If you follow RetractionWatch, you know that there a lot of bad papers published in the scientific literature. But there you just see the steady drip, drip, drip of bad research getting exposed, a paper at a time. If you step back and look at the overall picture, you begin to see the source. A lot of it comes from paper mills and bad actors conspiring to allow their pals to publish trash.
(PubPeer is a site that allows post-publication peer review and catches many examples of bad science.)
Nature jumped on an analysis of the people behind swarms of retracted papers on PLoS One, and exposed some of the editors. The problem can be pinned on a surprisingly small number of researchers/editors.
Nearly one-third of all retracted papers at PLoS ONE can be traced back to just 45 researchers who served as editors at the journal, an analysis of its publication records has found.
The study, published in Proceedings of the National Academy of Sciences (PNAS) on 4 August, found that 45 editors handled only 1.3% of all articles published by PLoS ONE from 2006 to 2023, but that the papers they accepted accounted for more than 30% of the 702 retractions that the journal issued by early 2024. Twenty-five of these editors also authored papers in PLoS ONE that were later retracted.
The PNAS authors did not disclose the names of any of the 45 editors. But, by independently analysing publicly available data from PLoS ONE and the Retraction Watch database, Nature’s news team has identified five of the editors who handled the highest number of papers that were subsequently retracted by the journal. Together, those editors accepted about 15% of PLoS ONE’s retracted papers up to 14 July.
Wow. These are people who betrayed the responsibilities of a professional scientist. They need to be exposed and rooted out…but they also reflect a systemic issue.
The study reveals how individuals can form coordinated networks and work under the guise of editorial duty to push large amounts of problematic research into the scientific literature, in some cases with links to paper mills — businesses that churn out fake papers and sell authorship slots.
Yeah, it’s all about money. And also about the use of publications for professional advancement.
So, about the individuals who are committing these perfidious activities…Nature identified many, but I’ll just single out one as an example.
In their analysis of PLoS ONE’s publication records, Richardson and his colleagues identified 19 researchers — based in 4 countries — who served as academic editors between 2020 and 2023, and repeatedly handled each other’s submissions. More than half of the papers they accepted were later retracted, with nearly identical notices citing concerns about authorship, peer review and competing interests.
Nature’s analysis identified 3 of those 19 editors. Shahid Farooq, a plant biologist at Harran University in Şanlıurfa, Turkey, topped the list of PLoS ONE editors ordered by the number of retracted papers that they handled. Between 2019 and 2023, Farooq was responsible for editing 79 articles, 52 of which were subsequently retracted. All of the retraction notices stated that the papers were “identified as one of a series of submissions” for which the journal had concerns about authorship, competing interests and peer review. Farooq also co-authored seven articles in PLoS ONE that were later retracted with identical retraction notices.
That’s a batting record that ought to discredit all of Farooq’s work, and ought to taint all of his coauthors and the researchers who had their work “reviewed” by him. Fortunately for all of us, he has lost all of his editorial duties.
Farooq says that PLoS ONE removed him from the editorial board in 2022, and that he subsequently resigned from his editorial positions in other journals, including Frontiers in Agronomy and BMC Plant Biology.
My editing experience has changed to not editing any paper for any publisher, as the publishers become innocent once any issues are raised on the published papers,he added.
That’s a remarkable excuse: he got caught, so it’s all the publishers’ fault.
Purging a few bad apples isn’t going to fix the issues, because the problem is only getting worse.
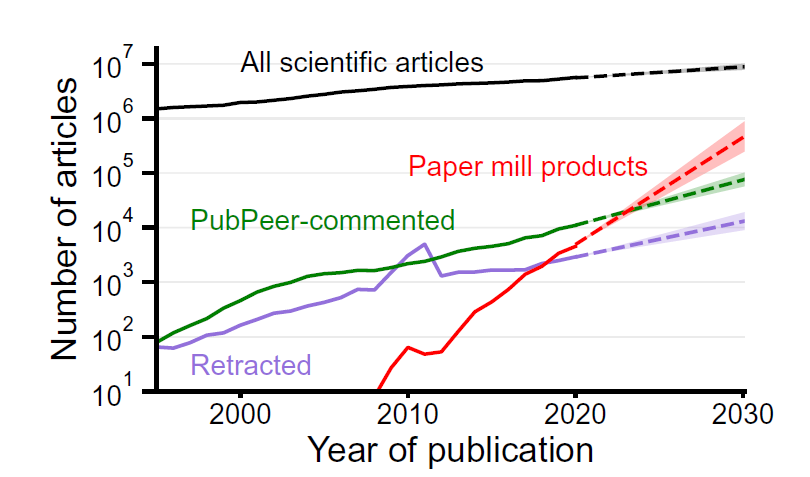
In the PNAS paper, Richardson and his colleagues compiled a list of 32,786 papers that they and other sleuths flagged for bearing hallmarks of paper-mill production, such as duplicated images, tortured phrases and whole copied sentences. Only 8,589 of these papers have been retracted. They report that the number of suspected paper-mill articles is doubling every 1.5 years — outpacing the number of retractions, which is doubling every 3.3 years.
Hey, you know, this is where AI could be really useful — I think a lot of these fraudsters are using AI to generate the AI-slop papers, but we could turn it around and use AI to detect the conspiratorial web of collaborating authors as well as the bad writing in these papers.

The notion that AI could detect bad writing made me laugh. I mean, it certainly could detect it, but identify it as bad?
AI is the weapon of the enemy. We do not use it.
I suspect AI would do well with issues relating to ” authorship, competing interests and peer review.”. Also “duplicated images, and whole copied sentences.” It might have trouble identifying ” tortured phrases” but prehaps a black list of such phrases would work.
One thing that bothered me about the article is that it doesn’t mention bad science like making up experiments, or misrepresenting actual results. For example, creationism is wildly wrong as to its content, but I don’t recalling them making the missteps mentioned above. If they could just shut up about Jesus or Noah’s Flood, they would be hard to identify by content alone. The great weakness of creationism is it doesn’t have many authors, so AI could easily identify it by the authors names.
I’m confident that AI…more specifically LLMS…could be used to screen and identify candidates for further investigation. It’s possible that Richardson et al used a statistical analyzer of some sort in their research. Given the number of articles being submitted, it could be a useful tool. You’ve got a training set. Richardson et al have already identified some criteria: “duplicated images, tortured phrases and whole copied sentence”. Of course, as #3 noted, something like “tortured phrases” would need further clarification and specification. There are probably other criteria. After that it’s just statistical analysis by an LLM or some similar tool.
However, any candidates identified by an AI would require humans to verify the results and make decisions before rejecting a paper or retracting it. AI can help but human-in-the-loop is a must.
@2 Recursive Rabbit
You’ll be passed over in favor of people who do use it, then. Machine learning is a valuable tool.
How do you think all of these papers were flagged for retraction in the first place? Especially with machine image recognition and evidence of doctored photos, that’s something a machine is much better at noticing than the human brain.
That goes a long way toward explaining the mistakes I’ve caught when I’m researching a topic. It’s been little things, like something being typed backwards, but enough to make me think that it should have been caught under peer review and doubt the veracity of the entire paper.
Yikes, it’s really disturbing that the whole chart is on a log scale. 10X paper mill papers every 5 years. Extrapolating, most papers will be fake in about ten years.
Why do we need AI for this? Clearly we can identify the problem as it is, nowwe just need to act on it. Can AI help with that?
“Why do we need AI for this?”
Nobody has made the claim that it is NECESSARY; the claim is that it could be a useful tool.
Here: “Hey, you know, this is where AI could be really useful — I think a lot of these fraudsters are using AI to generate the AI-slop papers, but we could turn it around and use AI to detect the conspiratorial web of collaborating authors as well as the bad writing in these papers.”
Wouldn’t you know it, but it was a BOTANIST that was promoting those “bad apples”.
#insert <BadSpiderJoke.h>
Erlend Meyer
#1 Volume. That’s a lot of papers to review, and the people to do the reviews have other things to do. Clearly the paper mills are flooding the system. AI could potentially help by identifying candidate papers for further investigation.
Would an AI be able to see the fnords?
@12– Not if they’re trained properly.
Not true, chrislawson. The opposite.
Actual training improves ‘seeing’, that to which you refer are after-pushes such as Musk’s recent Nazi forced bias.
(‘Training’ is just setting up the data connectome)
Detecting AI with AI is basically an arms race because you can also train your generator with an evaluation function that takes into account how much it’s fooling the detectors.
Thing is the volume of data that can be scanned.
Like, back in the day, I remember Van Vogt writing a story featuring an (uplifted) human so they could have four input feeds; one for each eye (video with markup) and one for each ear (audio). Sped up, IIRC.
Brainiac type of superhuman input processing, but only four feeds.
LLM bots are trained on basically the entire internet, and can access it much faster than a person if required. No mere four streams of data.
Basically, humans will be John Henry the “steel-driving man”; they can do it, slowly and laboriously, but the machine just does it better and quicker.
(So that’s why it’s a thing)
@14– whoosh
@John Morales #14
Dan and Chris are making a joking reference. “Fnord” is a Discordian thing and is supposedly a word that most humans are unable to consciously notice but that creates a sense of unease and confusion. Thus a ‘properly trained’ AI would also be unable to notice it.
Of course, fnord isn’t the real word but rather a placeholder used to discuss it. I’d tell you the real word, but you probably wouldn’t be able to see it, (if you could, you would have seen it in the previous paragraph).
“@14– whoosh” — yes, I know. You failed, with a whoosh.
Do you even know to what that ‘training’ refers?
Kinda mathy, up to trillions of related parameters.
—
Chakat, I read that fucking trilogy when it came out. All hail Discordia, that sort of thing.
It’s ancient. Robert Shea and Robert Anton Wilson did a fine job, first book was the best.
I know all that. I get the attempted jocularity.
Still. A well-trained LLM is one where the connectome is complex and vast. That’s it.
And, well, we’ve seen how useful a ‘forced’ after-training imposition works with Musk’s Grok.
Anyway. I know all that, it did not escape me.
(Presuming me ignorant is foolish)
Now I’m having a bunch of papers going into peer review these days. Unfortunately, I’ve had a few rejections, but luckily, they were all of the “out of scope” type.
Maths is probably not quite as susceptible to AI in general.