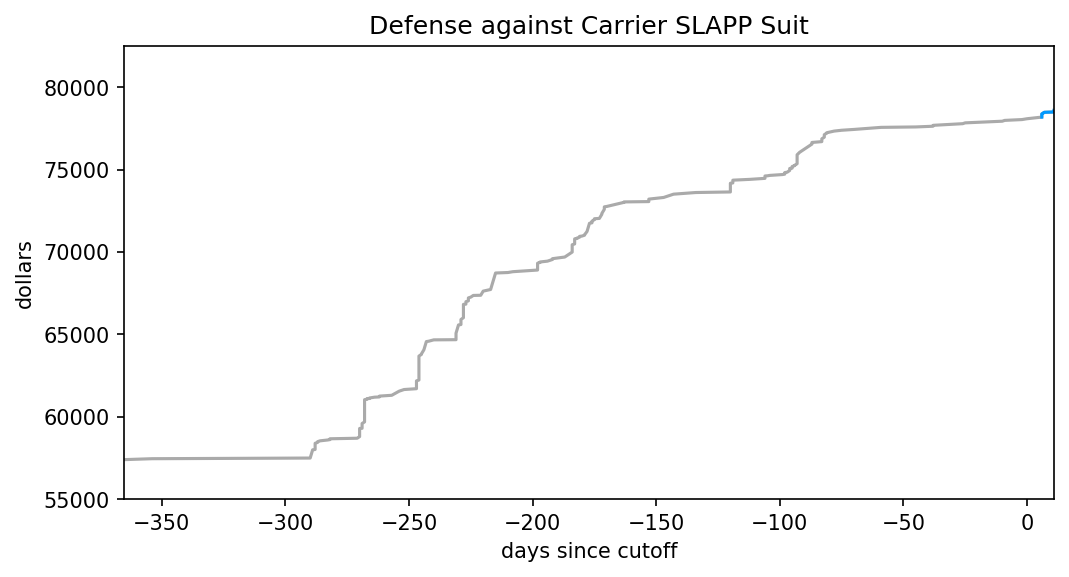
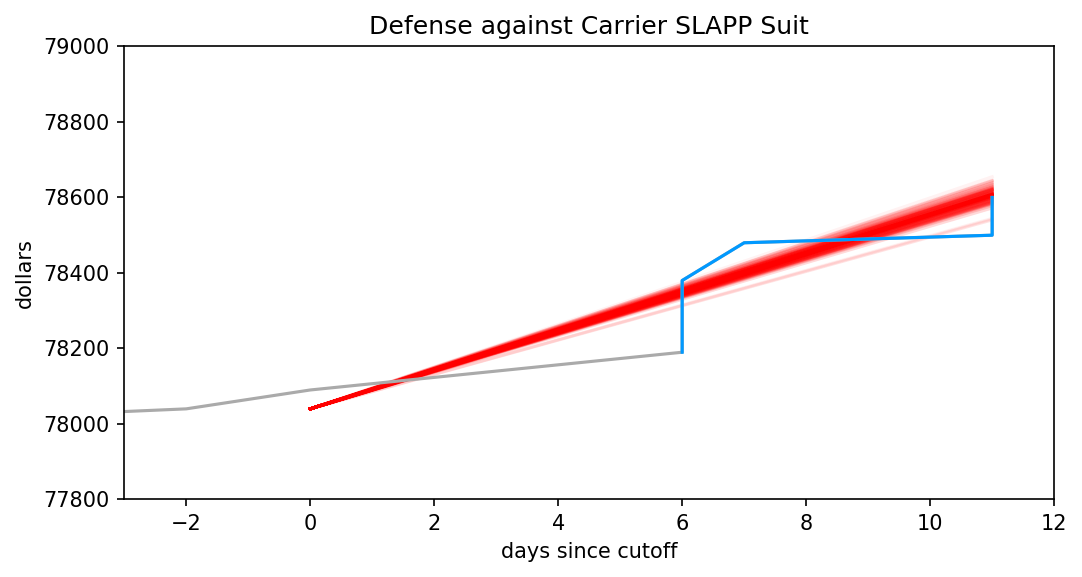
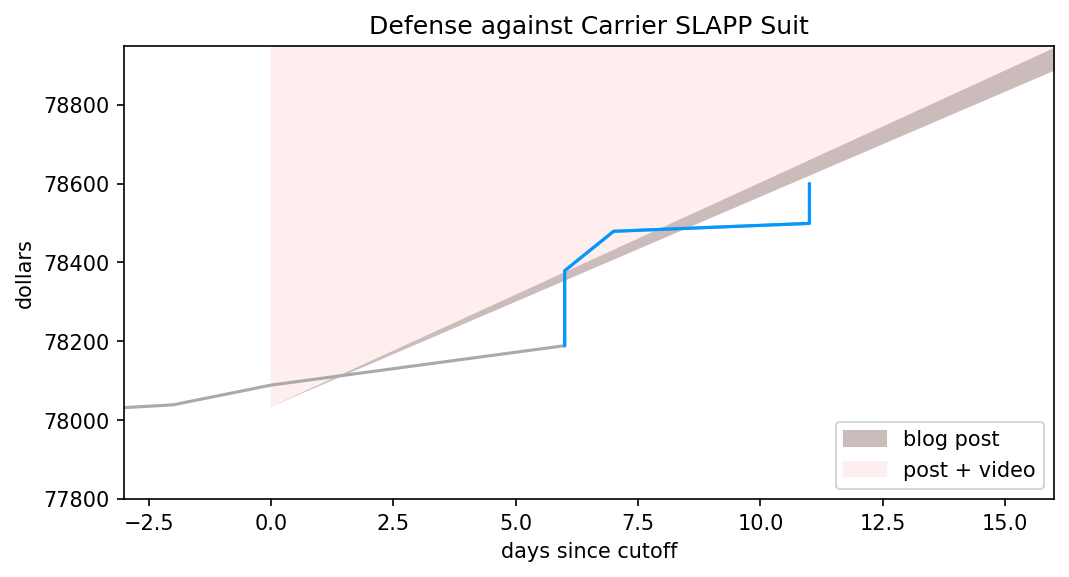
I thought I’d start my posts on Harriet Hall’s mess by starting at the extreme: are there any assertions that flatly contradict reality? There shouldn’t be too many, after all, as Hall has a background in medicine and skeptical investigation. She should have spotted them.
[CONTENT WARNING: Transphobia] [Read more…]