In my previous post, I talked about the German Tank Problem. And while discussing the frequentist approach, I defined the “unbiased” estimator. But seriously, unbiased estimators are really weird. Let me show you an example, in the form of a Monty-Hall-like problem.
Suppose that I’ve set up three closed doors A, B, and C, each with a prize behind it. Two of them have $1000, and one has $2000. Doors A and B don’t really matter, your prize is behind door C. How much is this prize worth to you? But before you answer, please, look behind one of the other doors, A or B.
Standard analysis
First, let’s briefly review the standard probability analysis. We begin by noting that there are 6 equally likely possibilities. The $2k prize can be behind A, B, or C, and you may either open A or open B. So we enumerate each possibility, and sort them by the prize we see behind door A/B.
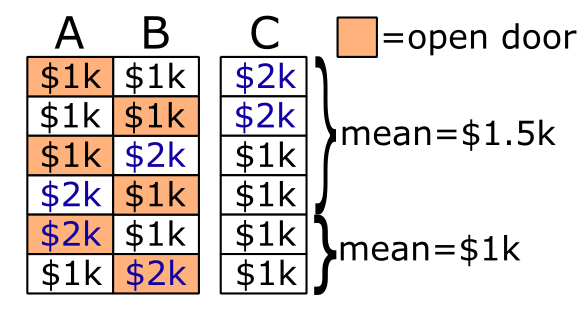
Among those where you see a $1k prize behind A/B, door C has on average $1.5k. And among those where you see a $2k prize, door C must have a $1k prize. Simple enough.
Unbiased estimator
Suppose that we want to construct an unbiased estimator of the prize. This estimator must be a function of the prize we observe behind door A/B. Let’s call this function f, and we only need to determine two values f($1k) and f($2k).
If f is unbiased, that means that for any particular value of the prize, then the average value of f is equal to the prize. And by “average” what I mean is the average across all possible choices you could have made, either door A or door B.
So, if door C has $1k behind it, then doors A and B must have $1k and $2k in some order. So the average of f($1k) and f($2k) is equal to $1k. And if door C has $2k behind it, then doors A and B must both have $1k. So the average of f($1k) and f($1k) is equal to $2k. In summary:
 + f(\$2k))/2 = \$1k")
 + f(\$1k))/2 = \$2k")
We can solve these equations with f($1k) = $2k, and f($2k) = 0.
Were you paying attention? If we observe $2k behind door A/B, the unbiased estimator predicts there’s nothing behind door C, even though we know with certainty that door C has $1k. What’s going on?
In what world does this make sense?
I’m glad you asked, because I am going to construct a world–albeit an extremely contrived one–where the unbiased estimator is in fact the correct thing to use.
First, we need to dispose of an assumption in the standard analysis. The standard analysis supposes that there are 6 possibilities and they are equally likely. But the frequentist approach is intended for situations where we don’t know the underlying probabilities. One way we can construct such a situation, is if I, the person who sets up the prizes, am malicious.
In fact, let’s suppose that I am maximally malicious. Let’s say that you have to tell me your strategy, and then I choose the prizes in such a way to maximally exploit your strategy. Or better yet, say that you have to program a bot, and I’m allowed to look at the bot’s code before setting up the doors. The bot randomly selects door A or B, but is otherwise deterministic based on the prize that it sees.
There’s another problem here that you can profit by undershooting the value of the prize. So, if I look at your bot, and decide that you’re undershooting, I may decide to reverse our positions. That is, I still choose where the prizes go, and we still use the bot that you programmed. But instead, you have to supply the prize money, and I pay you whatever the bot says.
Obviously there isn’t any strategy that gains money on average, because if there was then I’d just swap our positions. At best, you can avoid losing money, if you can even manage that. But there is a way to avoid losing money: program your bot to follow an unbiased estimator. I’m going to skip the proof of this, because it’s basically the same equations as above. You end up with a bot that sometimes makes wildly incorrect guesses, because all you care about is that the bot’s guesses are correct on average.
What even is an unbiased estimator?
All of this raises the question of what unbiased estimators are actually doing. Why is this unbiased estimator coming into our house, breaking our tables, and bringing in malicious robot-wielding game show hosts? Why do we ever use unbiased estimators at all?
The important thing to understand, is that an unbiased estimator is not the best estimate of the prize given current knowledge. Clearly, if you see the $2k prize, the current best knowledge says that door C has $1k, and that’s not what the unbiased estimator gives you. Rather, an unbiased estimator describes a robust strategy that is on average correct. By “robust” I mean that the strategy works for any set of prior probabilities–even if you play against a game show host who stacks the probabilities against you.
This requires a very precise setup, which might be why we very rarely see frequentist approaches to Monty Hall problems. But frequentist approaches are quite common in a lot of other situations, such as repeated observations of a single random variable, and when we don’t want to commit to any particular prior probabilities for our hypotheses. And though scientific research doesn’t have to deal with malicious game show hosts, there is certainly incentive for researchers to pump up their conclusions by stacking their prior probability assumptions.
Unbiased estimators aren’t the best, but they guarantee robustness against prior probabilities. I mean… at least in theory. p-hacking is a well-known set of practices to get around it. In the end there’s still lies, damned lies, and statistics.
Leave a Reply