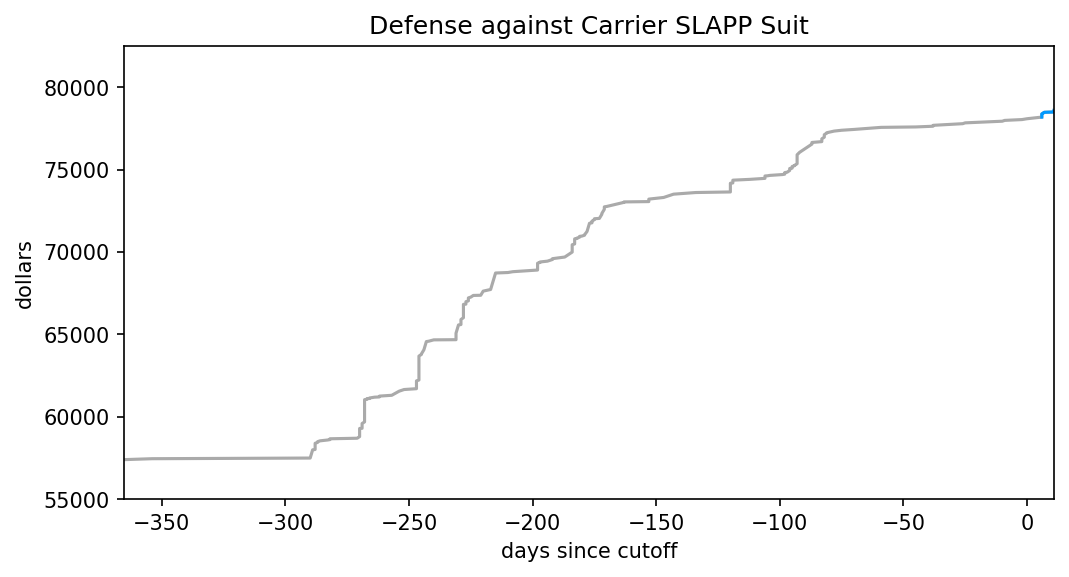
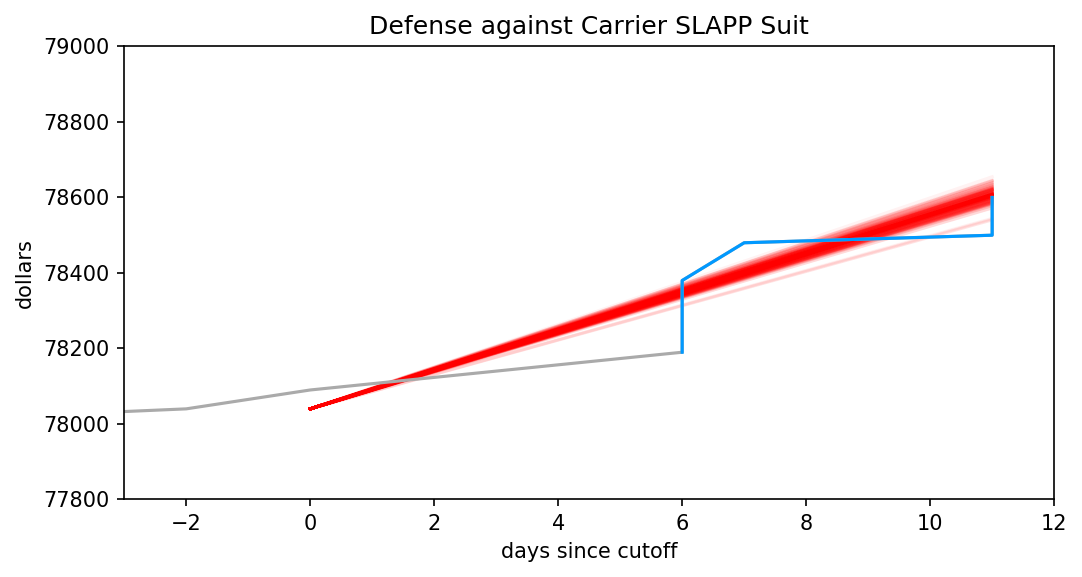
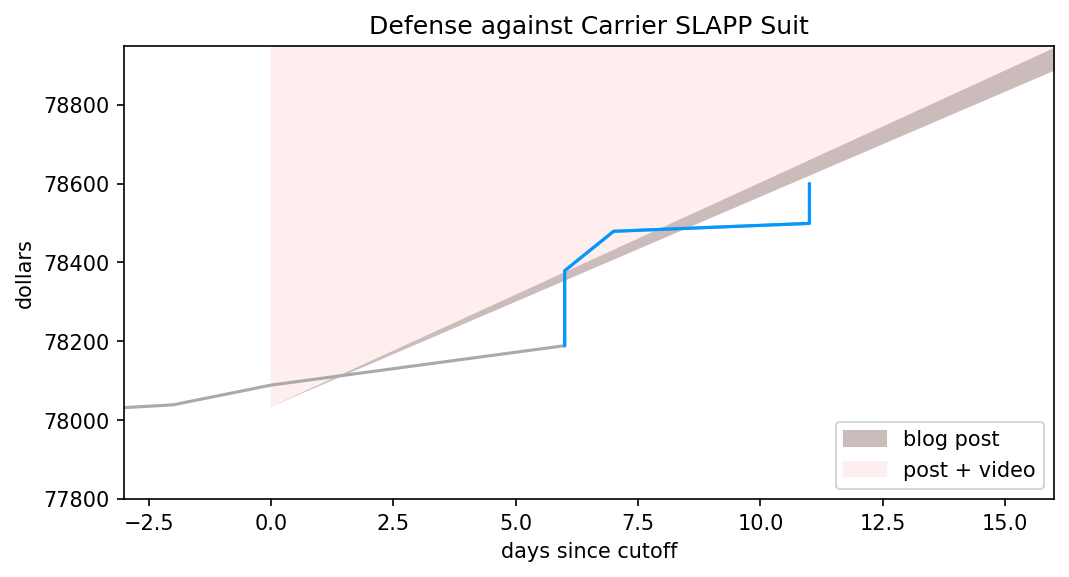
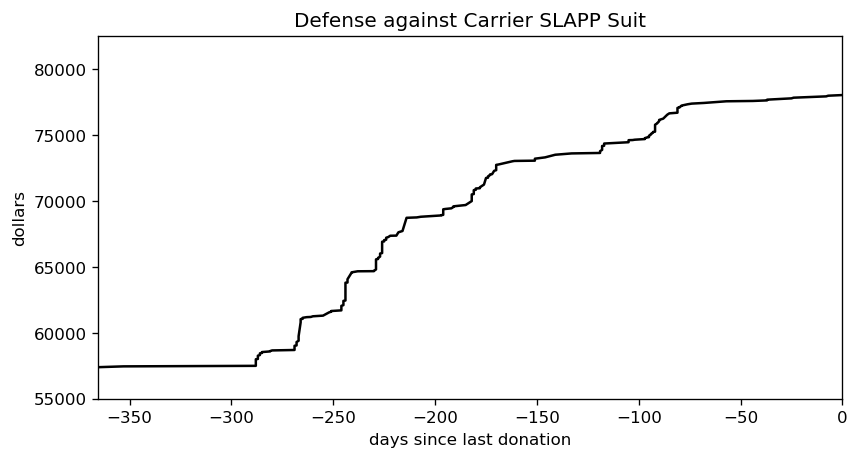
What’s a Canadian to do in honour of Juneteenth? In school I learned we were the end point of the underground railroad, which ferried slaves out of the USA in the decades before their Civil War. And, well, that was about it. Yay Canada! I guess we never engaged in slavery.
A moment’s thought suggests that is nonsense. Britain did indeed ban slavery before the USA, but even my decaying history knowledge tells me that happened in the 1800’s, about two hundred years after the Brits landed. The Atlantic parts of Canada were heavily engaged in shipping, so there’s a non-trivial chance slave ships landed there in passing at least. If only we had some historical documentation about the subject.