Whelp, less than thirty-eight hours after my blog post Sam Harris finally deleted that old video. However, spotting that made me realise I’d missed his explanation for why he edited the episode. That was probably by design, the description to the podcast episode drops no hint that it’s there.
As before, I’ve done some light editing, but also included time-stamps so you can check my work.
[3:17] Just a little housekeeping for today’s episode. A few episodes back, I presented audio from an event I did with Christian Picciolini in Dallas, and that was a fun event, I enjoyed speaking with Christian a lot […]
[3:51] But unfortunately, in that podcast, Christian said a few things that don’t seem to have been strictly true, and as the weeks have passed and that podcast has continued streaming I’ve heard from two people who consider his remarks to have been unfairly damaging to their reputations. This is a problem that I am quite sensitive to, given what gets done to me, by my critics. Somewhat ironically, Christian seems to rely on the Southern Poverty Law Center for much of his information, but this is an organization, as many of you know, which is undergoing a full moral and intellectual self-immolation. In fact, Christian is confused enough about the stature of that organization that he retweeted an article from the SPLC website wherein I am described as a racist recruiter for the alt-right. […]
We’re barely a minute in, and Harris has badly distorted the record. One of Picciolini’s tweets references the Southern Poverty Law Center, true, but he also cites tweets by David Duke, The Daily Stormer, Wikipedia (and before you start, I checked the citations and it’s legit), Joe Rogan, YouTube recordings of Molyneux, and his experiences talking to families with Molyneux-obsessed members. Yet that one reference to the SPLC somehow translates into “much of his information?”
Harris also misrepresents that SPLC article. They didn’t declare him to be a recruiter, self-declared members of the alt-Right said that Sam Harris helped lead them to the alt-Right.
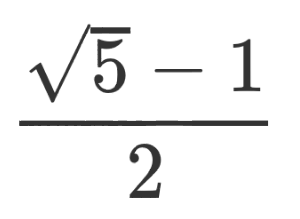

{kind=link}