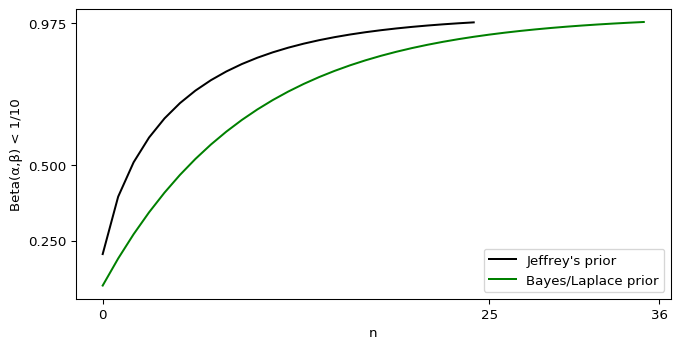
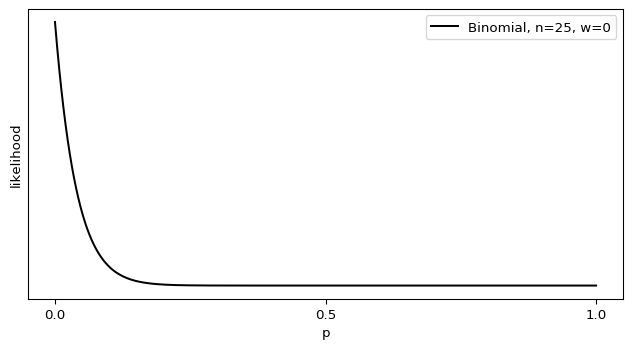
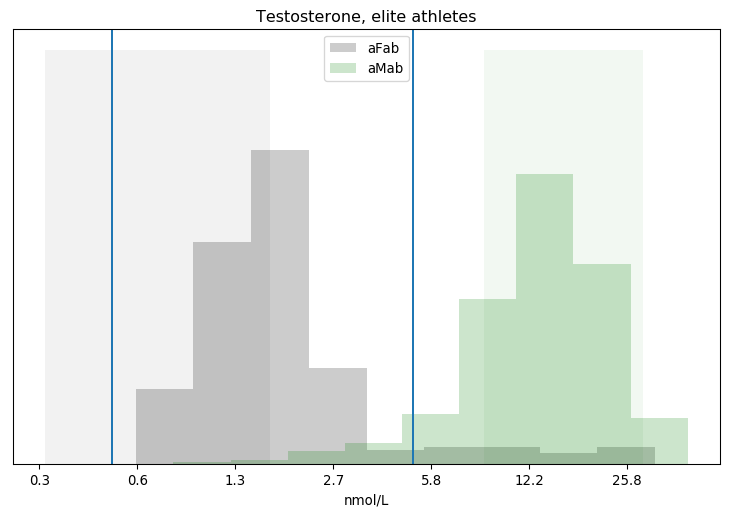
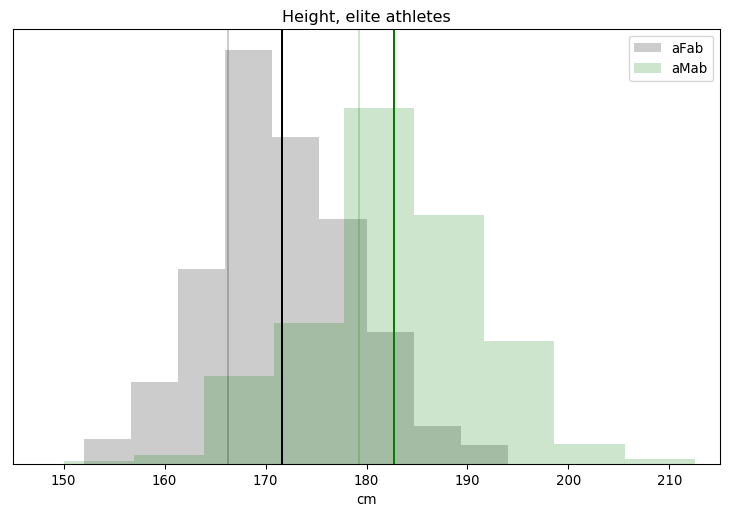
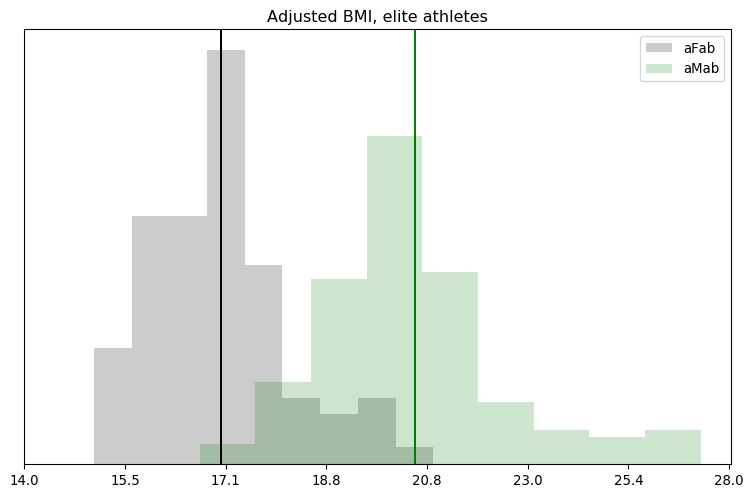
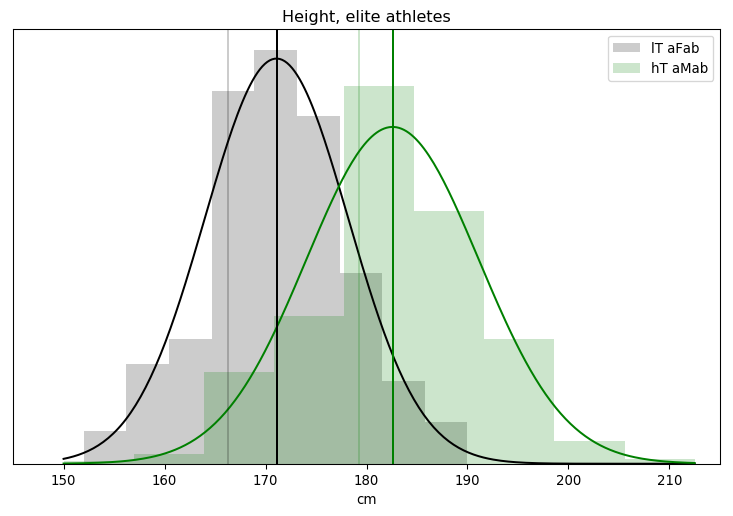
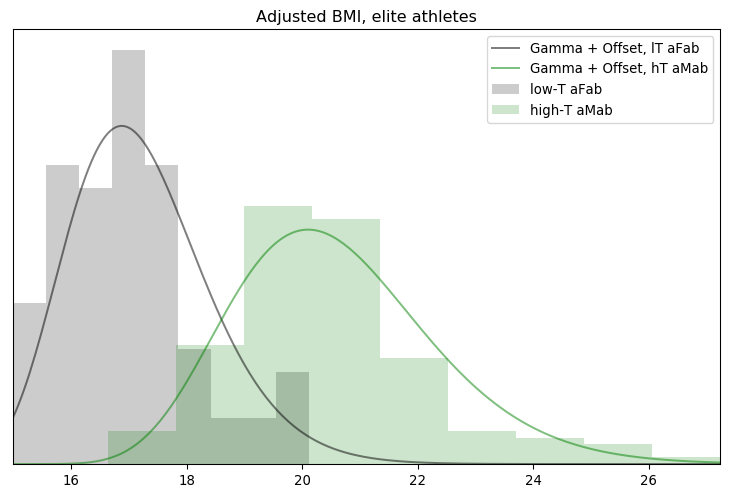
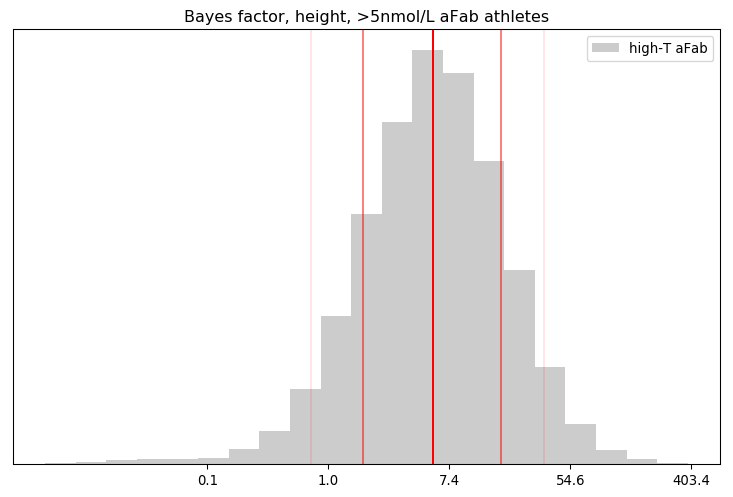
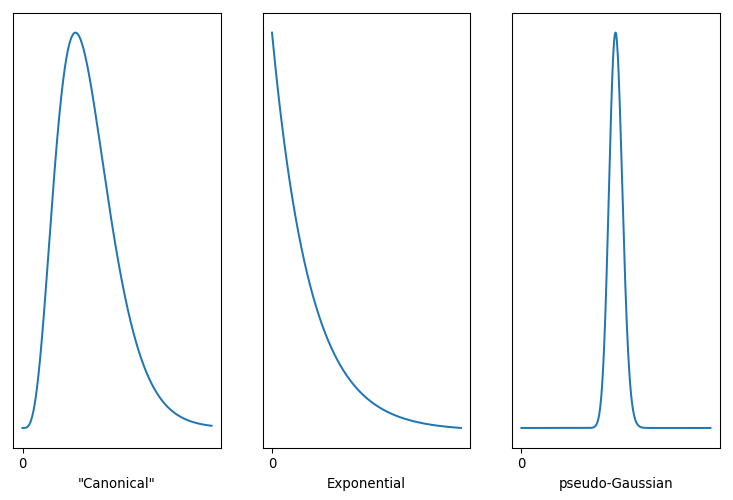
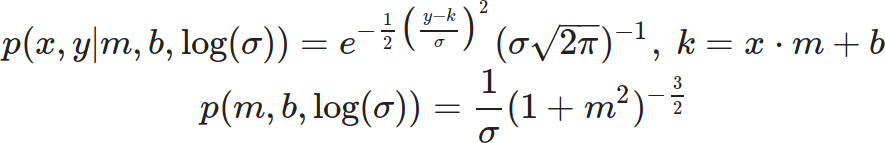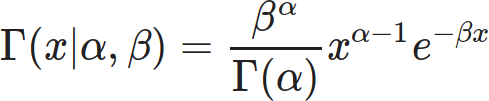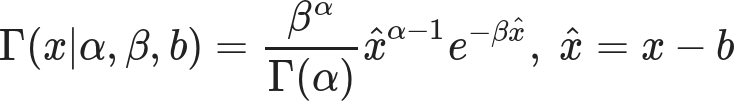One of the ways I’m coping with this pandemic is studying it. Over the span of months I built up a list of questions specific to the situation in Alberta, so I figured I’d fire them off to the PR contact listed in one of the Alberta Government’s press releases.
That was a week ago. I haven’t even received an automated reply. I think it’s time to escalate this to the public sphere, as it might give those who can bend the government’s ear some idea of what they’re reluctant to answer. [Read more…]