Aren’t you excited? You get to give Donald Trump more money!
And if that’s not enough thrills for you, we also get to wait and see how Donald Trump’s and Kim Jong-un’s game of nuclear chicken turns out.
Aren’t you excited? You get to give Donald Trump more money!
And if that’s not enough thrills for you, we also get to wait and see how Donald Trump’s and Kim Jong-un’s game of nuclear chicken turns out.

It’s a Catholic magazine, and Anthony Barcellos sent me a scan of their letters page. It’s very enlightening.

The things I learned from this sample:
Catholics are old.
Many of them are in prison.
I have succeeded in my crusade to drive them out of my university.
What caught Anthony’s eye was this letter:
MAGAZINE IS “VITAL” FOR CATHOLIC STUDENTS
The University of Minnesota in Morris, as well as the main campus in the Twin Cities, is 98% atheist. That is why Inside the Vatican is vital. I was the only Catholic professor there, now retired, so I know whereof I speak. I wish to give this gift subscription to the few Catholic students at UM-Morris.
Maria Louisa Rodriguez
Morris, Minnesota, USA
I do not know who Maria Louisa Rodriguez is — she may have retired before I got here. But there are a few errors in her letter. Catholicism is the single largest religious denomination in Minnesota, with about a quarter of the population, and while universities do have their demographic biases, I rather doubt that we’d be able to exclude Catholics that thoroughly, especially since we don’t have any filters in admissions that would discriminate.
I wish I could say specifically that I know Catholic students, but since I don’t attend the church, and I never ask any of my students what they do on Sundays, I don’t know. Also don’t care. It’s not as if I would put a question on an exam about it.
I do happen to know that a couple of faculty members are Catholic, so I guess we’ve been backsliding since those halcyon, Catholic-free days immediately after Ms Rodriquez’s retirements.
I’m also curious about what’s going on in the UMM Newman Center, this lovely building just off campus, a few blocks from me. Apparently all the photos on that page of students there are photoshop fakes, their schedule of Catholic-associated events are a lie, and the coordinators are all making it up when they claim to be students.
Uh-oh. Maybe the lesson I should learn is that the old jailbirds who write in to Inside the Vatican are all making crap up.

Here’s this chart of the caloric value of cannibalism.

The article tries to spin this negatively — as a game animal, humans are a very poor return on the investment of effort in hunting them. As a cheerful optimist with a sunny disposition, however, I prefer to put this in a good light: if you are on a diet and trying to lose weight, then cannibalism might just be the perfect weight loss plan for you.
Basically, if you’re eating kale regularly, you might as well try switching things up a bit.

It’s been a while since I brought everyone up to date on the progress of my Ecological Development course, because I’ve been busy. So have the students. After our spring break I subjected them to the dreaded oral exam, which actually isn’t so bad. I tried to engage them less in an adversarial role and more as a quiet conversation between two people on science. Some students took to it easily — the more outgoing ones — others were noticeably nervous, which was OK, and I hope they learned that it isn’t that terrifying to have a discussion with a mentor.
Then the next few weeks were a mad whirl of horrible things done to babies: teratogens, endocrine disruptors, multi-generational epigenetic inheritance, all that fun stuff. We wrapped up with the depressing stuff for me, although the young’uns were more sanguine, I think. We talked about adult onset developmental diseases (it’s good to look at heart disease through the lens of developmental biology), aging, and cancer. Next week they get some time off, because I’m being drawn away to a conference on the east coast, but they’re supposed to spend it preparing for their final presentations, which will consume the last two weeks of class. And then we’re all done. School’s out for summer!
I’m going to say a bit about our last class discussion, because it got into some interesting territory and reflects the theme of the course well. We talked about that theory mentioned in the title of this article, and the origins of cancer, and to do that I have to give you all a little background.
Tissue Organization Field Theory (TOFT) is an alternative to what is sort of the dominant paradigm in cancer biology, the Somatic Mutation Theory (SMT). I have to say “sort of” because what I get from the literature is that SMT is more of a working assumption, and that cancer biologists are open to new ideas. The SMT is a useful molecular perspective on carcinogenesis. It postulates that cancer is a cellular disorder in which the genetic material has been perturbed to produce a lineage of cells with aberrant characteristics, that if we want to figure out what the primary cause of a cancer was, we can trace it back to a somatic mutation, or a change in a critical gene or, more likely, multiple genes, that lead to uncontrolled proliferation. So we pursue oncogenes, genes that have the potential to acquire mutations that trigger cell division or bypass control points, and tumor suppressor genes, protective genes that, when damaged, remove essential regulators of growth.
So, under the SMT, cancer is a disease caused by the progressive accumulation of mutations in cells of the body, as they divide. These mutations gradually strip away the normal restraints on cell division, and on immune system recognition, and on cell death activation, etc., etc., etc. until you have a rogue cell that can seed the growth of a massively disruptive tumor.
And it’s not wrong! Cancer biology has been immensely productive in identifying the enabling mutations, and even developing treatments that specifically target molecular agents of cancer. We know that somatic mutations are a routine part of the progression of cancer, and we also know that there heritable alleles that can affect the likelihood of the disease. The SMT is a tool to explain many of the phenomena of cancer, and it’s not going to just go away. It’s also a tool that is amenable to a reductionist approach to cancer biology, and is well-adapted to the utility of molecular biology.
Tissue Organization Field Theory is an alternative explanation for the origins of cancer.
TOFT argues that the focus of the SMT on single cell events is inappropriate and misses a whole range of effects at the level of tissue organization, effects which are more important in creating a pathological environment in which those mutations can accumulate. Further, it gets into field theory, which is important in developmental biology but isn’t exactly the subject of common conversation. Here’s one standard definition of a field: “a morphogenetic (or developmental) field is a region or a part of the embryo which responds as a coordinated unit to embryonic induction and results in complex or multiple anatomic structures.” If that’s not helpful — and it probably isn’t, we’d have to go over a textbook if we wanted to explain developmental field theory — here’s a diagramatic metaphor. Do you see the field in this picture?

There’s something special about part of that image, but it’s not that the individual subunits are intrinsically different — it’s tied up in the relationships between the central set of blocks and the blocks outside of it. There’s something different going on with a subset of the blocks, but it’s not necessarily best described by explaining the details of single blocks, but is more easily explained at a higher level, as properties of a tissue within a tissue. Of course, what will eventually happen in a developing organism is that those central blocks will express a unique pattern of genes, so eventually it’s identifiable by molecular markers, but the field first arises in a sea of genetically and epigenetically uniform cells.

Another important property of a field is that it is not itself uniform. It’s going to acquire complex spatial properties over time. Insect limbs, for instance, arise from a disc-shaped field with extensive patterning information within them, so the central region will become the distal tip of the limb, and there is information that is interpreted as polar coordinates that specifies what portion of the limb is anterior, posterior, medial, and lateral (the limb is not a uniform cylinder). Similarly, vertebrates have a limb field represented in the limb bud, with gradients of morphogens specifying the orientation of the limb, and with re-expression of Hox genes used to specify longitudinal positions. Hox genes in a limb field are interpreted in different ways than Hox genes along the body axis, obviously.
The key factor here is that in field theory cells are not simply independent units — they are part of a larger assemblage, a tissue, that has complex fates that are not easily summarized by individual gene expression. They have to be understood as a network.
That’s the first thing to remember: TOFT is treating a cancer as a field, with field properties, which are not adequately described if you only look at cancer as a collection of autonomous cells all doing their own thing at the command of their broken genes. Aberrant disruption of the field can produce aberrant structures without requiring any genetic changes.
This is the difference between a mutagen and a teratogen. The effects of a mutagen are caused directly by damage to the structure or sequence of DNA; they produce heritable changes to the cells of an organism. Teratogens, on the other hand, are not necessarily mutagenic at all — they disrupt the normal pattern of development without changing genes at all. Thalidomide babies, for example, had some extreme morphological changes, like phocomelia or truncated limb development, but those are not heritable, and the people affected by thalidomide can grow up to have normal, healthy children.
TOFT argues something similar, that there is a disruption of a tissue that initializes aberrant growth, that may then be an enabling precondition for the accumulation of mutations. One piece of evidence for this is a set of experiments on tissues, illustrated below.
Most cancers arise in epithelial tissues, like the sheets of cells that line glands or your organs, in large part because those are the cells that divide most frequently. These epithelial cells, also called parenchyma, do not typically grow in isolation, but on a substrated of connective tissue, extracellular matrix, and other cell types, called stroma. The stroma supports and signals the overlying epithelium, and vice versa, and together they make a coherent functional tissue.
The theory suggests that cancers can arise in epithelia by way of disruptions in signaling in the stroma. A carcinogen could distort the interactions between stroma and epithelium at the level of the stroma, and the epithelium then goes nuts and proliferates to produce a pre-cancerous mass.
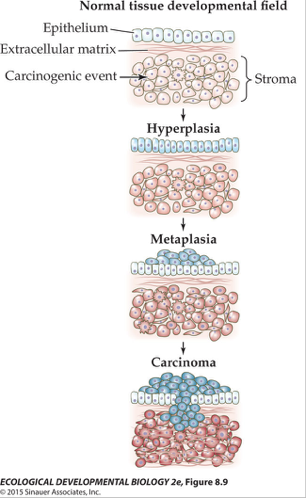
One test of the theory would be to separate stroma and epithelium, expose the stroma to a short-lived teratogen, and then after the teratogen was washed out, re-associate the two and determine whether there was an increase in the frequency of cancers in the epithelium, which has not been exposed to teratogens.
The experiment has been done. Here are the results for rat mammary gland tissue in which the epithelium was exposed to the solvent vehicle but no N-methyl nitorsourea (a potent mutagen), while the stroma was soaked in NMu, labeled VEH/NMu. The numerator describes the epithelial condition, and the denominator is the stroma condition, so NMu/NMu means both were hit with the mutagen, VEH/VEH means both were exposed only to the vehicle, and NMu/VEH means the epithelium was poisoned with NMu, while the stroma was not.

There’s an awfully strong positive correlation between exposing the stroma to mutagens and getting tumors, and a negative correlation with exposing epithelia to mutagens and tumors.
You want more evidence? Here’s a very interesting experiment. Start with aggressively metastatic melanoma cells from a human patient (labeled in green, below). Inject them into a completely different environment, the neural crest pathway in a developing chick embryo. Surprisingly, if you accept the SMT, the cancer cells calm right down and are conditioned by their environment to participate in normal development in the chick and get incorporated into the facial cartilages and sympathetic ganglia.

I suspect those melanoma cells do carry somatic mutations, and are not actually “cured” of a predisposition to cancer. What the experiment says, though, is that environmental influences are extremely important in regulating the behavior of these cells, and that modifying the cells communicating with the cancerous cells can have a profound effect on how they act.
Note that this is not a pathway to a cure. It’s all well and good to say that if we could break up a tumor, separate the individual cells and put them in a more nurturing, embryo-like environment, they’ll stop acting up and resume normal, regulated growth, but if we could do that, slicing out the tumor and tossing it in an incinerator would also be effective. The problem is that in a human patient we do not and cannot have such precise control of the micro-environment of the cancer, and in fact, the tumor itself is a kind of bubble of micro-environment that actively reinforces cancer growth.
My students and I read a paper from Carlos Sonnenschein, who is a major proponent of TOFT, as well as our textbook summary. The paper was titled The tissue organization field theory of cancer: a testable replacement for the somatic mutation theory. They’re a smart bunch, and they see the promise of the idea, in part because this whole course is about thinking a level above reductionist cell biology, but they also found the word “replacement” off-putting. It doesn’t invalidate everything about the SMT, but it does support an important alternative route for carcinogenesis. They also weren’t impressed by the rather aggressive insistence by some TOFT proponents that they have the One True Explanation, and that their observations are sufficent to explain cancer — we came up with a few alternative interpretations of their own favorite experiments that they haven’t nailed down completely just yet.
One thing that amused me is that the class consensus actually converged on the views of another paper by Bedessem and Ruphy, which I did not assign them to read, largely because of its more philosophical argument (I’ve focused on empirical/experimental papers in the class). This is how I feel about it, too.
The building of a global model of carcinogenesis is one of modern biology’s greatest challenges. The traditional somatic mutation theory (SMT) is now supplemented by a new approach, called the Tissue Organization Field Theory (TOFT). According to TOFT, the original source of cancer is loss of tissue organization rather than genetic mutations. In this paper, we study the argumentative strategy used by the advocates of TOFT to impose their view. In particular, we criticize their claim of incompatibility used to justify the necessity to definitively reject SMT. First, we note that since it is difficult to build a non-ambiguous experimental demonstration of the superiority of TOFT, its partisans add epistemological and metaphysical arguments to the debate. This argumentative strategy allows them to defend the necessity of a paradigm shift, with TOFT superseding SMT. To do so, they introduce a notion of incompatibility, which they actually use as the Kuhnian notion of incommensurability. To justify this so-called incompatibility between the two theories of cancer, they move the debate to a metaphysical ground by assimilating the controversy to a fundamental opposition between reductionism and organicism. We show here that this argumentative strategy is specious, because it does not demonstrate clearly that TOFT is an organicist theory. Since it shares with SMT its vocabulary, its ontology and its methodology, it appears that a claim of incompatibility based on this metaphysical plan is not fully justified in the present state of the debate. We conclude that it is more cogent to argue that the two theories are compatible, both biologically and metaphysically. We propose to consider that TOFT and SMT describe two distinct and compatible causal pathways to carcinogenesis. This view is coherent with the existence of integrative approaches, and suggests that they have a higher epistemic value than the two theories taken separately.
Anyway, keep an eye open for more on the tissue organization field theory — there seems to be a fair bit of ongoing debate in the scientific literature about it. I’ll keep telling everyone cancer is a developmental disease, so you need more developmental biologists to study it. Or, alternatively, every cancer biologist is already a developmental biologist.
Bedessem B, Ruphy S. (2015) SMT or TOFT? How the two main theories of carcinogenesis are made (artificially) incompatible. Acta Biotheor. 63(3):257-67.
Soto AM, Sonnenschein C (2011) The tissue organization field theory of cancer: a testable replacement for the somatic mutation theory. Bioessays. 33(5):332-40.

I can’t figure it out. I read this article about Dan Rochkind, expert dater, and I swear I was sitting here thinking it had to be some kind of satire.
When it came to dating in New York as a 30-something executive in private equity, Dan Rochkind had no problem snagging the city’s most beautiful women.
“I could have [anyone] I wanted,” says Rochkind, now 40 and an Upper East Sider with a muscular build and a full head of hair. “I met some nice people, but realistically I went for the hottest girl you could find.”
He spent the better part of his 30s going on up to three dates a week, courting 20-something blond models, but eventually realized that dating the prettiest young things had its drawbacks — he found them flighty, selfish and vapid.
“Beautiful women who get a fair amount of attention get full of themselves,” he says. “Eventually, I was dreading getting dinner with them because they couldn’t carry a conversation.”
He’s got a day job pushing money and paper around, and he spends his evenings trying to have sex with younger women, and he’s got the nerve to accuse them of being “flighty, selfish and vapid”? Look in a mirror, guy.
But what had me most baffled about the nature of the article was this photo caption.
Dan Rochkind used to date swimsuit models, but he’s happier now that he’s engaged to a merely beautiful woman, Carly Spindel (right).
Mind…blown. What was the writer trying to say? What does Carly Spindel think of that? Is Dan smirking at that? What’s the difference between swimsuit models and merely beautiful women?
I don’t think I want to learn any more about the NY Post’s universe. It seems flighty, selfish and vapid.

I’ve been wondering that for a while, but the question has become more acute recently. CNN keeps bringing on that lying boob, Jeffrey Lord, or the Disney villainesque Kelly Ann Conway. Wolf Blitzer has been promoted above his level of competence, I suspect because of his name — he belongs in a Joseph Heller novel. Everyone’s eyes seem to light up with dollar signs every time Trump says something belligerently stupid, and the whole network’s reputation seems to rest on the orgiastic celebration of military violence. It’s just plain awful. CNN only survives on a tabloid-like fascination with evil and the fact that it’s not as much of a propaganda organ for the Republicans as is Fox News. “Not quite as bad as Fox News” is a hell of an endorsement.
If you’ve ever felt like cutting CNN some slack, though, you need to read this profile of Jeff Zucker, the president of CNN, and the sick media culture he fosters.
We can blame our own home-grown media organizations, especially CNN, for the elevation of Trump. Forget the Russians — Jeff Zucker is the real traitor.
CNN was hardly the only news organization to provide saturation coverage of the Trump campaign. The media-measurement firm mediaQuant calculated that Trump received the equivalent of $5.8 billion in free media — known as “earned media,” as opposed to paid advertising — over the course of the election, $2.9 billion more than Hillary Clinton. Nor is CNN the only cable-news network that has benefited from Trump’s incarnation as a politician. MSNBC and Fox News each had a surge in ratings during the election that has shown no signs of slowing since then. Fox, the president’s preferred outlet, is coming off the best quarter in the history of 24-hour cable news. MSNBC, the network of the resistance, has been thriving, too, often even beating CNN during prime time.
But CNN was the first major news organization to give Trump’s campaign prolonged and sustained attention. He was a regular guest in the network’s studios from the earliest days of the Republican primaries, often at Zucker’s suggestion. (For a while, according to the MSNBC host Joe Scarborough, Trump referred to Zucker as his “personal booker.”) When Trump preferred not to appear in person, he frequently called in. Nor did CNN ever miss an opportunity to broadcast a Trump rally or speech, building the suspense with live footage of an empty lectern and breathless chyrons: “DONALD TRUMP EXPECTED TO SPEAK ANY MINUTE.” Kalev Leetaru, a data scientist, using information obtained from the TV News Archive, calculated that CNN mentioned Trump’s name nearly eight times more frequently than that of the second-place finisher, Ted Cruz, during the primaries.
He isn’t a news person at all. There’s nothing about journalistic standards in his approach. It’s not a news network, it’s a circus.
What Zucker is creating now is a new kind of must-see TV — produced almost entirely in CNN’s studios — an unending loop of dramatic moments, conflicts and confrontations. “I’ve always been interested in the news, but I’ve always been interested in what’s popular,” Zucker says. “I’ve always had a little bit of a populist take on things. Which I know is interesting when you talk about Donald Trump.”
Every circus needs its clowns, and Zucker has hired at least a dozen of them.
Lord made his CNN debut in July 2015. Two weeks later, CNN offered him a job as the network’s first pro-Trump contributor. (CNN said it was already considering Lord and that Trump’s suggestion had no effect on their decision to hire him.) Today, he is one of 12 Trump partisans on CNN’s payroll and perhaps the network’s most reliable, if mild-mannered, provocateur; he recently defended Trump’s tweet that Obama had orchestrated a “Nixon/Watergate” wiretapping plot against him, saying that the president was just speaking “Americanese.” The network sends a black town car four days a week to ferry him to Manhattan from Harrisburg and back, a three-hour drive each way.
Stop. Just stop. Turn off the entire media spectacle of 24 hour news. It’s a failure. It’s worse than a failure. It’s led us to think that entertainment (of the worst kind) is information, and has paved the road to complete corruption and ineptitude in our politics. I’d like to think that print journalism, at least, isn’t completely dead — note that I’m citing a NY Times article here — but even there the signs are on the wall. Just look at their op-ed pages, which consists largely of a parade of over-paid idiots, to see the same rot growing there.
At this point I’m more reliant on European news sources. It’s not that they’re necessarily better, but that at least they’re outside looking in at the chaos in America.
But tune out CNN. They’re tainted.
The CNN mindset:

In response to a tweet about modern Nazis spouting off about racism and doing Nazi salutes, Michael Shermer tweets back:
This is what identity politics leads to. If you identify by color & push for non-white identities, white identities will push back. Stop it. https://t.co/pwnwj7mhYu
— Michael Shermer (@michaelshermer) November 21, 2016
You hear that, black Americans? If you push back against racism, it’s your fault when the Nazis come after you. Jews, be quiet unless you want to stir them up again. Stop it, troublemakers!
His timeline is currently full of tweets in which he disingenuously points out over and over again that gosh, things are so much better for black folk now — interracial marriage is allowed, white people say they don’t mind black families living near them, etc., etc., etc. If there is incremental improvement, well, that just means you’ve got nothing to complain about.
What an ass.

In an awesome, long, and rather intense essay, Erin Horáková deconstructs Star Trek to expose Kirk Drift, a phenomenon in which the character in the original stories is shifted in our memory and perception towards a more stereotyped masculinity — and the change says some things about cultural biases. There’s a cartoon version of Kirk (which was also exaggerated in the movies) that was a womanizing, blustering, macho glory-hound which is easy to caricature, but isn’t supported by a close examination of the series. Zapp Brannigan is a version concocted in our imagination.
I found this interpretation illuminating.
I’m also trying to illustrate how different interpretations are held to very different standards of proof. Constructing an elaborate chauvinist narrative is normal and invisible as work, while other interpretive perspectives must, under ridicule, press against this “received truth.” Again and again we see female-dominated media fandoms’ interpretations dismissed as emotional and ideologically motivated. But what is all this vast effort to butch up Kirk but clear evidence of at least equally goal and emotion-driven work on the part of male-dominated sectors of fandom and popular reception? The amount of labour you have to put in to get from “Catspaw” to ‘Kirk scored!’, and from Kirk the character to Kirk the womaniser is considerable. What drives this casual or fannishly dedicated unseeing but male emotional need [7] to attack vulnerability, to uplift and venerate dominating strength, and to project their desires onto texts and from there, life? Male emotion is here, as in most spheres, parsed as neutral, rational, and just: “obvious.” Its emotional content ceases to visibly exist, because male desires are so naturalised as to seem the state of the world.
The heterosexism goggles, which derange content via chauvinist interpretive paradigms, become not just inaccurate but horrifying when we look at episodes like “The Gamesters of Triskelion.” How would you read the scene in “Gamesters” where Kirk, terrified (with some reason) Uhura will be sexually assaulted and that he’ll be able to do nothing to help her, seduces his own captor in an effort to protect Uhura and get his people out of this situation if Kirk were a woman? What about the surveillance, fear of death and fear of getting an enslaved person punished due to his non-compliance in “Bread and Circuses”? Why are we cheerleading a vision of masculinity that cannot even acknowledge vulnerability and trauma in these cases, when if this were a woman we’d see these situations as coercive and violating?
I can’t judge the details well myself — I was an obsessive fan of the show while it was on the air, which rather dates me, and when I could see them in re-runs I was a more casual viewer, and I probably haven’t seen an episode in 20 years, making me a Star Trek heathen, I guess. But what rang true was a different model for Kirk in the essay: he was patterned after Horatio Hornblower. Recalling the stories in that context puts them in a whole new light. What I know of Roddenberry also fits — he wouldn’t make an arrogant sexist the hero of his story.
Despite being an obsessive essay on a fictional character, it’s appropriately grounded.
My point here is not to argue for perfection. I certainly do not claim that Kirk and ST:TOS were flawless harbingers of third wave intersectional thinking, always and forever on point, amen (though I will stand by an argument that they do a lot of good work I’d like to see more of today, both in their context and considered in comparison to contemporary texts). There is no way for anything to be always ahead of the currents of radical thought, nor is perfection even necessarily a state of affairs to be yearned for. Social justice is in some senses a technology that must be discursively developed before it can be accessed. It is also not manifest in some immaculate person or product without sin, or in some final position where we get everything right and it stays that way, forever: it is always an evolving understanding. It is of necessity polyvocal and complicated, personal and political.
Yet there is a colossal insipidity in both patronising “this art product was good for its time” arguments and in Columbus-discovering sexism (or other forms of injustice) in the cultural materials of the past (gosh, what a find). Both can be somewhat valid positions to take, but they are often the lazy products of a false consciousness of our own differently-coded era as universally better, and of history as neatly and linearly progressive. Think not of “the arc of history,” that long single line that, god willing, bends towards justice. The position of a thing like “gender relations in 2017” is nothing like so easily determined: it is comprised of a thousand strings, some of them inching forward, some of them being looped and snarled and even pulled back, and some of them being twisted in unforeseen directions. Only in centuries will we be able to make out, or perhaps to tell ourselves that we see, that “arc.”
Those are good points to keep in mind any time you’re discussing these complicated social interactions.
Anyway, it’s really long and thorough, so set aside a little time to read it. It’s informative, though, and not just about an old TV show, but about contemporary sociocultural analysis.





