
I got a challenge from a creationist.
Hello, I am a Muslim.
Recently I have written a small script as a test to see how many attempts would a random mutation require to reach a target DNA Sequence.
The script simply creates a random target DNA Sequence, and keeps generating random DNA Sequences until it matches the target, and then prints the number of attempts needed.
The Result shows a very large number of attempts the longer the Sequence is.
How does evolution explain the results of this script?
The attached files are a C++ and Python versions of the script.
Thank you.
I don’t know why he needed to announce he’s a Muslim, it’s completely irrelevant.
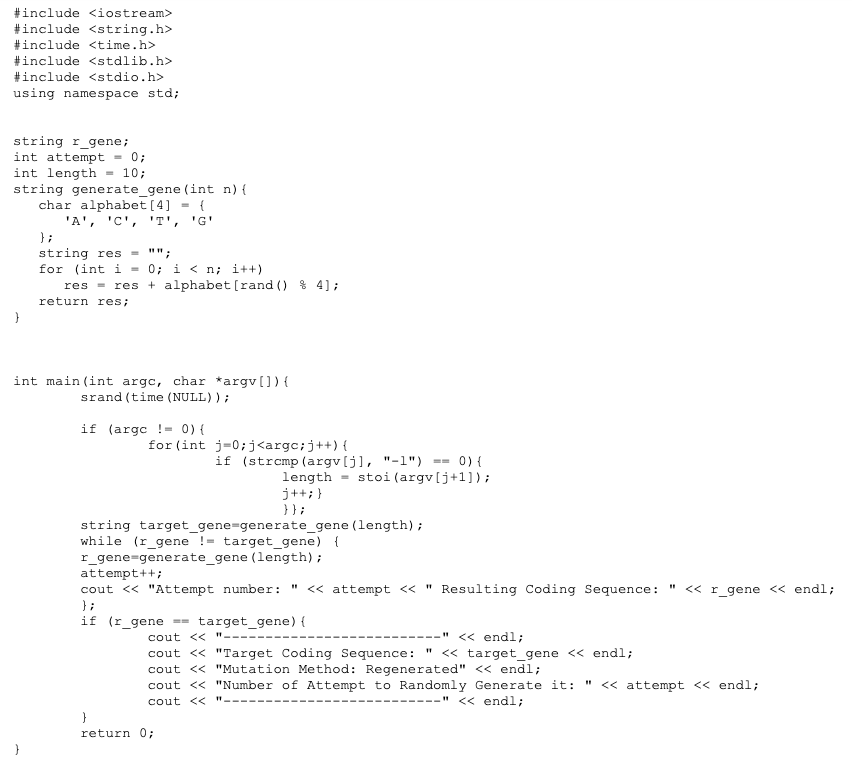
Here’s his code. I don’t think anyone will have much trouble reading it — it’s about the level of a “hello world” program in an introductory office tech class.
In C++:
In Python:

I think you can see the problem. It’s a typing monkeys simulation: there’s no selection, there’s no accumulation of small variations, on every pass it generates a totally random sequence of the desired length and compares it for identity with the search string. Of course it takes a very large number of attempts
to get the desired result!
Here’s what evolution says about it:
Evolution has nothing to say about that script, because a) evolution is not a conscious entity, b) the script has no relationship to the process of evolution, and c) the author is very stupid.

Methinks it is like a weasel.
So he’s not even up to 1986 in his coding skill.
If I send you my random password generator in Pascal, can I get it featured here, too? I can even make up really ridiculous claims about an evolutions imulator even though the code and my comments make my intent clear.
Congratulations on writing a program a first years High School CS student could write. The actual simulators are far more complex and typically require purchasing time on a super computer.
Seems like a lot of computer code just to calculate the odds of randomly generating a specific number sequence.
One of these days, when I’m feeling exceptionally not-stupid, I want to see if I can use my ancient version of Excel (Office 97, if you can believe it) and Visual Basic to produce a system of evolutionary algorithms to create an entity that performs some basic task, like finding virtual objects located within a grid, one that randomly generates mutations to a digital “genome” and tests and selects for those mutations that improve efficiency. I think I could do it with some serious brain-bending.
I did manage to work up a finite, bounded version of <a href=”https://killedbyfish.blogspot.com/2022/05/the-game-of-life.html”>The Game of Life using those tools as well as screen captures and some animation software, which, though not an evolutionary process, has more to do with living systems than this chowderhead’s Monte Carlo simulation.
Wow, spell check didn’t flag “chowderhead.” Must be an actual word.
Well, I see I borked the link. Never mind. It’s called “The Game of Life” and was developed by a British mathematician named John Conway. It uses individual cells with simple, localized rules to generate larger patterns, demonstrating some of the power of the phenomenon known as emergence.
Looks like “borked” is also a real word now.
There you go, no need to waste your time: http://www.creationtheory.org/Probability/Printable.xhtml
The example with dice.
Python code was funded by the Ministry of Silly Algorithms.
@feralboy12:
Is it possible you have “Check Spelling” unchecked?
Both “borked” and “chowderhead” get red squiggle underlines for me.
Shuffle a deck of cards. This deck of cards is unique in the history of the universe. Since this particular configuration is so unlikely, it couldn’t possibly be the result of shuffling a deck of cards.
Definitely not an expert on any of it, but this feels like it’s trying too hard to look like an empirical result or something that requires some kind of “testing” to determine the answer. If what you’re effectively doing is getting an approximation of n factorial (or whatever simple formula you want) and making it look a little fancier by doing things the hard way, then what sense does it even make to act like this is real world data or a simulation or anything like that?
Meanwhile, there’s an entire subfield of AI devoted to genetic algorithms inspired by biological evolution which uses generational modification and selection to refine solutions to physical and computational problems. We also have other AI subfields that use forms of refinement, search and selection emulating evolution without specifically calling it by that name: Simulated Annealing, Neural Networks, Weak Heuristic Stochastic Search.
wikipedia article
These folks are very boring poker players. Their process:
1. Receive and examine the deal.
2. If their hand is NOT a royal flush, then fold.
What would Muhammad code?
I’ve been a programmer for like 50 years, and I approve this analysis.
Oh my gawd. This is hilarious!
consciousness razor–
Not factorial. The probability space this script explores is 4^n, where n is the length of the gene. Other than that, though, your comment is spot on. This script is nothing but a Monte Carlo using the wrong model, and doesn’t even iterate to work out averages/distributions!
I also have some suspicion that he tried several different methods and chose the one that gave him the biggest numbers. My reason for saying so is that he sets a variable for the method and prints it out at the end. Why would he do this unless he tried several other methods? And why would he not report any of his other methods, I wonder?
Also worth pointing out, he has just invented an algorithm that is worse than bogosort (at least bogosort shuffles the array, it doesn’t populate each element randomly).
Leaving the presumably different implementations of PRNGs between C++ and Python aside, as well as the laughably bad initialization of the PRNG state in the C++ script which is trivial to compromise, and the nonsense re-seeding in the Python script…
Given that no human could have written this and thought it was a good idea:
No human could have written this, therefore:
Allah, amirite?
(Echoing everyone else here.)
This is why anyone doing a major in computer science should study at least some elementary probability theory (which I believe is normally required at universities, but probably not bootcamps and other kinds of training). All he’s asking is the expected number of Bernoulli trials of probability p to get the first success. It’s 1/p, which sounds intuitive (e.g. 2 coin flips to get heads, 6 dice rolls to get a six) although it does require a little algebra to prove it.
In his case, p=0.25^n. This 1/p=4^n, which is indeed “a very large number of attempts the longer the Sequence is.” (Note: I enjoy programming and write little simulations all the time, but wouldn’t bother for this.)
It doesn’t. Elementary probability theory does.
Great. Now maybe write a script that “simply” does anything remotely like what evolution actually does and we can have that discussion (as a baseline, let’s say Dawkin’s Weasel satisfies “remotely like” with emphasis on “remotely”).
I noticed his Python code has a useless method “multi_point_mutation” that simply returns the value of a variable, assuming its been initialized. He might want to clean it up a little before traveling to Stockholm to accept his award.
I’m guessing that we all know about the “molten sea” in 1 Kings 7:23 that’s 10 cubits across and 30 cubits around. Since π is not exactly three, but the Bible is always right 8-), the molten sea must have been an elipse. I once wrote a little program to calculate the sea’s minor axis. (I think it came out to nine cubits and one digit, though I might be misremembering that.)
It must be right since I did the math.
Me:
Therefore, it is not irreducibly complex, and Behe’s approach cannot rule out the possibility that it is the product of evolution.
He should try asking an AI. They are not even alive but they evolve.
Yeah, mathematically that sounds “right,” like it would be the nice and simple (but also wrong) thing to do.
All these creationists think that humans are special and therefore must be a specific target of evolution. They can’t come to grips with the fundamental notion of trial and error, tracking successes and eliminating failures and you get whatever you get (which happens to include us at this point in time).
Well back in [laboriously checks memory] 1986 or so I wrote some Apple BASIC code on my Apple ][+ checking the built-in random number generator (as a check to writing some DM’s aids for D&D, so I guess I’m going to hell anyway) and found it was subtly biased in that certain combinations of 2 and 3d6 were represented more frequently than expected from a true random generator.
Maybe I can dig it up and send it to him to show that the program ‘evolved’ to make certain outcomes more frequent.
(sadly 6-6-6 was NOT one of the outliers :-( )
The C++ program, if called with a set of parameters that do not include the text “-1”, will reference past the last argv[…] parameters, which is a fatal programming error. Another serious error is that the first reference to r_gene is not initialized.
Two other serious errors have already been pointed out:
1) the program is superfluous, since the answer can easily be calculated exactly using elementary probability concepts.
2) the question the program is addressing is irrelevant to the theory of evolution.
@23
which helps explain their difficulty with the evolutionary process and their relentless defense of their mythology regardless of any evidence to the contrary.
Evolution is wrong I AM SPECIAL and will live forever!!!
This email was definitely written by a programmer. Even given his flawed assumptions that don’t map to reality, this is bone-headed.
He’s posing it as a probability problem. Those can be solved without any coding whatsoever, so it’s wasted effort.
And he’s using C rand() which is not a terribly random (not cryptographically secure) number generator, so even his “random” distribution is weighted.
And because he’s not calling srand() to set his random seed, C defaults to srand(1) every time. I suppose getting the same result every time he runs his “randomized” code gives the illusion of truth.
And this is why software really sucks. Programmers trying to “solve problems.”
And it shouldn’t need saying but evolution has no target.
Damn, how has nobody thought about writing 25 lines of ugly code before? Guess this evolution thing is done for. Tell him to learn statistics next, then he can calculate the expected number of tries instead, it’s faster.
This. The whole exercise is pointless.
But also: https://rationalwiki.org/wiki/Dawkins_weasel
I don’t think so. It’s still underlining in red words like “fucknut” and “jerkface,” as well as questioning my grammar with blue underlining.
Borked and chowderhead elicit no response!
Really, if it wasn’t handy for catching my many typos, I would turn all that shit off. Computer programs should not be questioning my writing. I was writing professionally when they were still playing Pong.
@30 Thanks Nemo, wasn’t aware of that.
I’m both a programmer and a genome scientist. And yeah, as it’s been pointed out by others, this guy’s code is not at all how nucleotide sequences evolve.
Here we go again – take a complex topic you are not remotely familiar with, oversimplify it, and apply your cartoonish view. Add to that a dash of trying to get the answer which fits your ideology. As the physicists say, imagine a spherical chicken in a vacuum.
A model only refutes a claim if it (accurately) models the claim
So somebody please adjust his code to do the following:
– accept number of siblings per generation.
– initially produce that many pure random strings.
– each generation choose one of the members to be the parent of the next gen.
– produce new siblings based on the parent each with some mutations
– repeat
In choosing the parent calculate how close each string is to the target and choose the closest, or stop if an exact match is found.
Then send the code to the guy.
Ah ok, yes, Dawkins Weasel. Send him the code for that.
I was just muking around with the weasel algorithm. I added the mutation rate as a heritable value of each string, a value between .000001 and 1. I start with a rate of 1. Each new string not only applies the parent rate to its letters but also to its inherited mutation rate.
The result is interesting.
Someone once told me that he thought computer programmers were more likely to be creationists because we do the coding. I think that would make us less likely to be creationists since we haven’t seen any system crashes or physics-breaking bugs yet.
If I saw clipping IRL or a guy sink through the floor just to appear falling out of the ceiling, I’d be more likely to believe.
I don’t know why he needed to announce he’s a Muslim, it’s completely irrelevant.
Two reasons: 1) He’s trying to maintain the pretense that creationism is SCIENCE, and not tied to any specific religion; and 2) He’s trying to unite Christian and Muslim creationists against decent people of all faiths and classes.
There’s a funny observation to make that his experiment would have produced entirely the opposite result if he had respected the length of the nucleotide sequence, for e.g. humans.
Like most people here know or realize, it’s not called a pseudo random number generator for nothing as it’s not really random. It’s an algorithm designed to yield a more or less equal distribution if you were to pull numbers from it in a certain range. As mentioned if you seed (initialize) it with a specific number, you always get the same results (that’s why seeding is usually based on the system clock).
Implementations across programming languages of a PRNG can be different but they keep a state limited by a number of bits from which the next random number is generated. State in the case of the C++’s generator is the size of 32 bits. This means that every once in 2^32 (some 4 billion) iterations you run into the same state, after which the numbers start repeating themselves.
Had this developer taken his own experiment to heart, he should have selected for example the human DNA length in nucleotides, which I understand is at some 3 billion (not counting the pairing strand). It’s problematic to programmatically compare sequences this size, but if he had, he would have noticed the nucleotide sequence repeat itself to the letter, halfway the second sequence he was generating. At 2^32 exactly, each subsequent sequence would have been exactly the same.
Long story short, the longer the sequence he would have generated, the sooner they’d repeat.
Alverant@39–
If walking on water was an environmental coding error, maybe Jesus was a speedrunner?
When I was much younger and intrigued by the simulation hypothesis, I tried looking for procedural glitches like pixelation in the world. I eventually came to realise that even if the universe is a glitchy simulation, I had no reason to believe it would glitch the same way as a video game, and I would have no way of knowing what was a glitch and what was fundamental physics (quantum tunnelling would be an easy sell in Newtonian physics), and I would have no way of knowing whether it was a glitch in the universe or just a perceptual error (like the many known optical and auditory illusions). And then I realised the very idea of a “glitch” only makes sense as something not behaving the way its designer intended, which presupposes a purposeful designer, which may be yet turn out to be true but is certainly not well supported by the universe we observe.
Nemo@30–
Thanks for that link. Never thought my opinion of the ID crowd could get any lower.
(I’m sure everyone here already knows this, but it’s worth remembering that Dawkin’s weasel is not and was never meant to be an evolution simulator, just a tool to explain how random reassortment with iterated fitness checks can drive progress much faster than random reassortment alone.)
Also, as others have pointed out, he’s a terrible coder. I’m pretty basic (heh!) at it (in Python), but even I can see that a conditional loop does not need to be followed by an if statement for exactly the same condition.
I know it’s petty and not really relevant to the actual question at hand, but still, it would be nice if people trying to disprove evolution would at least show some competence in the discipline they are using for their argument.
How do these people (anti-evolutionists) get to adulthood yet remain so ignorant and foolish?
How hard is it to understand that random mutation is not the whole picture?
Ed Peters@45
Or for that matter that random mutation of every freaking base in the DNA sequence simultaneously is not any part of the picture. Have creationists ever noticed that baby looks a little like mommy and daddy? How do you explain that with the provided C++ and Python code.
In the “assume spherical cows” sense, you can look at evolution as a search through a DNA space for an “ideal” DNA string. Evolution via natural selection is therefore a search algorithm. It’s relatively inefficient compared to Genetic Modification, but it’s just a search algorithm (remember, spherical cows. Please don’t go detailed on me, this isn’t the point).
My suggestion is that he write an algorithm that randomly combines permitted characters to form web addresses and show that it would take years to find a target web page. Then he should ask how google explains this.
@mmfwmc
A critical point is that selection is not just a search algorithm. It’s not as simple as “did you get it right or not”. Selection allows partial matches to be favored and then pass down that trait to the next generation. You need inheritance and a selection that evaluates mutants and preferences those closer to the success criterion.
The idea of web addresses might be useful to demonstrate the notion that there are multiple independent viable routes, but you’d still need a way to evaluate partial success and for allowing future mutations to build on such steps. As long as each generation is created without input from the previous, we’re just not talking about evolution.