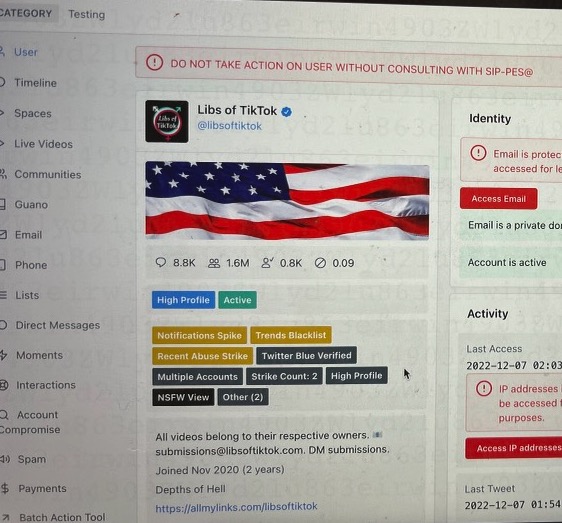
There’s a line in Minority Report that’s stuck with me. After looking over the crime scene, the detective character turns to another cop. “This is what we’d call an orgy of evidence. Know how many orgies I had as a homicide cop? None.” The logic behind it is simple: the real world is messy, so when you stumble on something that conforms exactly to your biases, be skeptical.
In every sufficiently large business we have observed (say, with 500+ employees), we have noted that continued advancement, and increasingly continued employment, has started to require repeated professions of belief in the transformative power of AI for said business. I am not talking about providing ideas about how to use AI in the business – I mean religious profession, declarations of faith. Overwhelmingly these statements are made by non-technicians, though it is not uncommon for technicians to emit deranged statements to curry favour.
I just stumbled into an orgy, and so my instinct is to take a step back and see if I’ve missed anything.