Remember this old thing?
Rationality Rules was so confident nobody would take him to task, his “improved” video contains the same arguments as his “flawed” one. And honestly, he was right; I’ve seen this scenario play out often enough within this community to know that we try to bury our skeletons, that we treat our minorities like shit, that we “skeptics” are just as prone to being blind followers as the religious/woo crowds we critique. And just like all those other times, I cope by writing words until I get sick of the topic. Sometimes, that takes a while.
In hindsight, “a while” turned out to be seven months and about seventeen blog posts. Why on Earth would I spend so much time and effort focused on one vlogger? I don’t think I ever explained why in those posts, so let’s fix that: the atheist/skeptic movement has a problem with transphobia. From watching my peers insinuate Ann Coulter was a man, to my participation in l’affair Benson, I gradually went from “something feels off about this” to “wow, some of my peers are transphobes.”
As I picked apart the arguments made by transphobes, I started to see patterns. Much like with religious and alt-Right extremists, there’s a lot of recycling going on. Constantly, apologists are forced to search for new coats of paint to cover up old bigoted arguments. I spotted a shift from bathroom rhetoric to sports rhetoric in early 2019 and figured that approach would have a decent lifespan. So when Rationality Rules stuck to his transphobic guns, I took it as my opportunity to defuse sports-related transphobic arguments in general. If I did a good enough job, most of these posts would still be applicable when the next big-name atheist or skeptic tried to invoke sports.
My last post was a test of that. It was a draft I’d been nursing for months back in 2019, but after a fair bit of research and some drastic revisions I’d gotten Rationality Rules out of my system via other posts. So I set it aside as a test. If I truly was right about this shift to sports among transphobes, it was only a matter of time until someone else in the skeptic/atheist community would make a similar argument and some minor edits would make it relevant again. The upshot is that a handful of my readers were puzzled by this post about Rationality Rules, while the vast majority of you instead saw this post about Shermer and Shrier.
The two arguments aren’t quite the same. Rationality Rules emphasizes that “male puberty” is his dividing line; transgender women who start hormone therapy early enough can compete as women, according to him, and he relies on that to argue he’s not transphobic at all. Shermer is nowhere near as sophisticated, arguing for a new transgender-specific sporting category instead. Shrier takes the same stance as Rationality Rules, but she doesn’t push back on Shermer’s opinions.
But not only are the differences small, I doubt many people had “women are inherently inferior to men in domain X” on their transphobe bingo card. And yet, the same assertion was made at two very different times by three very different people. I consider this test a roaring success.
One consequence is that most of my prior posts on Rationality Rules’ arguments against transgender athletes still hold quite a bit of value, and are worth boosting. First, though, I should share the three relevant posts that got me interested in sports-related apologia:
Trans Athletes, the Existence of Gender Identity, … / … and Ophelia Benson: The first post proposed two high-level arguments in favour of allowing transgender athletes to compete as the gender they identify with. The second is mostly about calling out Benson for blatant misgendering, but I also debunk some irrational arguments made against transgender athletes.
I Think I Get It: My research for the prior two posts led me to flag sport inclusion as the next big thing in transphobic rhetoric. The paragraph claiming “they think of them as the worst of men” was written with Benson in mind, but was eerily predictive of Shermer.
And finally, the relevant Rationality Rules posts:
EssenceOfThought on Trans Athletes: This is mostly focused on EssenceOfThought‘s critique of Rationality Rules, but I slip in some extras relating to hemoglobin and testosterone.
Rationality Rules is an Oblivious Transphobe: My first crack at covering the primary factors of athletic performance (spoiler alert: nobody knows what they are) and the variation present. I also debunk some myths about transgender health care, refute some attempts to shift the burden of proof or argue evidence need not be provided.
Texas Sharpshooter: My second crack at athletic performance and its variance, this time with better analysis.
Rationality Rules is “A Transphobic Hack“: This is mostly commentary specific to Rationality Rules, but I do link to another EssenceOfThought video.
Special Pleading: My second crack at the human rights argument, correcting a mistake I made in another post.
Rationality Rules is a “Lying” Transphobe: I signal boost Rhetoric&Discourse‘s video on transgender athletes.
“Rationality Rules STILL Doesn’t Understand Sports”: A signal boost of Xevaris‘ video on transgender athletes.
Lies of Omission: Why the principle of “fair play” demands that transgender athletes be allowed to compete as their affirmed gender.
Begging the Question: How the term “male puberty” is transphobic.
Rationality Rules Is Delusional: Rob Clark directs me to a study that deflates the muscle fibre argument.
Cherry Picking: If transgender women possess an obvious performance benefit, you’d expect professional and amateur sporting bodies to reach a consensus on that benefit existing and to write their policies accordingly. Instead, they’re all over the place.
Separate and Unequal: I signal boost Colleen Tighe‘s comic on transgender athletes.
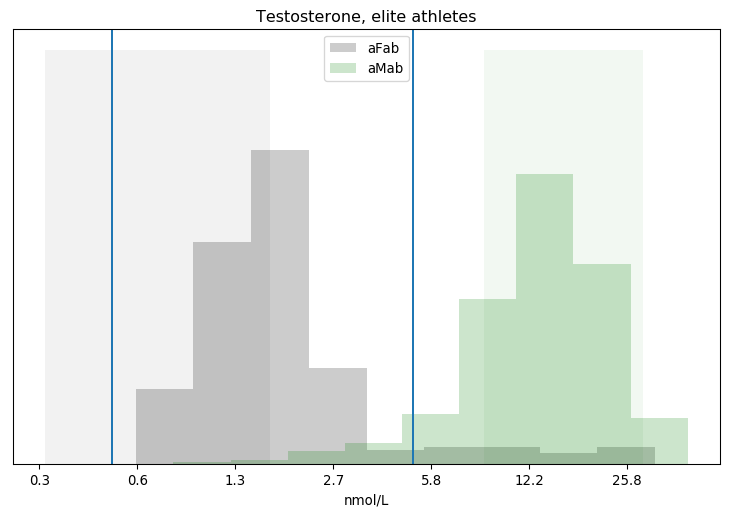
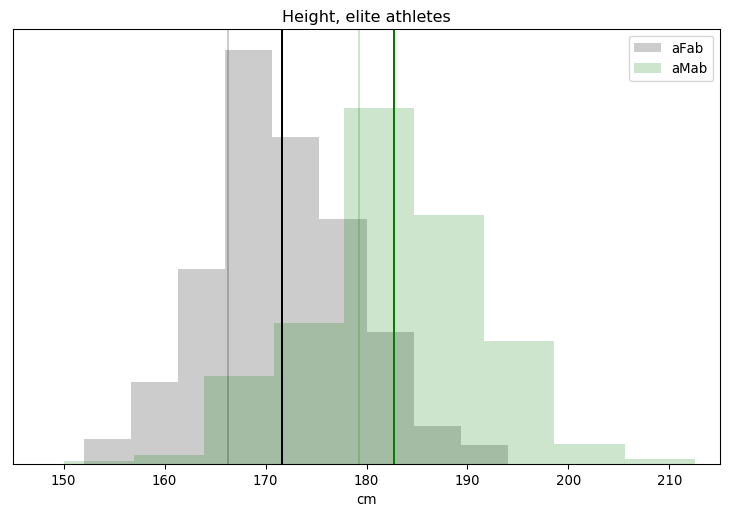
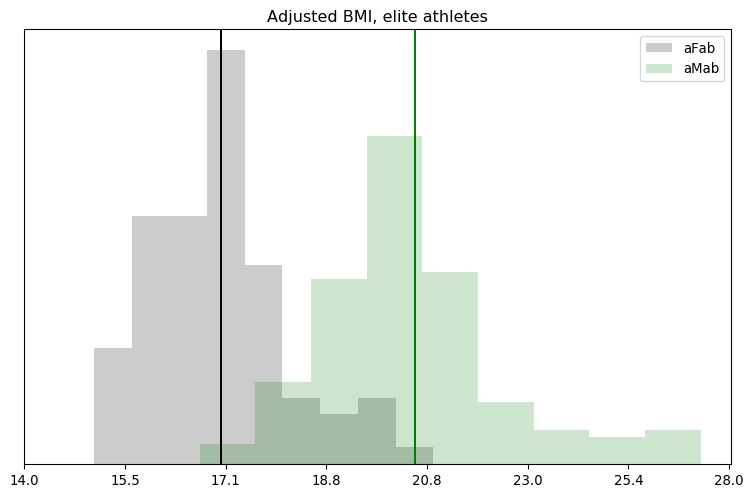
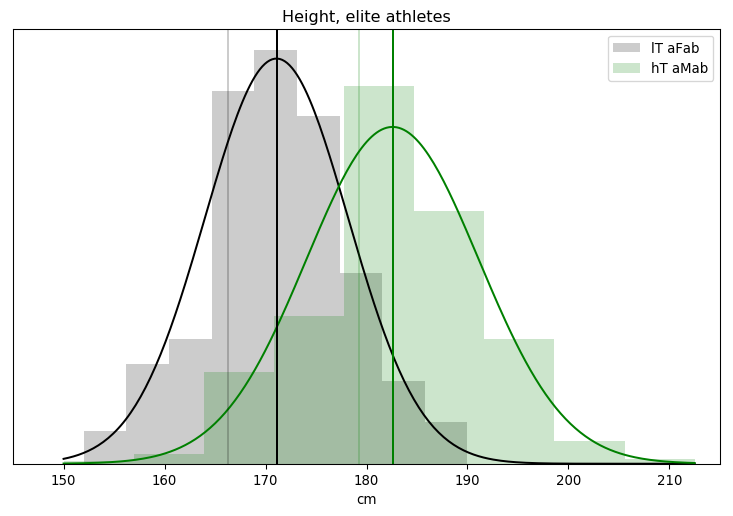
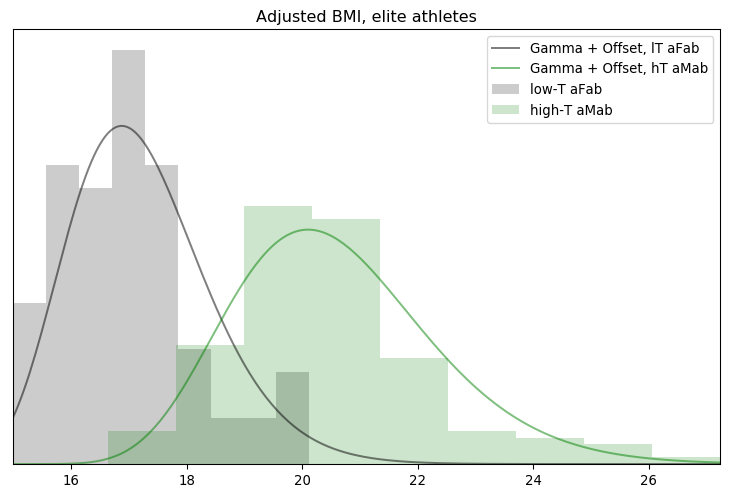
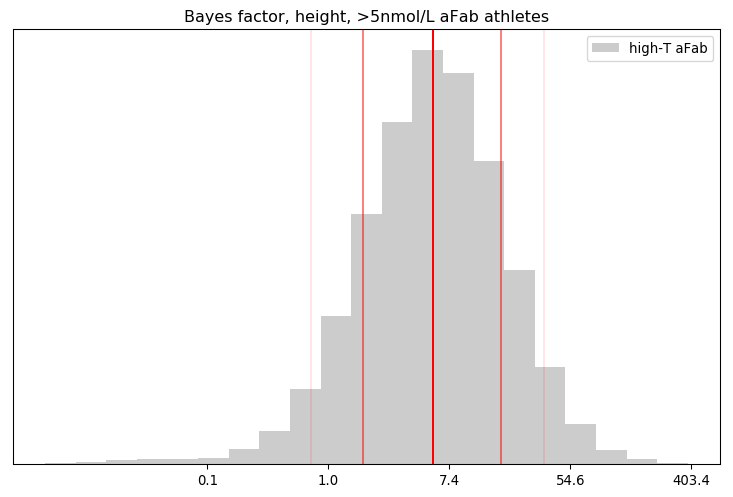
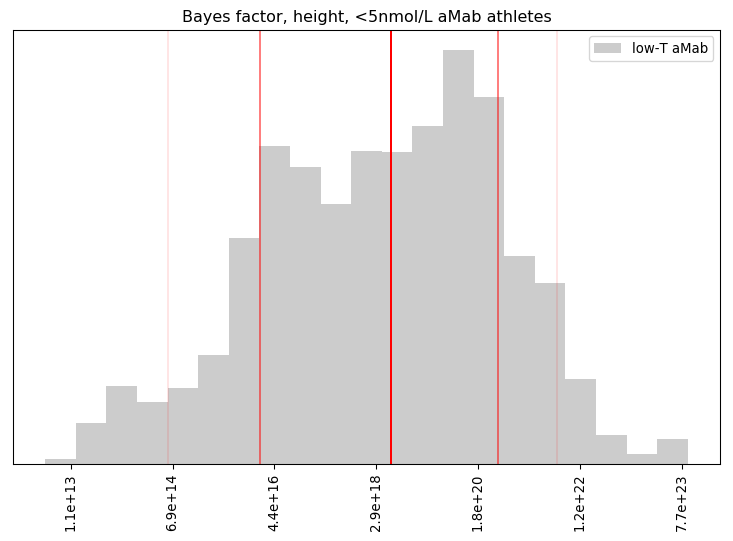
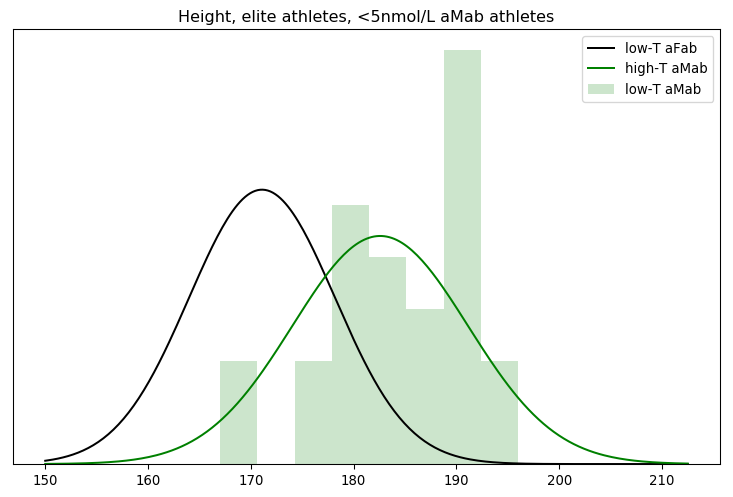
Rationality Rules DESTROYS Women’s Sport!!1!: I take a deep dive into a dataset on hormone levels in professional athletes, to see what would happen if we segregated sports by testosterone level. The title gives away the conclusion, alas.
That takes care of most of Shermer and Shrier’s arguments relating to transgender athletes, and the remainder should be pretty easy. I find it rather sad that neither are as skilled at transphobic arguments as Rationality Rules was. Is the atheist/skeptic community getting worse on this subject?