If a lender offered the same price (i.e. interest rate or APR) to every borrower, then it would only be a good deal for the riskiest borrowers. Lenders would have to raise prices to match the risk, and then it would only be a good deal for the riskiest of the riskiest borrowers. Lenders would have to raise prices further and further until there are no takers. This is called an adverse selection death spiral.
Therefore, lending fundamentally relies on offering different prices to different borrowers—and refusing some borrowers entirely. In other words, lending fundamentally relies on discrimination.
Lenders assess the risk of each borrower, in a process called underwriting, and make the decision whether to decline or approve, and at what price. Traditionally, underwriting has been done manually by human experts. It has also been performed by following pre-determined rules. More recently, many lenders are using machine learning to make underwriting decisions.
When we talk about discrimination, usually we’re talking about “bad” discrimination, such as sexism or racism. But in general, discrimination is just about treating different people differently, and that in itself is not bad. Nonetheless, legitimate discrimination can be used to conceal bad discrimination. Bad discrimination can also occur unintentionally, being concealed even to its purveyors. Fair lending regulations try to delineate and mitigate bad discrimination in lending.
US regulations
Disclaimers: This discussion is focused on the US context. I have industry experience in this area, but only as a data scientist, not a financial or legal expert. For further reading, please see “A United States Fair Lending Perspective on Machine Learning” (2021) by Hall et al.
In the US, fair lending is implemented by the Equal Credit Opportunity Act of 1974 (ECOA) and the Fair Housing Act of 1968 (FHA). These regulations prohibit certain kinds of discrimination on certain bases. The prohibited bases include the usual suspects like race, gender, religion, age, national origin, and a few others like marital status.
US regulation distinguishes between two kinds of discrimination. First, disparate treatment is the prototypical kind of discrimination, where you treat people differently because they’re of a particular race, religion, age, etc. For example, if a lender follows a predetermined set of underwriting rules, and the rules mention the age of the borrower, that’s disparate treatment. Another example is a human underwriter who has a gut suspicion of unmarried women. Disparate treatment is illegal, regardless of whether it is intentional or not.
Generally, disparate treatment is easier to avoid when underwriting is performed by following a pre-determined set of rules, or with machine learning. Although the decision process may be quite complicated and opaque, in principle you could just go through each of the inputs and verify that none of them are based on race, religion, etc. But if you have a human underwriter, who can say what inputs they are considering, either consciously or unconsciously?
The second kind of discrimination is disparate impact. Disparate impact occurs when decisions are made on the basis of a policy that is neutral on the surface, but which is correlated with race, religion, etc. in a way that adversely affects people of a certain class.
For example, suppose a lender decides to consider employment status—a sensible thing to consider when assessing the borrower’s ability to pay. However, they end up choosing a policy that massively disadvantages retired folks. Oops, retirement is correlated with age. So now we have disparate impact on the basis of age.
Is this illegal? The answer is not clear-cut. Disparate impact is allowed if it’s justified by business necessity, and if there isn’t an alternative that is less discriminatory.
The precise line between legal and illegal disparate impact can be hard to draw. Lenders don’t really know until regulators take them to court. Basically, lenders have lawyers to advise them on what they can do to reduce the risk of that happening.
Avoiding disparate impact
You could try to avoid disparate impact by looking at the inputs to the underwriting, and using your background knowledge to weed out bad inputs. For example, the connection between retirement and age is fairly intuitive. But you can hardly rely on this method. At some point, you need an empirical measurement of disparate impact. And that’s tricky, because lenders aren’t allowed to ask about race, religion, sex, etc.
The Consumer Financial Protection Bureau uses and recommends a process called Bayesian Improved Surname Geocoding (BISG). Basically, they infer your race/ethnicity on the basis of your surname and location. Similar processes exist to predict your gender and age. They can’t really make accurate predictions on an individual level (anyway it produces a list of probabilities rather than a single prediction), but they can use aggregate data to estimate disparate impact.
There are a variety of techniques that a data scientist can use to reduce disparate impact in a machine learning model, without too much impact on the lender’s bottom line. But without going into the techniques, let’s skip to the results. Ultimately, there will be a tradeoff between performance (i.e. ability to achieve lender’s goals, usually profit) and fairness.
The performance/fairness tradeoff
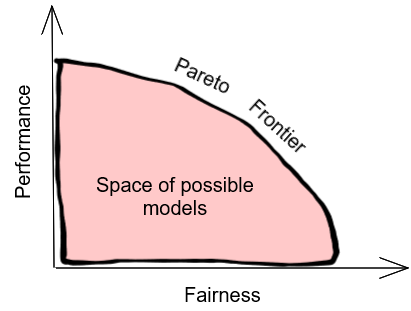
Illustration of the tradeoff between performance and fairness. Image is my own. Any sloppiness is deliberate copy protection.
Assuming that the lender hires good data scientists, they should be able to achieve the best possible performance for any given level of fairness (reaching the “Pareto frontier”). But how unfair is the lender willing to be?
Now if you’re an idealist, you might say we should be maximally fair. Any level of unfairness is unacceptable. Lenders should reduce disparate impact to zero. Right now this is basically impossible, because lenders compete with one another. If one lender decides to be 100% fair, in excess of their legal obligations, and their competitors don’t follow, the lender will be put out of business.
But suppose any degree of disparate impact were totally outlawed. Since all lenders would be bound by this rule, they wouldn’t have to worry about competition anymore. But would lending even be a viable business anymore? Perhaps the most important information to estimating someone’s ability to pay a loan is their income, but income is correlated with race. And basically everything else is correlated with race too. If lenders don’t use any information at all, won’t they suffer from the adverse selection death spiral?
Here’s another approach. The lender uses their best underwriting model, and then asks borrowers their race, religion, gender, etc., and applies a correction to completely eliminate disparate impact. A sort of financial affirmative action policy. Currently this is illegal, because disparate treatment in favor of disadvantaged groups is still disparate treatment. Would it be ethical to accept disparate treatment in order to eliminate disparate impact? And if we did, would lending still suffer from an adverse selection death spiral?
The more typical stance is to take the middle ground. Reduce disparate impact, but don’t eliminate it. And how much should we reduce it? This is a legal, ethical, and political question, but it’s one that demands a quantitative answer. And the laws simply aren’t quantitative.
Ultimately, a profit-seeking lender will weigh potential profits against the risk of regulators suing them. It all comes back to money. This is not a very satisfying conclusion to our journey through lending ethics.
So, I don’t quite get why fairness is in conflict with profitability. (Probably depends on the definition of fairness.) I’m assuming that from the business’s point of view, the most profitable strategy is to estimate people’s risk of defaulting on their loan, as accurately as possible, but the problem with this is it’s illegal to use things like race/gender/etc to predict this. But, would the predictions be more accurate if those were used? Wouldn’t the customer’s risk depend more on factors like their income? Or, is the point that income (and other useful predictors) are correlated with race/gender/etc, and so one could argue that it’s not “fair” to use them in the model? (Or, maybe for something like marital status, that does make a difference in and of itself in making someone more financially stable and able to pay their loans. So maybe that would make the model more accurate if they’re allowed to use that…)
But then what would “fair” mean? Giving everyone the same interest rate wouldn’t be “fair” because people will complain that “I always make payments on time, I should get a better rate than people who have a history of being unreliable.” Would “fair” mean the model can only evaluate people based on traits that we feel it’s “okay” to judge them for (like making bad decisions with money) instead of things that are (to some extent) out of their control (like having a low-paying job)? But then the model is really judging if someone is a good person or not, which has nothing to do with whether they’re going to reliably repay their loan, so it wouldn’t be useful to have a model like that. Or does “fair” mean you can’t use any inputs that are correlated with race? But like you said, everything is correlated with race, so then you can’t use any data at all…?
Hmm so it’s hard for me to imagine what an ideal “fair” model would be (even without taking into account the business’s profitability and how that balances with “fairness”).
@Perfect Number,
Yes. In general, basically every piece of data the lenders can get will help, or at the very least won’t hurt. That’s kind of the rule in machine learning.
But we also have more specific reasons to think that race/gender/etc. will help make predictions. Race for instance, disadvantages people above and beyond its correlation with socioeconomic class. Those disadvantages in all likelihood lead to more loan defaults. Thus, you’d expect that race would be a valuable predictor, even on top of all the credit data.
Yes, that’s one of the top factors. And income correlates with race/gender/etc., which causes (legal) disparate impact. Using income is “unfair” in the specific sense that it causes disparate impact. But it is also arguably “fair”, because income is a material part of what enables people able to pay off their loans. What is unfair, is that race/gender/etc. are correlated with income in the first place.
That’s a core question, and one that I want to inspire readers to ask.
In a sense, everything about this is unfair. It’s unfair that people with more money are given better prices. It’s unfair because how much money they have is correlated with race/gender/etc. It’s also unfair because people’s money just isn’t entirely within their control. I would say it’s unfair even when it is in their control! After all, if you made some bad decisions and I did not, it is only by chance that I am me and not you. Complete fairness is unachievable.
“Race for instance, disadvantages people above and beyond its correlation with socioeconomic class.”
Ah… well that sucks…
So the point is, it’s a complicated question, and it wouldn’t be right to use race/gender/etc directly, but no matter what you do you’ll at least be using them indirectly to some extent.