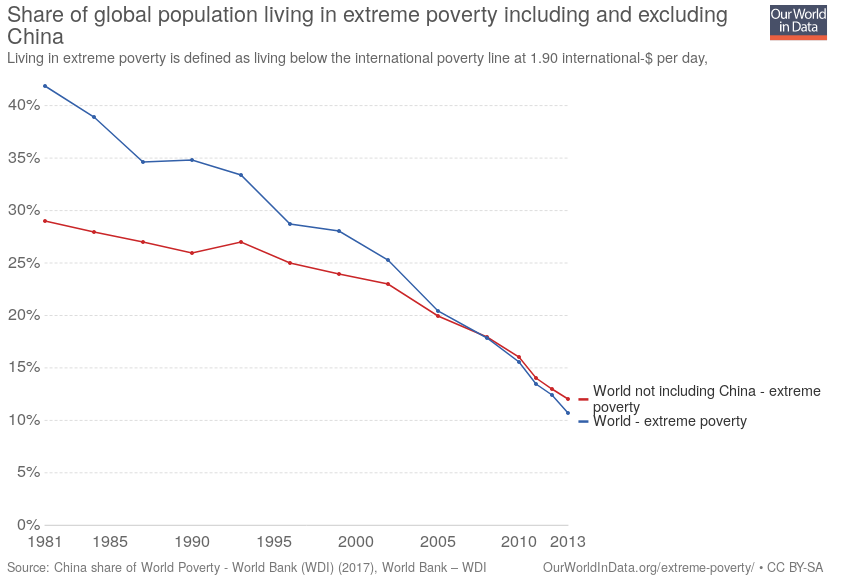
Remember that post about the Ontario election? That trend in the polls continued, putting the NDP and PC’s in a dead heat. Meanwhile, Doug Ford was sued by his late brother’s wife, was recorded trying to sell fake party memberships to guarantee he’d become the PC leader, broke election law while fundraising, and on and on. Between all the lying and even promises of a blind trust to hold off allegations of nepotism, he’s about as close as Canada gets to a Donald Trump, which should have made an NDP minority a slam-dunk.
Led by Doug Ford, Ontario’s Progressive Conservatives have secured a majority government, ending nearly 15 years of Liberal power in the province. The NDP will form the province’s Official Opposition, while the embattled Liberals were handed a substantial rebuke from voters, losing the vast majority of their seats at Queen’s Park.
“Dead heat” in the polls, alas, didn’t take into account our first-past-the-post system; the vote distribution ensured the PCs held a seat advantage, though unlike the US this wasn’t due to gerrymandering. And there was a last-minute surge in support for the PC’s, so what was originally a 36-37% share of the vote grew to 40%. Ontarians just didn’t see the problem with electing a Trump clone.
On the plus side, Ford doesn’t have access to nuclear weapons and a military.
Yes, I’m reaching. *sigh*