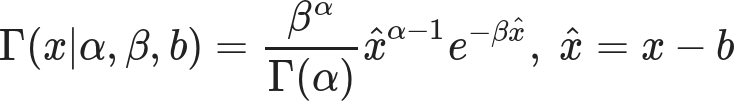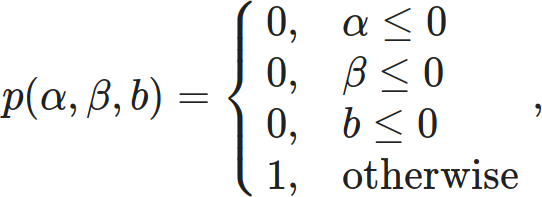We seem to be in a cycle. Every time PZ Myers posts something about transgender people, the comment thread floods with transphobes. Given the names involved, I suspect this is due to Ophelia Benson’s effect on the atheio/skeptic sphere.
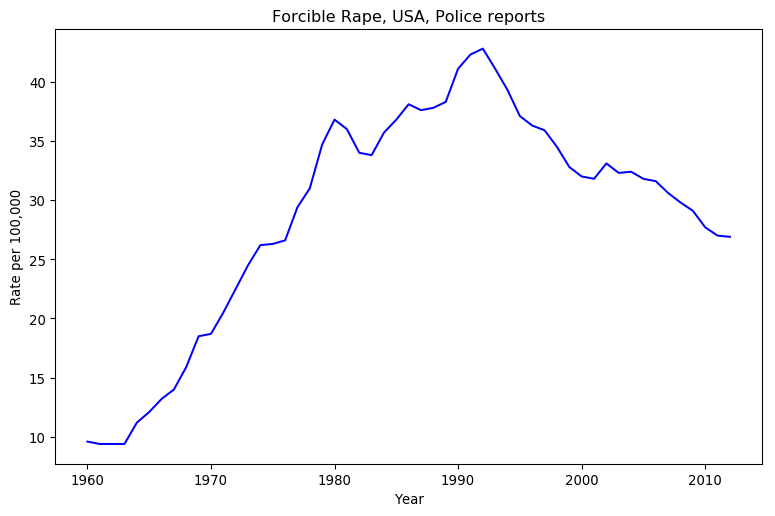
Regardless, there may be another pattern in play. The go-to argument of these transphobes was transgender athletes, with the old bathroom line showing up late in the thread. I had a boo at GenderCritical on Reddit, to assess if this was just a local thing, and noticed there were more stories about athletics than bathrooms over there. Even one of the bigots thought this was new. Has there been a shift of rhetoric among transphobes?
If so, I think I understand why.