This article is a continuation of my series reading “Attention is all you need”, the foundational paper that invented the Transformer model, which is used in large language models (LLMs).
In the first part, I covered general background. This part will discuss Transformer model architecture, basically section 3 of the paper. I aim to make this understandable to non-technical audiences, but this is easily the most difficult section. Feel free to ask for clarifications, and see the TL;DRs for the essential facts.
The encoder and decoder architecture
The first figure of the paper shows the architecture of their Transformer model:
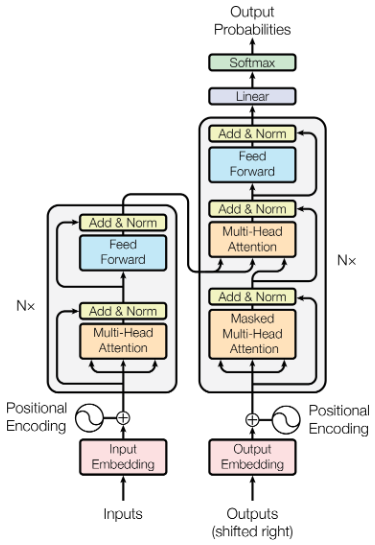
Figure 1 from “Attention is all you need”
Conceptually, this diagram shows the flow of procedure used to make predictions. Suppose we’re using the model to translate English to German. We begin with a string of English words—these are the “inputs” in the lower left of the diagram. The left side of the diagram is the encoder, which processes the inputs.
Next, we create a string of German words. We start with an empty string, but we’re going to add one word at a time. The “outputs” in the lower right of the diagram is the German translation in progress. The right side of the diagram is the decoder, which generates the next word in the German string. The decoder runs multiple times, each time generating one more word to append to the output.
I will provide a bit of external context and say that GPT-3 uses a slightly simpler architecture called a decoder-only Transformer. This makes sense, since it’s not trying to translate text, it’s just trying to generate text. (As far as I can tell, OpenAI does not describe GPT-4 as decoder-only, instead describing it as a “Transformer-based” model.) Here’s a mock-up of what the diagram would look like for a decoder-only Transformer.
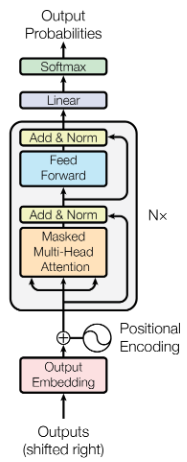
A manipulated version of Figure 1 showing the architecture of a decoder-only Transformer model.
The encoder and decoder are made of multiple constituent parts, but since we’re not trying to replicate the model, I don’t think it’s necessary to understand each constituent part. I will say that most of the components are common among neural networks, and that the actually new piece is the “multi-headed attention” box.
TL;DR: The Transformer model uses an encoder and decoder. The encoder processes input, such as an English sentence to be translated into German. The decoder looks at the translation in progress, and selects a word to be appended to the translation. The decoder repeats, adding one word at a time to the translation. GPT-3 is what’s called a decoder-only Transformer model, since it doesn’t use an encoder.
Word and positional embedding
Before we try to understand what’s new about the Transformer architecture, we should first understand the very first step. The first step is to convert language into a series of numbers. Generally, this is done by breaking down the sentence into words, and converting each word to a vector.
However, sentences aren’t just composed of words. They also have punctuation. The model also uses a special “end of sentence” symbol to mark the end of the translation. So instead of breaking the sentence down into words, it’s more technically accurate to say that the sentence is broken down into “tokens”. Some tokens are words, but not all tokens are words.
How do we convert tokens into numbers? One simple way would be to assign a number to each token in the dictionary:
“a” = 1
“aa” = 2
“ab” = 3
However, a better way is to convert each token to a very long vector:
“a” = (1, 0, 0, 0, …)
“aa” = (0, 1, 0, 0, …)
“ab” = (0, 0, 1, 0, …)
The length of this vector is going to be equal to the number of distinct tokens in your dictionary, which is probably very large. However, they embed the vectors into a smaller space, with a mere 512 dimensions, which might look something like this:
“a” = (0.3, 0.5, 0.1, …)
“aa” = (0.2, 0.1, 0.8, …)
“ab” = (0.4, 0.1, 0.2, …)
The precise vectors associated with each token will be determined when the model is trained. (And there’s nothing special about 512, by the way, that’s just the number they use in the paper.)
These vectors are modified by adding another vector based on the position. The specifics of how they do this aren’t important, and they mention trying an alternative method that was equally effective. The important thing is that we have a very long vector that will not be easily interpretable to human eyes, but somehow contains information about each token and where it is in the sentence.
By the way, in the metaphor used by neural networks, we would describe this 512-dimensional vector as a layer of 512 neurons. Neuron layers are really just vectors! When one layer of neurons is connected to another layer of neurons, that’s really just matrix multiplication.
TL;DR: Sentences can be broken down into small pieces that we call “tokens”–most tokens are words, but they may also represent other symbols such as punctuation. The first step is to convert each token into a vector. These vectors have hundreds of dimensions (or more), and they also contain information about where the token is within the sentence.
Attention
The main innovation of the paper is multi-headed attention. “Attention” represents each token’s relationship to other tokens in the sentence.
For example, in the sentence “The quick brown fox jumps over the lazy dog,” the word “jumps” should pay attention to “fox”, since that’s the thing that’s doing the jumping. On the other hand, maybe “jumps” should also pay attention to “over”, since that’s where the fox is jumping; or “dog”, since that’s the thing being jumped over. We can also come up with other kinds of attention, such as the attention between adjective and noun, or pronoun and antecedent.
“Multi-headed” attention just means that there are multiple attention processes running in parallel. Specifically, the authors use 8 parallel processes, or “heads”. We can imagine that each “head” encodes a distinct kind of attention, such as the attention between subjects and verbs, or verbs and objects. But in practice it’s probably not so straightforward. We don’t tell each head what to do, we allow them to decide for themselves when the model is trained.
Mathematically, attention is calculated through a series of vector transformations. The 512-dimensional vectors representing each token are converted into 64-dimensional vectors, using a linear transformation to be determined during training. For each token and for each head, three vectors are calculated: the “query”, the “key”, and the “value”. The model calculates the dot product between each query and each key in order to determine the “similarity” between each pair of tokens. Finally, the model outputs the similarity-weighted values of the tokens. I’m skipping a few technical details here, because I imagine this is already too technical, but if you’re interested in a detailed visual breakdown, I recommend this video on Statquest.
Why does Figure 1 have three boxes labeled “multi-headed attention”? Let’s return to our example of translating English to German. The lower left box calculates the attention between pairs of English words. The lower right box calculates attention between pairs of German words. The middle right box calculates attention between German and English words.
The attention between pairs of German tokens is “masked” because the decoder only has a partial German sentence, which it is in the process of completing. Therefore, each token is only allowed to pay attention to tokens earlier in the sentence. In contrast, the encoder is given a complete English sentence, so each token can pay attention to tokens that are either earlier or later in the sentence.
TL;DR: The authors use “attention” to represent the relationships between each pair of tokens. The attention is “multi-headed” because it keeps track of many distinct kinds of relationships. We can imagine that different heads keep track of things like subject and verb, or object and verb—although the reality is probably not so easily interpreted.
The rest
The rest of the architecture is more standard stuff. They take the attention vectors, and feed them into a more conventional neural network (i.e. the boxes labeled “Feed Forward”). The decoder’s neural network predicts the next word, and we’re done.
But… there’s one little complication. The encoder and decoder each get repeated 6 times. For example, in the encoder, we start by calculating attention vectors, and those vectors get fed to a conventional neural network. Then the output is used to calculate new attention vectors (with different model parameters from the first time), which are fed to another neural network. Then the results are used to calculate more attention vectors, which are fed to yet another neural network. This is repeated 6 times in total. The decoder is also repeated 6 times.
If you think that sounds a lot, GPT-3 has even more. The biggest GPT-3 models have 96 layers and 96 heads.
Conceptually, we can imagine that the lower layers are modeling basic concepts like syntax, while later layers are modeling advanced concepts like semantics and style. But this is just a cartoon explanation. Each layer is probably doing something that doesn’t correspond to any human-understandable concept.
TL;DR: The rest of the model architecture is more standard for a neural network. The decoder and encoder are each repeated in 6 layers, which makes it difficult to conceptually interpret what the model is doing.
I will have just one more part in this series, covering the experiment and discussion. It should get less technical from here on out.
Leave a Reply