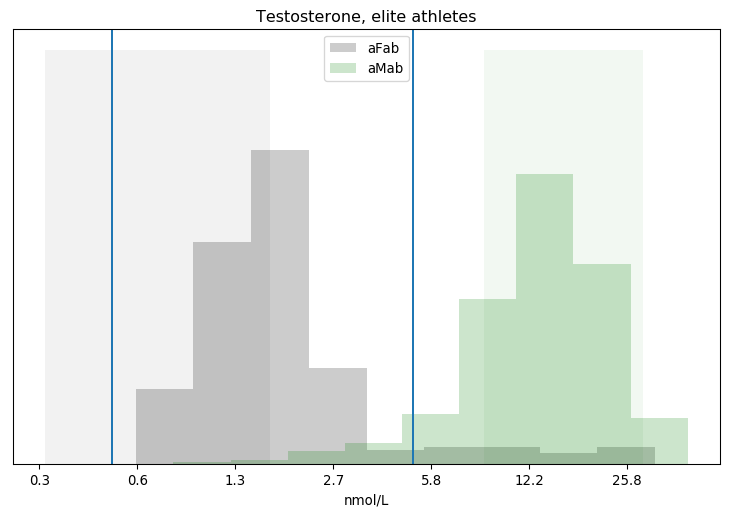
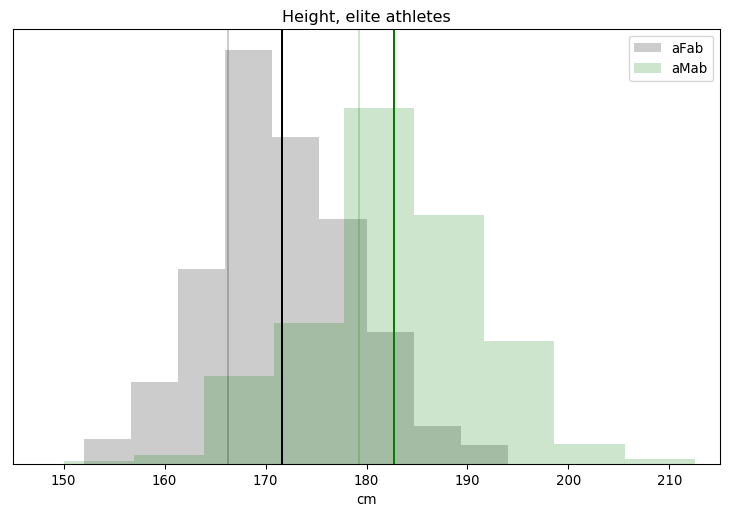
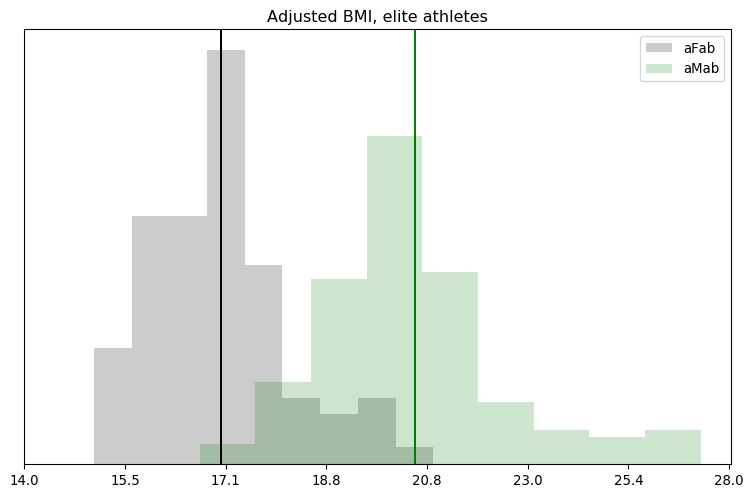
Sorry all, I’ve been busy. But I thought this situation was worth carving some time out to write about: Graham Linehan is a cowardly ass.
See, EssenceOfThought just released a nice little video calling Linehan out for his support of conversion therapy. As they put it:
Now maybe you read that Tweet and didn’t think much of it. After all, it’s just a call for ‘gender critical therapists’. Why’s that a problem? Well gender critical is euphemism for transphobia in the exact same way that ‘race realist’ is for racism. It’s meant to make the bigotry sound more scientific and therefore more palatable.
The truth meanwhile is that every major medical establishment condemns the self-labelled ‘gender critical’ approach which is a form of reparative ‘therapy’, though as noted earlier it is in fact torture. Said methods are abusive and inflict severe harm on the victim in attempts to turn them cisgender and force them to adhere to strict and archaic gender roles.
I response, Linehan issued a threat:
Hi there I have already begun legal proceedings against Pink News for this defamatory accusation. Take this down immediately or I will take appropriate measures.
Presumably “appropriate measures” involves a defamation lawsuit, though when you’re associated with a transphobic mob there’s a wide universe of possible “measures.”
In all fairness, I should point out that Mumsnet is trying to clean up their act. Linehan, in contrast, was warned by the UK police for harassing a transgender person. He also does the same dance of respectability I called out last post. Observe:
Linehan outlines his view to The Irish Times: “I don’t think I’m saying anything controversial. My position is that anyone suffering from gender dysphoria needs to be helped and supported.” Linehan says he celebrates that trans people are at last finding acceptance: “That’s obviously wonderful.” […]
He characterises some extreme trans activists who have “glommed on to the movement” as “a mixture of grifters, fetishists, and misogynists”. … “All it takes is a few bad people in positions of power to groom an organisation, and in this case a movement. This is a society-wide grooming.”
I suspect Linehan would lump EssenceOfThought in with the “grifters, fetishists, and misogynists,” which is telling. If you’ve never watched an EssenceOfThought video before, do so, then look at the list of citations:
[4] UK Council for Psychotherapy (2015) “Memorandum Of Understanding On Conversion Therapy In The UK”, psychotherapy.org.uk Accessed 31st August 2016: https://www.psychotherapy.org.uk/wp-c…
[5] American Academy Of Pediatrics (2015) “Letterhead For Washington DC 2015”, American Academy Of Pediatrics Accessed 19th September 2018; https://www.aap.org/en-us/advocacy-an…
[6] American Medical Association (2018) “Health Care Needs of Lesbian, Gay, Bisexual, Transgender and Queer Populations H-160.991”, AMA-ASSN.org Accessed 21st September 2019; https://policysearch.ama-assn.org/pol…
[7] Substance Abuse And Mental Health Services Administration (2015) Ending Conversion – Supporting And Affirming LGBTQ Youth”, SAMHSA.gov Accessed 21st September 2019; https://store.samhsa.gov/system/files…
[8] The Trevor Project (2019) “Trevor National Survey On LGBTQ Youth Mental Health”, The Trevor Project Accessed 28th June 2019; https://www.thetrevorproject.org/wp-c…
[9] Turban, J. L., Beckwith, N., Reisner, S. L., & Keuroghlian, A. S. (2019) “Association Between Recalled Exposure To Gender Identity Conversion Efforts And Psychological Distress and Suicide Attempts Among Transgender Adults”, JAMA Psychiatry
[10] Kristina R. Olson, Lily Durwood, Madeleine DeMeules, Katie A. McLaughlin (2016) “Mental Health of Transgender Children Who Are Supported in Their Identities” http://pediatrics.aappublications.org…
[11] Kristina R. Olson, Lily Durwood, Katie A. McLaughlin (2017) “Mental Health And Self-Worth In Socially Transitioned Transgender Youth”, Child And Adolescent Psychiatry, Volume 56, Issue 2, pp.116–123 http://www.jaacap.com/article/S0890-8…
What I love about citation lists is that you can double-check they’re being accurately represented. One reason why I loathe Stephen Pinker, for instance, is because I started hopping down his citation list, and kept finding misrepresentation after misrepresentation. Let’s look at citation 9, as I see EoT didn’t link to the journal article.
Of 27 715 transgender survey respondents (mean [SD] age, 31.2 [13.5] years), 11 857 (42.8%) were assigned male sex at birth. Among the 19 741 (71.3%) who had ever spoken to a professional about their gender identity, 3869 (19.6%; 95% CI, 18.7%-20.5%) reported exposure to GICE in their lifetime. Recalled lifetime exposure was associated with severe psychological distress during the previous month (adjusted odds ratio [aOR], 1.56; 95% CI, 1.09-2.24; P < .001) compared with non-GICE therapy. Associations were found between recalled lifetime exposure and higher odds of lifetime suicide attempts (aOR, 2.27; 95% CI, 1.60-3.24; P < .001) and recalled exposure before the age of 10 years and increased odds of lifetime suicide attempts (aOR, 4.15; 95% CI, 2.44-7.69; P < .001). No significant differences were found when comparing exposure to GICE by secular professionals vs religious advisors.
Compare and contrast with how EssenceOfThought describe that study:
They also found no significant difference when comparing religious or secular conversion attempts. So it’s not a case of finding the right way to do it, there is no right way to do it. You’re simply torturing someone for the sake of inflicting pain. And that is fucking digusting.
And the thing is we know how to help young people who are questioning their gender. And that is to take the gender affirmative approach. That is an approach that allows a child and young teen to explore their identity with support. No mater what conclusion they arrive at.
Compare and contrast both with Linehan’s own view of gender affirmation in youth.
“There are lots of gender non-conforming children who may not be trans and may grow up to be gay adults, but who are being told by an extreme, misogynist ideology, that they were born in the wrong body, and anyone who disagrees with that diagnosis is a bigot.”
“It’s especially dangerous for teenage girls – the numbers referred to gender clinics have shot up – because society, in a million ways, is telling girls they are worthless. Of course they look for an escape hatch.”
“The normal experience of puberty is the first time we all experience gender dysphoria. It’s natural. But to tell confused kids who might every second be feeling uncomfortable in their own skin that they are trapped in the wrong body? It’s an obscenity. It’s like telling anorexic kids they need liposuction.”
So much for helping people with gender dysphoia. If Linehan had his way, the evidence suggests transgender people would commit suicide at a higher rate than they do now. EoT’s accusation that Linehan wishes to “eradicate trans children” is justified by the evidence.
Unable to argue against that truth, Linehan had no choice but to try silencing his critics via lawsuits. Rather than change his mind in the face of substantial evidence, Linehan is trying to sue away reality. It’s a cowardly approach to criticism, and I hope he’s Streisand-ed into obscurity for trying it.