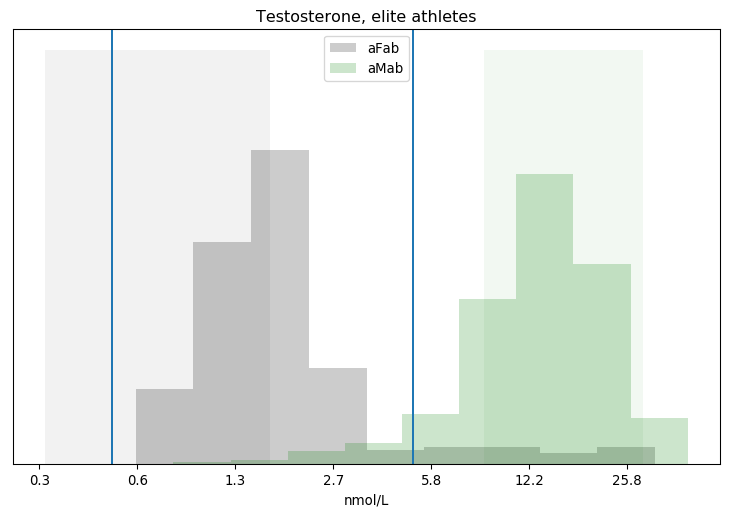
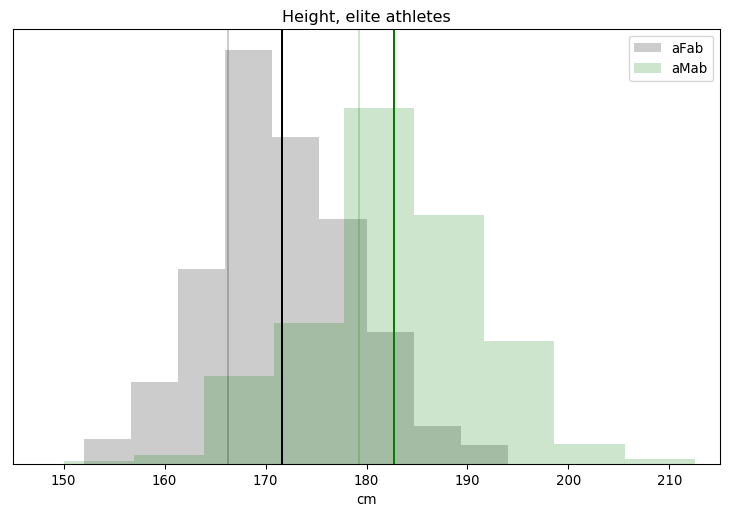
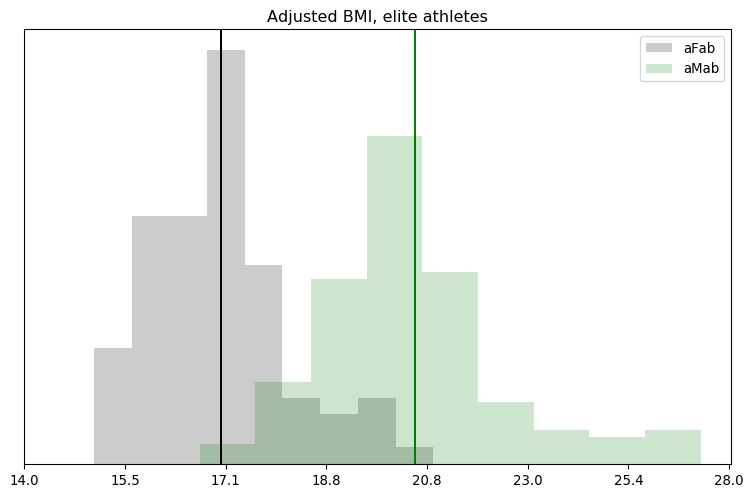
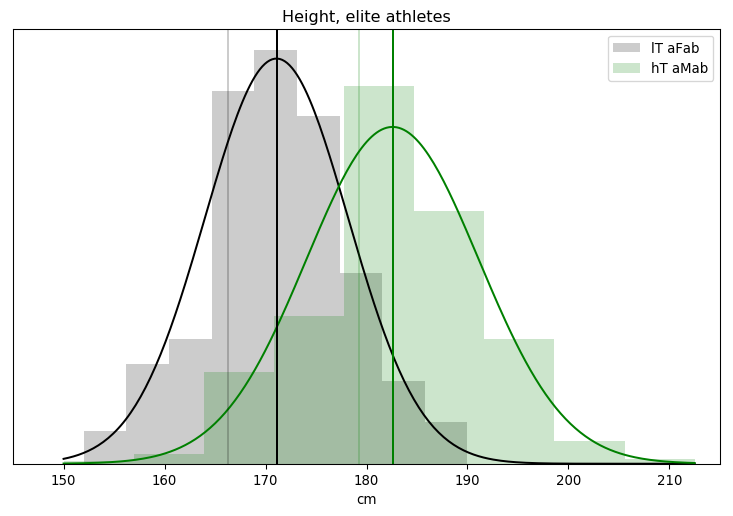
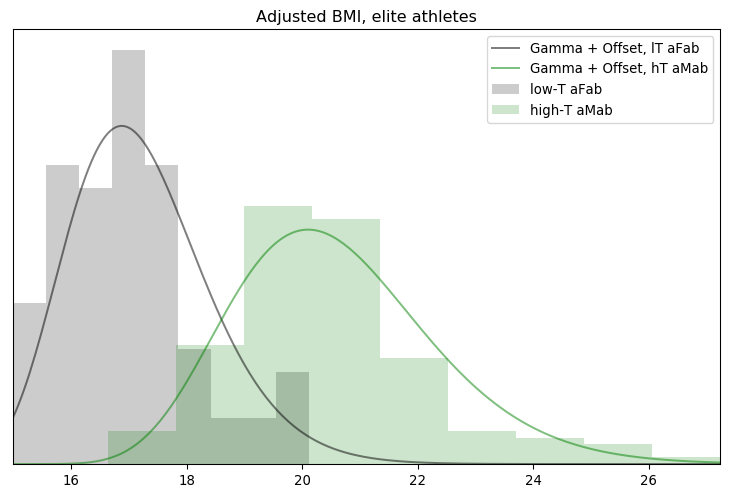
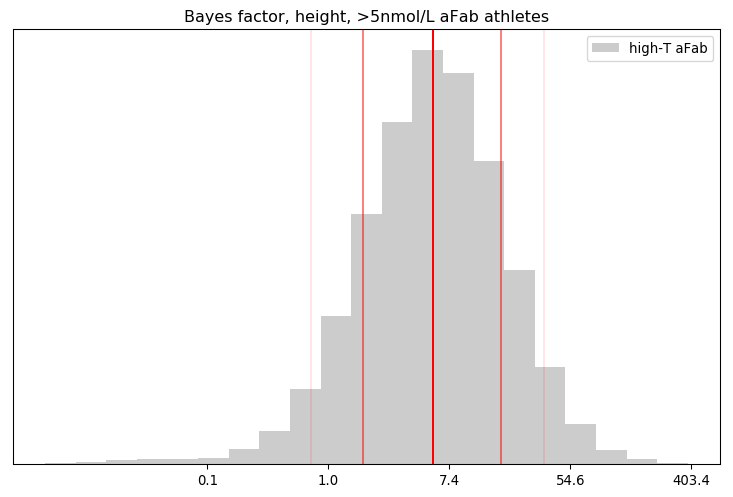
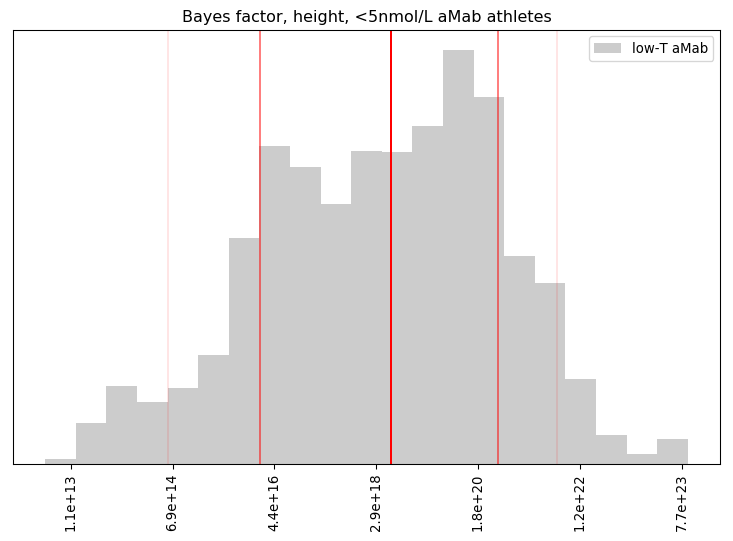
You’ve heard this meme before, that we need to block some/all transgender people from restrooms due to their inherently violent nature. It’s popular in TERF circles, in fact I’ve covered one example myself. There’s just one problem: it was invented out of thin air.
[CONTENT WARNING: anti-LGBTQI+ rhetoric]