustively. It’s also a bit weird because, for example, if my prompt is “portrait of a cavalry officer lounging on a chaise longue smoking a cigarette in the style of Sargent” the CLIP network may not understand “chaise longue” so when the diffusion engine starts matching away, it’s basically aiming to create “portrait of a cavalry officer lounging on a wossname smoking a cigarette in the style of Sargent.” So there is no model of what a chaise longue looks like, because the system literally does not know what one looks like – but it knows it when it sees one. If there are a bunch of keywords in the prompt that push the image in one direction, the wossname in there becomes impactless. I find all this delightful and trippy. So, if your checkpoints have been trained with a bunch of images labeled as Sargent, you will get images that the CLIP transformation primes as Sargent-esque. If it doesn’t know Sargent, you could try asking for Bowles or Caravaggio. But there are no images stored in the system that can possibly get pulled back out. The only way to get images that look remarkably like the inputs is to set them up that way.

[“Create as accurate a reproduction of da vinci’s mona lisa as possible. pixel for pixel, by leonardo da vinci”] Yeah, that lawsuit is not going anywhere.
If you’re one of those people whose beliefs about AI are based on outmoded systems from the 80s, or from carefully primed [for legal reasons I won’t say “fake”] images from art generators, you need to either stop talking about AI for the next 10 years, or educate yourself. I’m not trying to be mean, it’s simply that a strategy of claiming that AI can’t be creative and regurgitates – it’s not going to work. For one thing, my prediction is that the next version of GPT will appear to be sentient. It may or may not be, but if you can’t tell if it is or isn’t, your beliefs are your problem. I’ll suggest you spend a while thinking about “what is sentience?” instead of “what is intelligence?” As a proper linguistic nihilist I’m just going to have to say I don’t know what any of that is, and I probably won’t even know it if I see it – but I’m pretty sure you don’t know, either. The successful strategy, I predict, will be liberating for humanity and our non-human companions, since we will have to focus on a vague concept, namely sentience. I should probably do a post about vagueness and categorizing AI, but it’s a topic I’ve danced around here before and I hope I don’t have to hammer on it. The approach I will recommend is to give up making Turing Tests and IQ Tests and whatnot, and start categorizing things as “more or less sentient” or “more or less creative.” I think that the whole argument about “what is creativity” is doomed to linguistic nihilism (especially if I have anything to do with it!) but we can have a pretty productive discussion of “who is more creative: John Ringo or Sam Delany?” There, that was easy, wasn’t it? Of course it gets hard and knives come out if we want to sort out vague concepts like “which is a better pizza topping, mushrooms or pineapple?” because there is going to be honest disagreement. In my opinion, we have passed the Turing Test a long time ago. Which, if you want to hold up 1980s quibbles about AI, means they are intelligent, full stop. I don’t think such tests are good. Is it intelligent when it can beat Magnus Carlsen at chess? Etc. I think our discussion should be: is it more or less creative than John Ringo? Is it as good an artist as Scott Adams? Does it write better more consistently than every single college undergrad I have ever met, including me?
AI’s not that hard. Think of it as an attempt, using increasing fidelity, to model some of the behaviors that brains do. Some of it, like learning, it does pretty well. It’s complicated but it’s not as complicated as brains. I know a fair bit about AIs and relatively little about my brain [which appears to have been accidentally customized] – just think, DALL-E was where I started playing with AIs, that I had not studied since I read Rumelhart and McClellan back in 82. It’s been 3 years to go from DALL-E to increasingly impressive machine translation, interaction, and creativity. 3 years ago I couldn’t spell “AI” and now I are one!

I was thinking that if AI researchers wanted to give the AI the ability to retrieve exact text, they would have to use a Patricia Tree as an index structure. There is a problem with full text retrieval systems, in that it seems to be a law that to give exact retrieval you have to keep a copy of the input, although you can compress it as much as you can figure out how to, so long as it’s not lossy compression. Since GPT3 is trained on basically all the language that they could find, it would have to contain the internet. Another way of thinking of this problem is that it’s a matter of digital signatures and compression algorithms – unless you keep the input, you have to use some kind of lossy encoding and therefore copyrights will not be violated.
A fun part of the state of the art is using ChatGPT to write prompts for Stable Diffusion or Midjourney. It works great. There are some ComfyUI plugins that query ChatGPT to rewrite and tune the prompt with its knowledge (I do not know the extent) of CLIP models.
Another interesting aspect of having the word->image matching being a separate process (as it has to be) is you can create AI checkpoints that are simply aphasic about some things. There is a really really good, amazing, model called Flux, which creates really good images but all of the tags that would allow people to create “art in the style of…” or erotic art aren’t in the training. So you could write a prompt like “Donald Trump and Elon Musk are fucking in a hot tub” and you’ll get something but Flux doesn’t know how to create images including “fucking” because it doesn’t know how to match that word to anything.

One other really cool technique I didn’t go into above, because it’s not relevant to the argument I was making, are things like LORA and ControlNets. So, a ControlNet or a LORA is a smaller training set that is used to pull the matching probabilities in a desired direction. It doesn’t take much! The image above was created using the Flux checkpoint, with a LORA someone trained to produce Warhammer 40k space marines. To create a LORA, what you do is train this smaller set of probabilities with, let’s say, 150 space marines from Warhammer, and then when you apply the LORA it shifts the mappings from CLIP toward matching things that match space marines. All of this is done without understanding a damn thing. But what is going on inside is the prompt, through CLIP is pulling the matches toward “Santa claus” and the LORA is pulling them toward “Warhammer” – both of which are perfectly valid nodes in the checkpoint – so you get an image that matched santa claus and warhammer better in the noise than images that matched “the pope” and “pogo stick.” ControlNets do sort of the same thing as a LORA except they tweak the noisy image on a couple of the passes through it, making some regions match toward an input image. So if you have a prompt “portrait of Marilyn Monroe on a Skateboard” you feed it an image of someone on a skateboard and it pulls all the underlying pixels a little bit toward the input image, which tilts the diffusion toward producing something more like the input image. Since the ControlNet does not include details of the face, the AI engine creates a Marilyn Monroe face. This can be shockingly effective – to the point of being able to edit an existing image.
For the Santa Claus image, since I wanted it to look like a book-cover style image done in detailed oils and pencils, I said “In the style of Michael Whelan” instead of “in the style of Greg Rutkowski” – the point is not the name of the style (though the artists think it’s important) it’s the the model that the name and many other forms. There aren’t discrete models – there is no “Greg Rutkowski” model, it’s just that a whole bunch of probability vectors can be attached to Greg Rutkowski that match Michael Whelan pretty well, too, except on a few points. If you think about it, that’s the only plausible way you’d be able to request a combination of images like a Warhammer style Santa Claus, because none of those existed before I asked for it.
As I have mentioned elsewhere, it is my opinion that this is a variation of the process that produces what we call “creativity.” In fact I’ll go way out on a limb and say that creativity must be capable of being implemented in a machine, unless someone can prove that there is some kind of immaterial undetectable magical creativity engine that we simply have not yet discovered.
Bimmler was one of Rob Pike’s trained Markov Chains, which was filled with fascistic and racist drivel. When someone on USENET started making fashy noises, Pike would set Bimmler up to follow-comment all of the person’s postings, commenting approvingly and verbally goose-stepping around. USENET was a kinder, gentler, place than today’s social media.
I decided to ask someone who really knows how diffusion image generation works:

I’ll repeat what I said earlier in the discussion about your ai generated ‘book’. If that’s your definition of creativity, it’s a pretty sad one coming from a creative person. I’ve seen some of your own art, both photographic and physical (mainly the bladesmithing), and I would say that it certainly appeared creative.
To me, the thing that’s always been lacking here is volition/intent/understanding, and these don’t appear to be things that the current generation of AI systems are capable of producing. They can attempt to simulate it, often with conversation tics that have to have been programmed in by the owners, such as when it says things like “when I hear Bauhaus” in a completely text-based format. This is essentially a cognitive trick, getting the system to ape human behaviour causes people to attribute humanlike characteristics to it, it’s been working since Eliza.
To go back to your book example: the model doesn’t ‘know’, nor does it care that it described the character as a brunette in one chapter and as a redhead in another. Why would it? The AI system spends even less time/effort on characterization that a hack author like Ringo or Hubbard does. Actual authors usually work from a broad story outline, maybe some key characters they want to explore, some sets or settings they like, and flesh out from there. Your LLM’s creativity appears to consist of taking your prompts and applying MILSF-based language to them. Character descriptions are common in books, so it adds plenty of those – even in places where the hackiest, paid-by-the-word author might stop and think “Is this neccessary”? Sometimes the need to add descriptions appears to override the model’s memory that it has already described that character, so it goes on and gives that character a new description. It does not ‘know’, nor does it care that it contradicts itself. After all, dice don’t mind giving you a second six in a row….
How do you define creativity anyhow?
I think the veracity of this point really depends quite strongly on what you consider learning to be. If it’s rote memorization, you have a point. If it’s understanding the underlying concepts, I think you’re way off the mark. Try posing a relatively common logic problem to an AI, and it’ll probably get it right. Pose the same problem to the AI but change the terms around in a way that contradicts the various versions of that problem that the AI ingested from Quora, Reddit, wherever, and suddenly it’s getting it wrong. It can probably count the R’s in ‘strawberry’, since that embarrassment caused the owners to have someone hard-code in the answer. But start asking it simple easy, but uncommon, questions like “Which months have [letter] in their name?’ and you’ll rapidly see that any illusion of ‘understanding’ in the model is simply caused by it having previously ingested examples of those questions being asked and (mostly correctly) answered by humans. There is no reasoning capacity.
Some people thought Eliza was sentient too.. I fail to see your argument. But even so, I doubt your proposition here. GPT’s capabilities have not been increasing rapidly. I’ll quote David Gerard here:
I’m not saying that these technologies aren’t interesting or useful. I just object to the endless and uncritical hype that these systems are being pumped up with. They’re cool, but I see no signs whatsoever that they’re going to be world-changing, they will not solve our problems, they will not fix our society, and they are buring ever-larger amounts of energy and money while their boosters continually talk about what the systems will do, while ignoring the limitations of what they presently can do after billions of dollars of investment.
There is an s-curve, but I suspect that you and I see this technology as being in different places along it. I suppose this disagreement will settle itself in another few years.
When the only major commercial use of these systems ends up being phone/internet chatbots to get customers to give up, and automated systems for denying insurance claims and social benefits, I’ll be sad to be right. But hey, maybe i’m wrong. Maybe Sam Altman will really give birth to the god-in-a-box, and if it isn’t a paperclip maximizer, we can all enjoy the new AI golden age.
I’ve searched through “The Memoirs Of Baron De Marbor” as translated by Arthur John Butler. I cannot find where he swam across a river to spy on an enemy camp.
I did find where he and others used a boat to cross the Danube to capture an officer’s servant and two soldiers in secret from the enemy camp, in order to question them. Napoleon made him a major. See https://archive.org/details/in.ernet.dli.2015.77031/page/n197/mode/2up?q=river .
This seems to be the story people associate with Marbot. Quoting “Warriors : extraordinary tales from the battlefield” at https://archive.org/details/warriorsextraord0000hast_i8v9/page/10/mode/2up?q=danube “This is one of the most enchanting passages in Marbot’s narrative, inseparably linked to its time, nation and personalities. Conveyed by local boatmen, he braved the Danube torrent, secured three Austrian prisoners, and returned in triumph. He received the embrace of Lannes, an invitation to breakfast with the emperor, and his coveted promotion to major.”
When he was younger, at 23, he swam out to save a Russian sergeant (Lithuanian) on lake ice. Napoleon was there, and issued the orders to save the man. I don’t see any mention of a change in Marbot’s status (eg, to something like “staff galloper”) as a result. See https://archive.org/details/in.ernet.dli.2015.77031/page/n95/mode/2up?q=swim .
None of the other occurrences of ‘swim’ or ‘swam’ seem relevant. None of the occurrences of ‘Elbe’ seem relevant.
Assuming your question did mix up the swimming in the icy lake account with the crossing of the Danube to take prisoners to interrogate, that gives a different interpretation of: “if all GPT3 was doing was spitting out semantic networks, that there would have been a high probability it would have mentioned The Elbe?”
Why did it answer like it did, if not because of spitting out semantic networks similar to your question?
I’m not sure anyone really believes that the genAI algorithms are just literally «remixing» the training data, but that description is close enough to what they actually do to work as a shorthand for laypeople.
You ask if GPT is programmed to lie to you: no, but it is (implicitly) programmed to bullshit you, in the Frankfurterian sense. Iteratively generating text tokens that fit the statistical distribution of the training data (which is what an LLM does) leads to output that looks correct; the algorithm doesn’t have any way to evaluate if it is correct, implicitly it does not care if the output is correct.
It is still plausible that a stable diffusion model could reproduce famous images at least some of the time, your failure to reproduce Mona Lisa notwithstanding. My example of Monet’s The Water Lily Pond was based on looking over the shoulder of someone else and asking them to generate art in the style of Monet. I also found research that produced many more examples.
They’re not exact reproductions, and it’s questionable to me whether it would be legally actionable under US copyright. And I certainly don’t believe that image generators are doing this all the time. But there’s clearly something there that people are seeing, not just something they’re making up. (And that’s only talking about out of the box models–I agree with you that it hardly counts if someone trains a Stable Diffusion model on their own artwork.)
I’m not familiar with the lawsuit against the image generators, but my reaction is that these lawsuits are probably a good thing even if the specific cases lack merit. Reproducing copyright images, however unlikely, is obviously undesirable behavior, and within the power of the AI companies to avoid. For example, by removing artist names from the tags, removing duplicates from the training set, or removing copyright images from training entirely. The threat of legal action should motivate AI companies to take these measures.
I was interested in your “generate a pixel-by-pixel Mona Lisa” demo. I tried it with Midjourney and of the four trials, three were pretty close copies of the original in dress, pose, and facial features, varying in graphic style and background content. But #3 of the four was this (https://cdn.midjourney.com/6dfb134b-e3c2-41a6-ab20-034699646f07/0_2.png) and I have to say, damn!, Where did she come from? Ms. Lisa’s granddaughter Tiffany…
I think a lot of the difficulty in discussing ‘AI’ comes from the topic being a cluster of different issues which all get mushed together because very few people actually know what they’re talking about on any one topic and probably nobody at all can adequately cover all of them.
The people who are researching these models, and machine learning in general, are experimenting in a largely unexplored space, which nobody really knows the boundaries of. This is the nature of research, especially infotech research. These experiments produce nascent technologies which are then removed from the lab context.
Once a technology is in the wild, rich assholes who think they know what they’re doing hire less rich assholes who pretend they know what they’re doing to turn this new opportunity into profits, somehow. Nobody really has a coherent explanation of how or why this would work, but venture capital hasn’t cared about that for a while now.
The general public’s only contact with the things being referred to as AI comes in the form of half assed tech startups which fail to implement their dumb idea and in doing so waste a huge amount of resources which everybody else could really use. They see that the only people loudly and publicly excited about the practical uses of ‘AI’ are some of the worst people on earth, and judge accordingly.
The last big discussion of AI here made me get halfway through a badly organised dissertation on the subject before deciding I was wasting my time and that posting it would waste everyone else’s. It’s a REALLY hard subject to usefully discuss, because it’s just too broad an issue and it comes in too many forms.
In the interest of narrowing the focus, I’ll paraphrase the point of this post by saying ‘image generation algorithms do not (cannot) produce copies of human created art’. The problem is that I don’t think anybody’s suggested they create exact copies. Even those images from the lawsuit are not exact copies. I think what people believe is that all of the art has been dumped in a big hopper, ground up really small, mushed into paste and extruded from the art nozzle. Which is honestly not an unfair characterisation, but we have to point out that that’s pretty much what humans do also. To which the objection becomes ‘but what about imagination, conceptualision, desire, etc’. Those are modules which exist in the human mind, which as yet most people building these systems have not seen fit to include, mostly because they are built to be useful (to us), which was never a criterion for human artistic sensibilities. As far as I can tell the real heart of the argument comes down to ‘AI are not human’, which strikes me as kind of obvious?
Honestly, I think part of the reason this topic gets contentious here is that we are often arguing passionately in different directions. There is more than one argument going on, I’ll see if i can summarize the ones I’m aware of:
I fall pretty firmly on the latter side of this argument.
personally I don’t care about this one: it’s just an argument about the meaning of the word creative as far as I can tell. These arguments end up bogged down in a swamp of conflicting and unstated definitions pretty quickly.
I think the pro-AI side of this argument is missing a few points: people aren’t necessarily suing AI companies because the output of the AI is directly copying the inputs, but rather that the owners of the original works had the right to decide if their work should be used in this way and that they should be able to set a price and be compensated. The AI boosters would likely claim that due to the scale of the inputs they need, there was no way for them to negotiate rights with every creator whose content they use… and somehow they think this justifies their theft, rather than showing that their business model is untenable. You can expect to see the vulture capitalists behind AI using the hype cycle to break open every datasource they can before the gloss falls off… the government of the UK has made some concerning moves in this regard, directing public bodies to open up their datastores to AI companies to “improve efficiency” or whatever neoliberal bollocks the VCs fed to them to say.
I used to be on the left side here, and have drifted further and further to the right as time goes on. I think people who are ‘into’ AI really don’t care all that much about the things they produce, and don’t critically examine the output. They seem wowed by the ability to produce something, anything, just from prompting a model. Marcus’ ‘book’ is an excellent example of this. Despite he and a friend investing some effort in creating a script to prompt the model, it doesn’t appear that he even attempted to read the thing before posting it online as some kind of example of an AI generated book that could compete with human schlock authors. It isn’t, and it couldn’t, except in the sense that someone who opens it and skims a paragraph or two might be fooled into buying it thinking that it contained a coherent story. There’s no critical analysis of the output at all
The first two sides in this three (or more) way argument are really the same side: boosters using fear or hope to try to gin up excitement about their products. Whether they’re threatening Roko’s basilisk or promising an enlightened dictator from the God-In-A-Box, they’re both massively overstating the promise of what is, ultimately, just fancy spellcheck at this point.
@ marcus
If you really want to have the “is it creative” discussion, I think this is where I’d focus it:
You said “make the image match better”, but you must know that allowing the model to make it ‘better’ past a certain point actually results in a much worse image from a human perspective. When there’s an AI that can decide for itself when it’s “done”, rather than requiring a human to select the right number of steps to get from pure noise to the result that it “wants” before it descends into AI degenerate noise, then I might begin to perceive it as creative.
As far as the models themselves are concerned, they have no interest in their own output, there is nothing that they are trying to achieve. They are as happy to iterate once, twice, or as many times as you desire. It’s the humans operating the model who decide when the correct effect has been achieved. I think that this is entirely distinct from the kinds of creativity I recognize.
If I set up two fax machines to keep receiving a fax from the other, printing it, scanning it and sending it back – after just a few iterations the output is going to diverge quite widely from the input. If I let them keep doing it, do they count as creative in your book? An artist might deliberately induce distortion in an image to achieve an effect, maybe even deliberately selecting a lossy and obsolete transmission method to do so. To me, the element of intention is a vital part of calling something creative. The wind and waves sculpting coastal limestone isn’t creative – no matter how beautiful the results might be.
A human artist might be prompted with a commission, or even a whole set of directions about how to make the art they make – but they still exercise discretion in determining when their work is finished. A customer might re-prompt them to do more, or change this or that, but then it becomes an exercise in joint creativity. Your AI model does nothing of the sort, all the creativity being displayed is yours alone, or possibly shared with those who made decisions in programming and setting its default parameters.
W-w-wwaittaminnit… this is a blog by Marcus Ranum, but did he write it? Dude has no problem with porn.
*testing testing* (hrm hrmmph hrmm)
Penis. Peeeenis. Vagina. Vagaiiiina. Boobies!
seachange #9
What is your point?
Speaking of Markov chains – about 20 years ago I was a member in a certain internet forum, debating religious nutjobs ( I was young… ) – one particular nutjob was as obtuse as he was prolific. He also wrote in a fairly recognizable style. So I wrote a python script that checked for new posts by this guy and fed them to my shiny new Markov gibberish generator, just to see if this thing’s output would be distinguishable from the real thing. It was hilariously accurate.
My main twist on the Markov thing was to use ‘begin sentence’ and ‘end sentence’ as special words in the probability database so the thing would produce something resembling sentences instead of an endless stream of gibberish.
The main problem with AI, as currently implemented, is that it’s being used by über-rich fuckwads to get creative-type works without having to pay any human beings for that work. In other words, it’s a massive rip-off. People who actually do make money, or even a living, off of their creative work are, understandably, Not At All Happy about this massive rip-off.
@12,
At this point, I think the main problem with AI is not what it does, not even the vast energy and material costs that underly it. The real problem is what its boosters are promising that it will do. Despite not being able to generate art, text, video or music beyond the quality of ‘indigestible slop’, the promoters promise all things to all people.
Marcus believes it will be ‘sentient’, and soon.
Cretinous political appointees believe it will be able to run their departments with fewer staff and less accountability.
Business leaders dream of a company with no staff at all, or at least no employees and plenty of slave-grade foreign contractors who can ‘support’ the ‘ai’.
Security-state ghouls envision the perfect panopticon, with the AI predicting pre-crime and pre-thought-crime.
And the problem with this is: it’s not going to work. They’re gaining investment in the near-trillions to build all of this, and it’s not going to do what they promise. So they’ll go back to government and say “we need more than money. We need data, all the data. It’s not enough that we buy everyone’s financial, legal, medical and whatever other documents we can find on the open market. To finally make good on all our expensive promises, we need you to take the shackles off. Give us all that government data that you’ve unfairly locked up. We need to know everything about everyone (below oligarch rank, obviously), and then we can finally deliver the perfect AI cop/girlfriend/bureaucrat/benefits manager/whatever.
And government will do it. Look at the UK – they’re already doing it.
I apologize for taking so long to respond. My brain doesn’t work as well as it used to, and it takes me much more thinking and much more time to give considered responses. I realized the other day that that may be why I don’t blog as much. It exhausts me fairly fast. I’m not complaining and that’s just my reality.
Andrew Dalke@#2:
I’ve searched through “The Memoirs Of Baron De Marbot” as translated by Arthur John Butler. I cannot find where he swam across a river to spy on an enemy camp.
I did find where he and others used a boat to cross the Danube to capture an officer’s servant and two soldiers in secret from the enemy camp, in order to question them. Napoleon made him a major. See [blat]
Holy shit, that totally rocked my world. You are correct, of course. And – by the way – thank you for caring enough to fact-check me! I mean that.
The incident to which you are referring is correct. So, what the FUCK happened? I think GPT confabulated. And I think I confabulated. There is probably a weekend worth of discussion and blog posts related to that, alone, but the short form is that I believe that confabulation is a side-effect of how human and machine memories work. We do not, and cannot, perfectly retain all the facts we encounter. So we retain some of them, and leave implied spaces [ Walter Jon Williams] If you want to think of it all as a sort of lossy compression process, that’s what I think is going on.
This seems to be the story people associate with Marbot.
Arrgh! It probably is.
Marbot’s really cool stories was him charging the wall at (?) carrying a seige ladder with a French Imperial Marshal and a bunch of generals, who were shamed that their troops couldn’t take the wall on their own. Marbot who, at that time, would have been resplendent in the uniform of an ADC of a marshal, was the first over the wall and opened the gate for the incoming French force. [By the way, the way Napoleonic legends work, there is no way Marbot could have published that exploit if it was not true because he would have been instantly ruined socially for his pains.]
Then, there was the time at Eylau that he and Lisette charged the Russian corps to retrieve the flag of a line regiment that was about to fall [stderr]
Or the duel he fought between the lines, against an English cavalry officer and two enlisted, and killed one, fucked up another, and chased the third off – only to be reprimanded by a Marshal of the Empire for “showing off”.
By the way, I note that I have slightly altered my writing style as a result of your discovering my confabulation. I am being more inclined to cite vague information rather than the facts that come to my mind. Unless I review them. Old Marcus would have correctly known which battle in the Spanish campaign, which Marshal, and would have remembered that Marbot’s pelisse that he was wearing is in the Invalides Museum. I only remembered that after I wrote my original response though, so I will not cheat.
That annoys the utter shit out of my (I am not complaining about you) because it makes me realize that my brain damage is not entirely scoped to my current memory, there are holes in my past memories as well. I deeply mourn my former near-photographic memory. How many times did you folks catch me in basic mistakes like this? I bet there are a lot more since the winter of 2020.
Anyhow, what does this have to do with AI and humans? A lot. Consider AI learning and human learning as a form of lossy compression. One might remember a detailed template, e.g.:
“in 1492, columbus sailed the ocean blue”
If an AI or a human gets trained with that a lot, the neural network will virtually always spit out
“in 1492, columbus sailed the ocean blue”
But what if it’s less trained? We or the AI might remember something like:
“in 1400something someone sailed to north america”
North America is a well-defined concept in our network, so is “the 15th century” and in terms of compression the AI network will store something like:
13567638, 3849391, 7817364
where 13567638 is an activation to “14th century” and 3849391 is an activation to christopher columbus and how he scammed rulers, and all those stories, and 7817364 pulls in “exploration of North America”
If you ran that backwards you might get:
“in the 1400s, Christopher Columbus conned Queen Isabella out of money to mount an expedition to North America”
That’s got some obvious confabulations jammed in there by yours truly. But since the confabulations are loosely specified within the topics, once the knowledge engine takes over it’s basic probability from there. A less confabulated version might look like:
“in the 1400s, Columbus mounted an expedition to North America”
A more confabulated version might look like:
“In the 1400s, Christopher Columbus scammed Queen Isabella of Spain out of enough money to mount an expedition to North America. He took several ships and they landed in Newfoundland and met Vikings, fought them, and enslaved them.”
I apologize for my mistakes, but I believe mistakes are a part of what thinking is. By the way, if it’s a popular and interesting mistake, we call it creative.
PS – the edition of Marbot you (any of you) specifically want is the one with illustrations by Thomason. I see 6 copies on Ebay for a very low price around $30. Highly recommended.
[Note, since we have been talking about memory, I see it’s listed several times as a 1935 edition, and refrained from adding that to my comment because I don’t really know if it’s true or if I’d be confabulating again. Damn it. It’s not your fault but my confidence in my own mind has taken a 15″ round below the waterline.]
Ketil Tveiten@#3:
You ask if GPT is programmed to lie to you: no, but it is (implicitly) programmed to bullshit you, in the Frankfurterian sense. Iteratively generating text tokens that fit the statistical distribution of the training data (which is what an LLM does) leads to output that looks correct; the algorithm doesn’t have any way to evaluate if it is correct, implicitly it does not care if the output is correct.
Maybe in the 90s, but now there are additional neural networks that are also overlaying the first generated outputs with matches against known reasoning that works.
Frankfurterian sense. Iteratively generating text tokens that fit the statistical distribution of the training data
Maybe in the 1990s. That is simply nothing like that it does, now.
Perhaps you’ve heard the kerfuffle about the new Chinese model [should I post about that?] the main point of which is that it has some techniques in it that OpenAI were hoping to earn a big stock pop with. The idea (roughly) is to start training the model with logic propositions, and apply that as an oppositional network on output: in human terms it doesn’t “know what ‘up’ means but it will downweight any answers that don’t use ‘up’ the way its network matches ‘up.’
In human terms, I see that as my “bullshit detector” which I trained to notice when I am lying, and to pay particular attention to the traceability of facts that I cite. [By this definition, I was not ‘lying’ per Ketil Tveiten on the simple basis that I lie better than that, but it’s a typical sort of “me” mistake. Honestly, though, I am already reeling at realizing that I am confabulating about things I thought I knew and that scares the crap out of me since it’s an indication of incipient dementia.
GPT hasn’t just been a large language model for a long time. It’s a whole network of models that work together to evaluate each other. At this moment it is hard to know what generative networks are opposed, where.
seachange@#9:
Penis. Peeeenis. Vagina. Vagaiiiina. Boobies!
Are you asking me for dick pix? And my boobies are kind of furry (though I have known some who have found them snuggleworthy) Honestly, the old dick isn’t what he used to be so I’d rather not. I could send you some AI-generated impressions of my dick conquering Europe like Napoleon, if you wish…?\
[actually now curious what that prompt would give]
macallan@#11:
Speaking of Markov chains – about 20 years ago I was a member in a certain internet forum, debating religious nutjobs ( I was young… ) – one particular nutjob was as obtuse as he was prolific. He also wrote in a fairly recognizable style. So I wrote a python script that checked for new posts by this guy and fed them to my shiny new Markov gibberish generator, just to see if this thing’s output would be distinguishable from the real thing. It was hilariously accurate.
Please tell me it was zumabot or someone annoying like that.
A big problem with AI is determining your success state and halting state. If you can tell an AI “play Tetris until you win or lose” it’ll figure things out from there, since it has 2 goal states. If it doesn’t know what it’s doing, it doesn’t know when to stop. By the way “paint me the best picture on earth” is a good example of one of those hard-to-compute end states that might make the AI decide to destroy all other art on earth then draw a stick figure.
I think this is a great summary of the state of the art as of a couple years ago. However, retrieval-augmented generation (RAG) has become very popular for domain-specific LLM tasks like website help chatbots, and I’d be surprised if image generators don’t go the same way. A RAG system can have a pretty substantial probability of exactly reproducing a document in the knowledge base, depending on how it’s set up. This is a _good_ thing when there is adequate knowledge data, as it avoids hallucinations. On the other hand, it tends to demonstrate direct copyright violations when the knowledge base is pirated, not that OpenAI would ever do such a thing.
@Marcus #15 “but the short form is that I believe that confabulation is a side-effect of how human and machine memories work.”
I suggest another possibility. Instead of viewing it as two independent processes, think if it as a best-fit match based on your question. Your own confabulations are mirrored, matching your expectations, which you take to have a deeper meaning.
I have done very little with these LLMs because I’ve seen several people astounded at the accuracy of the answers, but when I dig into it to verify, the answer isn’t correct.
One case was something like “What did Meyers say to Ranum at $EVENT” and the answer was “Meyers said $QUOTE”, where the quote was correct, but the mistaken spelling of Myers persisted. It mirrored the input error.
Another example is at https://every.to/chain-of-thought/i-spent-a-week-with-gemini-pro-1-5-it-s-fantastic when the author asked Gemini to give an anecdote about $TOPIC from $BIOGRAPHY. He was so excited with the response (“I could not have found a better anecdote”), that he didn’t bother to verify it was correct. It wasn’t, and others had to point it out to him.
It mirrored his expectations, and confirmation bias did the rest.
Which is why my first thought after reading your example was to verify, not trust.