Microtonal music is music that goes outside of the standard western 12-tone tuning system. There are many microtonal traditions throughout history and the world, but xenharmonic music refers to a specific modern musical tradition that makes a point of being microtonal. If you’d like to listen to examples, I have a list of popular xenharmonic artists. Xenharmonic music is associated with music theories that might be considered heterodox. Heterodoxy is good though because conventional music theory is too narrowly focused on a certain European classical music tradition, and we could use an alternate perspective.
This is part of a short series introducing xenharmonic theory. Part 1 is about the perception of sound, with a particular focus on small differences in pitch. Part 2 is about dissonance theory. Part 3 is about tuning theory. The first two parts overlap with conventional music theory, but focus on aspects that are independent of tuning. Part 3 is where we get into theory that’s more specific to the xenharmonic tradition.
I freely admit that I don’t know everything, I just know enough to point in some interesting directions. The idea here is not to write an authoritative intro to xenharmonic music theory (which might be better found in the Xenharmonic Wiki), but to write an accessible intro with a bit of a slant towards what I personally think is most important.
Frequency and pitch
Music is made of pressure waves in the air. The frequency of a wave is perceived as its pitch. And pitch is perceived on a logarithmic scale. That means the distance (known as the “interval”) between two notes is not measured by the absolute difference in frequency, but by the ratio of frequencies. For example, the distance between 100 Hz and 200 Hz is perceived to be the same as the distance between 200 Hz and 400 Hz.
A ratio of 2 is known as an octave. To measure distances smaller than an octave, I will use units of cents. There are 1200 cents in an octave by definition.
As a beginner exercise, let’s calculate the frequency ratio corresponding to a single cent. Let’s call this ratio c. So if we have two frequencies of 1 and c, those are a cent apart. 1 and c^2 are two cents apart. 1 and c^1200 are 1200 cents, apart, which is the same as an octave. That implies c^1200 = 2. Solving for c, we find that the frequency ratio of a single cent is 2^(1/1200) = 1.00057778951.
Pitch Discrimination
Cents are very small–so small, in fact, that most people can’t hear them. Generally, people can discriminate between two pitches if they’re at least 10 cents apart. Some people do better than 10 cents, some people do worse. Pitch discrimination is generally worse in the lower range, and it can depend on context too. 10 cents is called the just noticeable difference.
There are different ways to measure your just noticeable difference, which might produce slightly different results. I like this tone deafness test from The Music Lab, which plays two notes in succession, and asks you whether the second note is higher or lower than the first.
Beating
Another way to test the just noticeable difference is by playing two notes simultaneously, instead of one after the other. Pitch discrimination is significantly easier in this test, because it causes beating. Beating is an oscillation in amplitude that results from the interference of two similar frequencies. This is easy to show with one of the trigonometry identities that most people have long forgotten:
sin(a) + sin(b) = 2*sin((a+b)/2)*cos((a-b)/2)
If we play two similar frequencies a and b with equal amplitude, we will hear the average frequency ((a+b)/2), with an amplitude that oscillates at a frequency (a-b)/2. Although, what we really hear is the absolute value of the amplitude, so the perceived frequency is (a-b). That’s called the beating frequency. So if we play two notes at frequencies 500 Hz and 501 Hz, that’s a difference of about 3 cents, too small to be noticeable; but the 1 Hz beating may be fairly obvious.
Beating is based on the linear difference in frequencies, rather than the logarithmic scale. 500 Hz and 501 Hz are 3 cents apart; 250 and 251 Hz are 6 cents apart; but in both cases the beating frequency is 1 Hz.
Arguably, beating is not the same as pitch discrimination. If you hear beating, you can infer that there are two distinct pitches, but you can’t necessarily hear them directly.
One neat fact is that you can hear beating even if the two pitches are played in different ears (e.g. using headphones). This is known as binaural beating. This demonstrates that beating isn’t always a matter of similar frequencies interfering in physical space, beating can also occur when the brain combines the signals from your two ears.
The hearing range
Human ears are sensitive to frequencies in the range of about 20 Hz to 20,000 Hz. It’s not a hard cutoff, and it varies from person to person. People tend to lose hearing in the upper range as they get older.
Above the upper limit, frequencies will sound quieter and quieter until they disappear. Below the lower limit, you can still hear things, but it’s no longer perceived as pitch. For example, if you hit a drum 5 times a second, it will sound like playing a drum really fast. If you speed up the drum into hearing range frequencies, it eventually sounds like a pitch. Near 20 Hz, there’s a weird zone where it’s too fast to be rhythm and too slow to be a pitch.
Fourier analysis
Most of my discussion has implicitly been based on “pure tones”, that is, perfect sine waves. Luckily, every sound can be decomposed into the sum of perfect sine waves using a Fourier transform. The Fourier transform results in a function that tells us the phase and amplitude of each sine wave, as a function of its frequency.
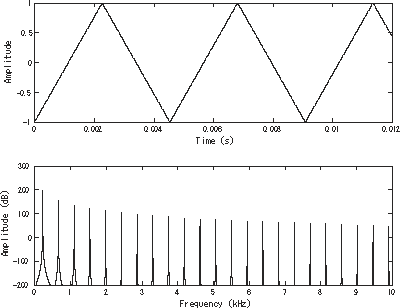
Two plots, the top showing a triangle wave, and the bottom showing the fourier transform (ignoring phase). The fourier transform shows a series of peaks, each with a small but finite width. If it were a perfect triangular wave, the Fourier peaks would have zero width. Source: Wikimedia
{kind=link}
Our ears perform something like a Fourier transform to understand what we hear. But it isn’t exactly like a Fourier transform. A Fourier transform is meant to transform a signal of infinite duration, and provides exactly one phase and amplitude per frequency. But when we hear music, we don’t perceive the same amplitudes for all of eternity, we instead perceive that amplitudes changes over time. Our perception is more similar to a “Short-time Fourier transform”, which transforms short segments of the signal, allowing amplitudes and frequencies to change over time.
The thing to understand about short-time Fourier transforms (and other similar transformations), is that there’s a tradeoff between frequency resolution and temporal resolution. If you want to hear very fast music, you need good temporal resolution. If you want to hear pitches precisely to within a few cents, you need good frequency resolution. But you can’t have perfect temporal resolution and perfect frequency resolution at the same time, it’s mathematically impossible. This is mathematically analogous to the uncertainty principle in quantum mechanics.
So human perception makes some tradeoffs, producing the facts that we’ve already discussed. We can’t distinguish pitches that are too close together. And our temporal resolution is limited to around 20 Hz, where rhythms become blurred and eventually get perceived as pitch.
Harmonics
When we play a single note with a real instrument, it’s not a perfect sine wave. So we can perform a fourier transform to determine the component frequencies of the note. To illustrate a typical case, suppose I play a note whose main frequency is 220 Hz. This note will also contain frequencies at 440 Hz, 660 Hz, 880 Hz, and so on. The lowest frequency (220 Hz) is called the fundamental frequency; 440 Hz is called the 2nd harmonic; 660 Hz is the 3rd harmonic; 880 Hz is the 4th harmonic, and so on.
Each of the harmonics will have a certain amplitude. Usually the amplitudes get smaller and smaller as you get higher in frequency. But the exact amplitude depends on the instrument. The amplitudes of the harmonics are an important part of what makes each instrument sound distinctive.
Although you may not know it, you are already adept at manipulating and hearing harmonics, because that’s how you distinguish between different vowels. An “ohhh” sound has relatively low amplitude in the higher harmonics, while an “eeee” sound has relatively high amplitude in higher harmonics.
We can convert each harmonic into cents relative to the fundamental frequency. For example, to calculate the 3rd harmonic, we take log2(3)*1200 ~ 1902 cents. The first few harmonics are 1200, 1902, 2400, 2786, 3102, 3369, and 3600 cents. The fact that most of these cent values are weird irrational numbers is important, and will come up later.
The fact that harmonics are all integer multiples of the fundamental frequency emerges from the physics of 1-dimensional oscillators, such as a vibrating string. But real instruments often have harmonics that deviate slightly from the ideal, creating inharmonicity. There are also some instruments, like drums or bells, that are based on 2-d oscillators instead of 1-d oscillators, and those are completely inharmonic. It’s also quite easy to create inharmonic instruments electronically, such as with FM synthesis.
Next part: dissonance.
We do already have set theory* which can be used for any collections of pitch classes. Simply use whatever real numbers you want as elements of a set, rather than only the integers (mod 12), and there you have it. I mean, there’s still plenty more theorizing to do from there, as always, but you can work with a foundation like that and don’t need to reinvent the wheel.
Music students do start by learning about common practice tonal theories (and 12-EDO), since creating that sort of music is usually what they’re most interested in doing. So, things outside of that are treated as somewhat more advanced topics, I guess you could say, although generally they’re covered at least to some extent in a decent undergrad music program.
Granted, the music I remember being covered in college didn’t involve microtonality for the most part. There were some things, just not much from what I recall.** Anyway, as I said, it’s fairly straightforward to deal with anything that’s mathematically possible (not just whatever’s made out of the twelve traditional notes). I mean, you may have to do some tedious calculations for a bunch of intervals that aren’t multiples of a semitone, but that sort of thing is unavoidable with microtonality. The policy is “you break it, you bought it.”
In a sense, more modern approaches like set theory are actually more “orthodox” than any of the traditional tonal theories, since we’re very much aware that those are sort of inadequate at explaining even the limited domain that they were invented for. They’re still useful for a lot of purposes, including most contemporary music, but they just don’t work as well as you might like or do everything that you might want. But it’s also not like we’ve been sitting around and making no progress for the last two hundred years or whatever. I’d say the prevailing idea is just to use what works best or is most appropriate in any given situation.
Of course, young kids (or any beginners) are introduced to the subject with the older and more traditional ideas, but it becomes clearer as you learn more that you weren’t really being given the most powerful tools to work with at first. And occasionally, the rug is pulled out from under you, because it turns out you were being fed some simplistic junk that doesn’t really help to explain very much. But I suppose for the most part it’s not so different from the way math is taught: you start with stuff that kids can pretty easily absorb and try to gradually build on that.
*An unfortunate term. It’s not the same thing as what mathematicians call set theory. The basic idea has more to do with applying some assorted bits of group theory and number theory, along with anything else that might come in handy here or there.
**That is, in the standard courses on music theory, counterpoint, and so on. I did get more exposure to it in a “world music” type of course, which wasn’t bad but was kind of a broad overview of many traditions and didn’t spend time going very deep on any one of them. Outside of classes, that’s another story entirely.
It’s much worse in practice, because most real world music is not a single note then another single note. With a bunch of other stuff going on in the music, and when you’re not in a situation where you’ve prepared to take a test in a nice friendly lab environment, everyone does much worse.
Anyway, one quick takeaway from this sort of result is that you could simplify some of the horribly complicated microtonal nonsense, by using something like 72-EDO instead, meaning one sixth of a semitone is the unit interval.
That would be a good choice, because:
(1) You can get a bunch of nice small intervals — 1/6, 1/3, 1/2, 2/3, 5/6 and 1 semitones — and any combinations of those, which are easy to work with.
(2) It fits well with the extremely common 12-EDO, since all we’re doing is just dividing a semitone after all.
(3) Almost nobody would be able to tell, if there are deviations smaller than that anyway (or wouldn’t regard those pitches as meaningfully distinct from one another).
I mean, if the composers don’t need it, performers don’t need it, and audiences don’t need it, then theorists shouldn’t have to theorize about it either. No?
Of course, there will be some people who would object, because they think of 12-EDO as a sort of unfortunate compromise (and/or historical accident) which robbed us of whatever they think perfect harmonies are supposed to be like. So they wouldn’t be very happy starting with that and rigging up a sort of general-purpose microtonal system based on it. But I don’t think musicologists can really help these people with this sort of thing…. It sounds more like the job of therapists, or maybe philosophers could jump in and try to convince them that it’s a reasonable thing to do.
As a follow-up to #2, here’s a quick calculation for multisets (in which all elements don’t need to be distinct pitch-classes, which is sometimes relevant, but you could ignore those if you wanted).
If we look at ones with three elements, there are 31 multiset-classes (12 that are actually multisets and 19 regular ones), assuming we don’t treat inversions such as major/minor triads as being equivalent, only transpositions.
Leaving aside the classes for now, the number of sets in total is (n+k-1)! / k!(n-1)!
If n = 12 and k = 3, that equals 364. Those are in 31 classes, since 30 of them have twelve distinct transpositions and 1 (the augmented triad) has only four, and 30*12+1*4 = 364
That may not seem like it would allow for very much variety, although we can obviously make an incredible amount of music just with that. And of course we don’t need to work with only three notes, which are the smallest/simplest interesting sets, but this is just meant to give a sense of how much of a difference it makes.
At any rate, if we expand it so that n = 72, there are (74*73*72)!/3!= 64,824 three-note sets, as opposed to “only” 364 of them. Now comes the slightly more abstract/challenging part….
The augmented triad would still be the only one with the transpositional/rotational symmetry required to have fewer than 12 transpositions. For a clear picture of what’s going on, it’s the only way to divide the pitch-class circle into 3 equal parts (since we’re dealing with k=3 here), and that is something you can do in either case because 3 divides both 12 and 72. So, none of the additional multisets you get which contain microtonal intervals have that sort of symmetry, which is kind of fortunate, since it would be a real pain to try to figure out what’s going on with so many different shapes.
Anyway, because of the smaller 1/6 intervals we’re using, there are 6 transpositions for each semitone that we started with. So it’s 6*12=72 for most of them and 6*4 = 24 for the augmented triad. Thus, 900*72 + 1*24 = 64,824, and you end up with 901 three-note multiset-classes in 72-EDO, as opposed to only 31 in 12-EDO. (Like you might expect, if you think about it for a second, 72 of them are actual multisett-classes and the rest are regular ones.)
That’s kind of too many to handle, if you ask me, and it only gets worse with sets that have more than three elements, which are already hard enough to make sense of when n is just 12. I mean, my basic problem is generally that there are too many things to think about and too many choices to make, not too few. But if that’s the sort of thing you’re aiming for, for whatever reason, then you do get that.
Sorry, it was supposed to be (74*73*72) / 3! =64,824. I had the whole thing written out but simplified it somewhat, then forgot to delete the “!” upstairs.
@CR,
Oh yeah, I agree that once you get down to 1/6 semitones it just doesn’t matter. Parts 1 and 2 of this series are basically working my way up to a rant about how precise integer ratios aren’t actually that important.
That reminds me of Stephen Weigel’s emoji album, which dives into horribly complicated microtonal hell, for parody’s sake. Track 10 alternates between 72 and 71 edo (and then between larger adjacent edos) to see if there’s an audible difference. I mean there is an audible difference but arguably only because we specifically drew attention to it.
@CR #3,
LOL, I get what you’re saying, but I don’t think anyone else reading these comments is likely to. Are you familiar with Polya counting theory? Counting the number of distinct chords is a perfect use case for it.
Looking forward to it. Didn’t mean to rush you.
Sorry. Of course it’s a pretty simple calculation in the end, but the explanation I tried to give along the way is probably not very enlightening for the uninitiated. I tried.
Yes. But I rarely ever think about these sorts of problems, so maybe “familiar” is pushing it.
Hmm. Just came across this, to which my answer is but Jarre and others were using vocoders for decades, well before “autotune” and though they might have different motivations the sound is very similar:
I think one of the things about the structure of the cochlea is that it can make that tradeoff *different* across the spectrum. Then of course there’s the ability of the brain to just ignore the individual numbers and integrate the lot and go “but what does that really *mean* man…”
@xohjoh2n #9
Correct, the tradeoff is different across the hearing range. When I talk about the short-time Fourier transform (STFT), it’s just to illustrate the tradeoff between frequency and temporal resolution, but it’s not a very good model for human hearing. The STFT has a constant frequency resolution in Hz, whereas human hearing has better frequency resolution in Hz in the lower range. A better approximation is the constant-Q transform, which has constant frequency resolution in cents–and therefore better resolution in Hz and worse temporal resolution in the lower range. That’s not quite right either, to describe human hearing, which has worse resolution in cents in the lower range.
To really imitate human hearing, you need a transform that’s specifically designed for that purpose. See this stack exchange question for possible solutions.
Re #8:
I didn’t watch the whole video, but I feel it’s really misleading to use “Believe” as a prototypical example of autotuning. Autotune is typically a lot more subtle than that. I’m also very skeptical of any framing that presumes music has gone downhill since the good old days. (I recommend a video by Adam Neely on the subject of autotuning.)
xohjoh2n:
There’s certainly been a lot of autotune hate. I never use it myself, but I think that sort of criticism is pretty misguided. If the idea is basically that it means we’re deprived of a relatively “natural” sound in a recording, then for one thing, it’s worth pointing out that there are many other techniques that can also significantly alter/destroy various aspects of what originally happened in a performance.
Pretty much anything that you might think to do to a recording, as a matter of fact…. Compression and limiting, equalization, de-essing, saturation, panning, reverbs, delays, phasers, various other kinds of effects, quantization, and even things as simple as amplifying/attenuating the volume of something or cutting larger things up into smaller bits or moving bits around to another spot. These kinds of things are used in every type of music you can think of (and in television, movies, etc.). Some are a little more recent I suppose, but most have been around for many decades at this point.
We could also talk about the kind of equipment being used or the location where the recording happens, since no matter what, those will always affect the output in one way or another. So when we’re looking at the whole process, it’s not like there’s even a single “original sound” that any given performance has to begin with, because that always has to be understood in relation to how it was heard or recorded (by which things and in what sort of environment) So, even if you did think we should always be aiming for a “natural” kind of sound, it’s not so easy to make sense of exactly what that’s supposed to mean.
Anyway, it’s not really a matter of one particular tool in the toolbox. I mean, you can certainly find lots of instances where any of those things I mentioned above are used in a sloppy or clumsy or heavy-handed way, which of course some people might actually like (in some cases) while others don’t. Is that more of a problem than it used to be? I doubt it. I could see how it might be the case, given how much easier it is to do these days, with computers and so forth. But I figure some are probably just more accepting of it or are more accustomed to it, when that kind of thing happens in older recordings