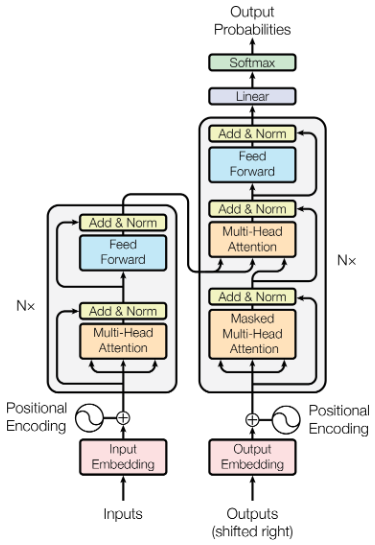
I worked on LLMs, and now I got opinions. Today, let’s talk about when LLMs make mistakes.
On AI Slop
You’ve already heard of LLM mistakes, because you’ve seen them in the news. For instance, some lawyers submitted bogus legal briefs–no, I mean those other lawyers–no the other ones. Scholarly articles have been spotted with clear chatGPT conversation markers. And Google recommended putting glue on Pizza. People have started calling this “AI Slop”, although maybe the term refers more to image generation rather than text? This blog post is focused exclusively on text generation, and mostly for non-creative uses.