I’m not really functional for human behavior related posting, but thinking about the molecules is a hobby and I’ve been able to improve on the drawing I did in my previous post. I actually might have enough origin of life material for 4 or 5 posts. This post will be limited to the overall patterns in the drawing and the most interesting thing I’ve found in the subdomains so far. All of these posts will be like collecting puzzle pieces to the origin of life.
After more time with my drawing I’ve decided that it’s better described as a metabolic alignment of everything related to DNA that I can fit into a canvas. The file is too large for me to post on WordPress so I linked a Google documents version again. To properly figure out biological origins the sequences of genes and proteins aren’t enough. The very metabolism of these things should be considered. I’ve been careful about the structure of the alignment. Even now I’m thinking about how it could be improved with more room or simpler representation. There’s only so much I can do to compact the information down.
It’s a complex set of interconnected notes useful to anyone interested in the origin of life. This one is even cleaned up and error checked.
Cells are relationships between nucleic acids and proteins. Ribosomes and a genome. They make everything between them with the help of some atoms other than CHONPS. That is complex, but not endless. Ribose, 5 bases (A G U C dT), and 20 amino acids.
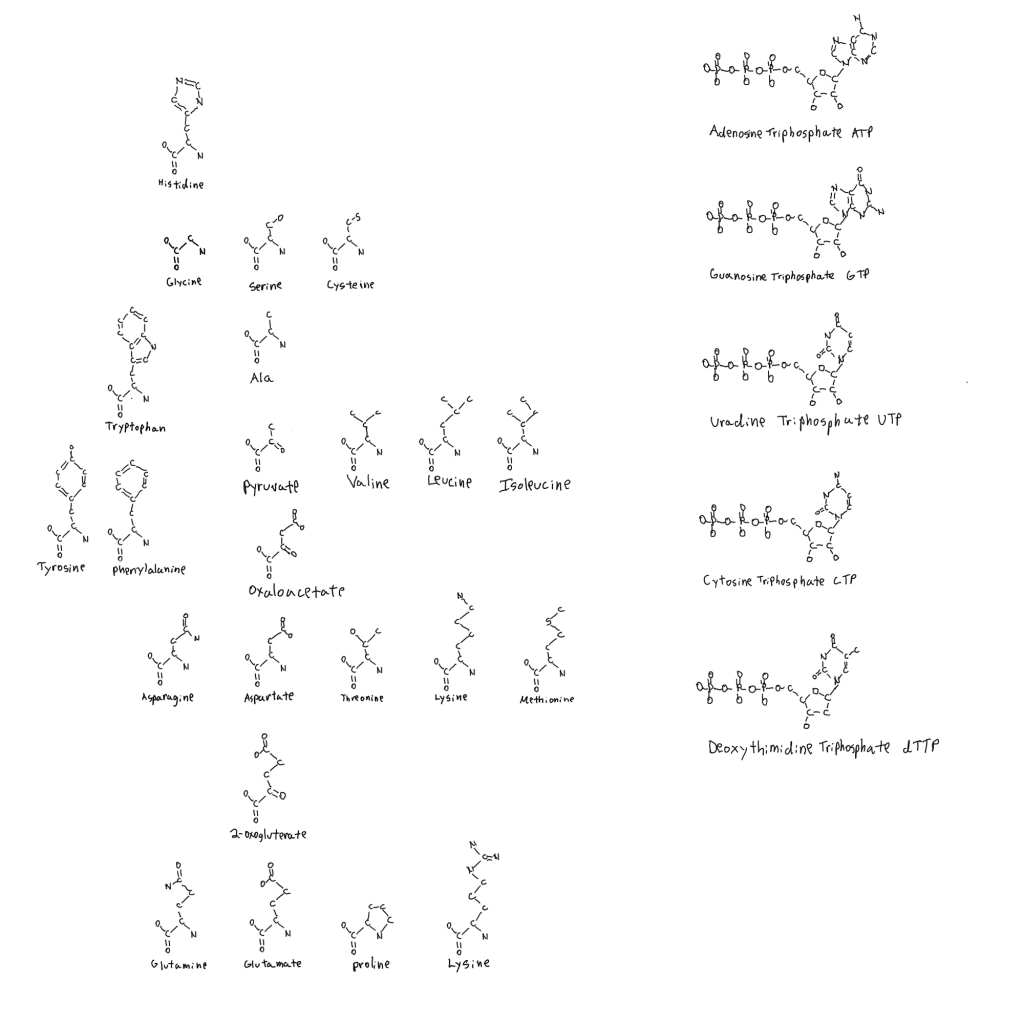
There is a legend in the top left of the linked drawing. It shows that each molecule is positioned with the protein(s) that use it. So the molecule is the product of something tangential to it shown by arrows, and the MAIN product of the reaction carried out by the protein(s) is also tangential.
Positioned right to above the molecule are other reactants and catalysts, and positioned left to below are products of the reaction.
The name of the protein(s) is given with the length in amino acids. Below that is every identified subdomain in the protein in order, and the protein domain superfamilies they belong to according to the Evolutionary Classification Of protein Domains database (ECOD).
Occasionally the molecule is below a protein when it’s a product of something already present on the figure nearby, like 10- formyl tetrahydrofolate (thought to be a storage form of formyl groups).
There is also a list of molecules that make an appearance in the top right. From 1 to 5 carbons and larger molecules.
In addition to the Purines (A G) and Pyrimidines (U C dT) are:
The amino acids Histidine, Methionine, Phenylalanine, Tyrosine, and Tryptophan.
The cofactors Thiamine (vitamin B1), Flavin (vitamin B2), Coenzyme-A (vitamin B5), the vitamin B6 group (pyridoxal…), Niacin, Folate, S-Adenosyl-Methionine and Molybdenum Cofactor.
These are boxed in blue for the amino acid product or first usable form of cofactor. Molecules that follow this box are different forms of the cofactor used by proteins made from the basic form (folate, molybdenum cofactor, vitamin B6, flavin too but I haven’t included FAD yet).
A cofactor, or coenzyme is a molecule that participates in what the protein is doing. The protein is just the polypeptide part. You can think of them as tools that often have to be reloaded when they dispense things. ATP itself is a cofactor as “energy currency”. The amino acid glutamate is a cofactor for dispensing ammonia. Cofactors also act as platforms to build things (coenzyme-A), or move things to other things (Thiamine), or move electrons around with charge so chemistry can happen (vitamin B6).
Overall Patterns
The whole thing is roughly centered on the purine (A G) pathway going from left to right and bent downward halfway through. Ribose-5P sits in the upper left corner in a small red box. The purine pathway is boxed in red as well. The products are marked with a large black A and G.
The pyrimidines are lined up and go down where the purines bend down. This is deliberate because parts of both pathways involving the amino acid aspartate and bicarbonate (HCO3) are close to one another. Large black letters mark the products similarity to the purines. From there continuing to the right I have niacin, methionine (and SAM), and coenzyme-A allowing a similar grouping of aspartate in those pathways.
Thiamine is above the purines and I’ve lined its glycine up with the one in the purine pathway.
Under ribose-5P and traveling downward are the vitamin B6 group and “aromatics” which are tyrosine, phenylalanine, tryptophan, and part of folate called PABA. All from the same pathway. The B6 group uses ribose-5P and the aromatics use erythrose-4P so they made sense together and near ribose. 5C sugar, 4C sugar…
Histidine, folate, flavin, and molybdenum cofactor branch off from the ends of the purine pathway where A and G separate. They are made from A and G, where many of the previous molecules have A attached as part of the structure.
This whole section has the feelings of “partly deconstructed purines” to it, and deconstructed ribose in the case of tryptophan.
On the whole there is a feeling of there being an aspartate accumulation after early purine evolution (if the pathways can be read like that). Maybe aspartate was the first nitrogen delivery molecule. That it’s a part of the purine pathway, used for so many cofactors and amino acids, and delivers purine nitrogen is significant.
Purines and Pyrimidines, General Patterns.
To simplify discussion of some of this I drew a separate purine and pyrimidine pathway that just focuses of the overall patterns.
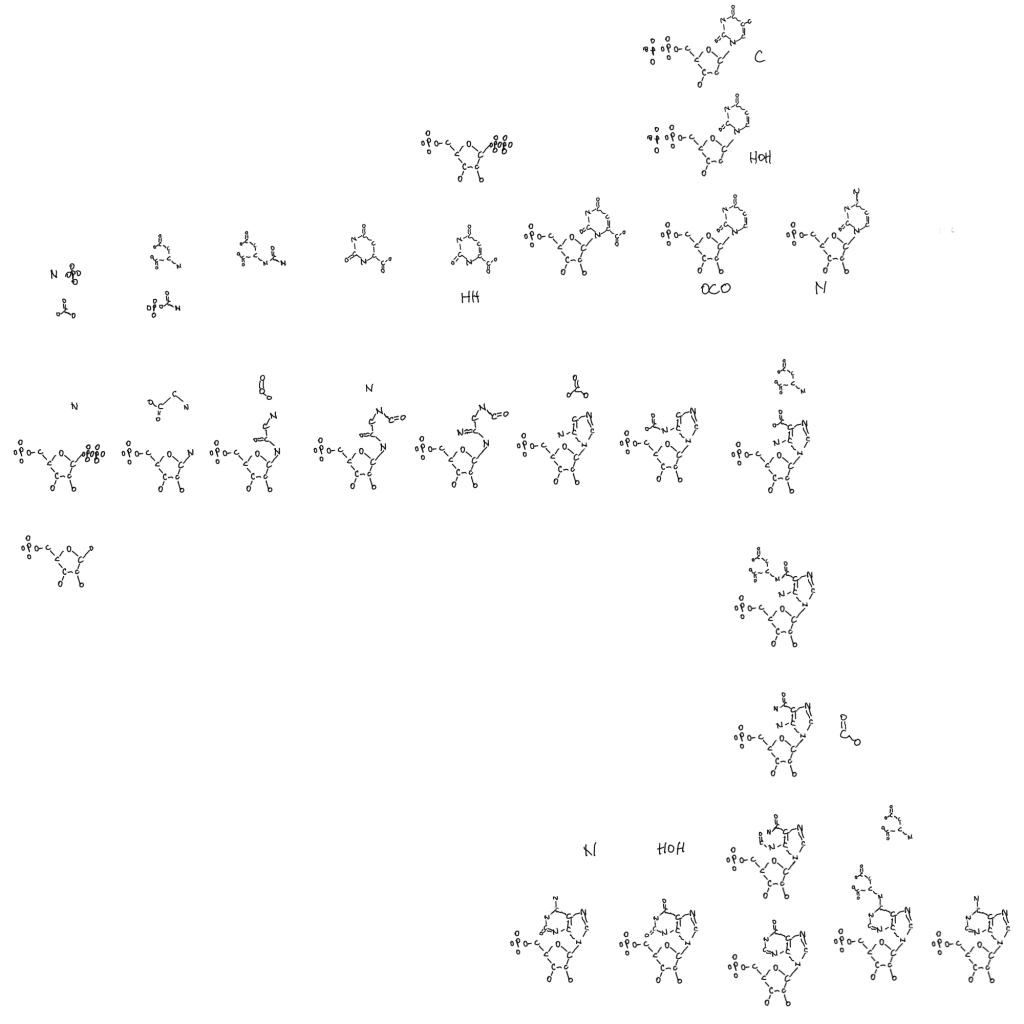
The purine pathway that makes Adenosine monophosphate and Guanosine monophosphate is unique in that it is constructed from smaller parts relative to all of the other pathways presented, outside of the ribose-5P. The biggest thing is glycine, the smallest amino acid, in the formation of the smaller 5-membered ring with ammonia and formate.
Aspartate, the amino acid used in making pyrimidines, temporarily joins in making the second ring. It attaches by it’s nitrogen and leaves as fumarate (tricarboxylic acid cycle). Bicarbonate (or carbon dioxide in later organisms) is the only other thing in the pathway left to mention. And the way it’s attached to the former glycine makes a 3-carbon segment. It’s a 2C-3C transition. Maybe it means something. Carbon fixation would be different things at different metabolic levels.
The pyrimidines have the opposite relationship to ribose-P as the purines. The ring is made first and then it is mounted on the ribose via PRPP, the form of ribose used to make nucleotides (and niacin, tryptophan, folate…). A bicarbonate and aspartate are combined and made into a 6-membered ring like the second ring of the purines. Getting aspartate and bicarbonate together in the figure makes sense when it comes to positioning the pathways together.
Both pathways make an intermediate that isn’t used for anything else. Inosine monophosphate and orotidine monophosphate. After that it’s smaller changes to get each of the final nucleotides.
The pyrimidines also lose parts of structure. Niacin removes 2 hydrogens and their electrons making a double bond. After orotate binds ribose it loses a carbon dioxide (decarboxylation). And the only place DeoxyriboNucleic Acid shows up is deoxythimidine, a loss of a hydroxal. That’s done with purines too but I didn’t need to show deoxyribonucleic acid until dT.
Maybe there’s a progression here with 5 ring ancestors and a 6 ring newcomer. Early base pairing between them. I certainly think accumulation of aspartate is a theme in both the evolution of pyrimidines and much more. In fact I think modern genomes and ribosomes are descended from something like the 5-membered thiazole in thiamine on a ribose maybe. With chemistry and base pairing between strands.
The purine pathway splits to thiamine biosynthesis at AIR, but the molecule is turned into the 6-membered ring of HMP. Not the 5-membered ring that moves carbon in making ribose (pentose phosphate pathway), the part that assists in the chemistry (more on that at the end)
Purines
I think there is a level where one can tentatively delete whole parts of proteins when thinking about precellular life in the vent. Formate, methane, bicarbonate, acetate, ammonia, phosphate were just tentatively available. There is sufficient literature support for these molecules in the vent from my point of view. As well as acetate, pyruvate, and fatty acids that make membranes.
Bio-inspired CO2 conversion by iron sulfide catalysts under sustainable conditions
Phosphate availability and implications for life on ocean worlds
I’ll only mention the most interesting thing I have found in the protein subdomains in this post.
Focusing on the purine pathway there is another maybe link to the origin of life. 3 polymers are important in life and origins: polynucleotides (DNA RNA), polypeptides (proteins), and fatty acids (~16-20 carbons, membranes and cofactors like biotin). Not only are nucleotides being made but step 2 of the purine pathway has a product, phospho-ribosyl-glycin-amide, that looks like a peptide (protein) bond on ribose between the glycine and the ribose-amide.
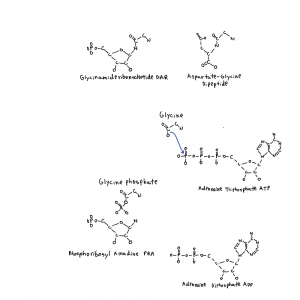
Maybe it doesn’t mean anything but get enough interesting things together and there is more room for thought.
The protein that does this step, PurD, is an example of something that I can cut a lot of things off of, just for fun. PurD is a member of the ATPgrasp family of proteins. These proteins bind an ATP, and pop a single phosphate off making an ADP.
When a protein uses ATP as “energy currency” in this way it either participates in a chemical reaction directly or it drives physical movement of a protein to do something else including chemistry. The metaphor is about doing work. Here the phosphate directly participates in attaching glycine to the nitrogen added in step 1 with a glycine-P intermediate.
The ATP-Grasp Enzymes
Structural biology of the purine biosynthetic pathway
Here is where the chopping out can happen. In the vent there is phosphate. The ATPgrasp family is essentially a bunch of phosphate dispensers and just for fun can be deleted in terms of what is more or less interesting here. That being said phosphate control seems to have evolved first/early
Structural Phylogenomics Reveals Gradual Evolutionary Replacement of Abiotic Chemistries by Protein Enzymes in Purine Metabolism
And the ATPgrasp family is related to the protein that puts aspartate on CAIR in the purine pathway which is interesting.
That’s most of the protein deleted, except for the C2 domain. It’s an interesting little piece and it’s relatives are involved in some very origins related chemistry. At the Evolutionary Classification of Protein Domains database this domain is in the “Alpha helix + beta sheet complex topology” bin. And in there it’s in the “alpha/beta-Hammerhead Barrel-sandwich hybrid” X, H and T (homology, topology) groups.
That whole T group is filled with interesting stuff but the PurD C-terminal fragment is in the “CO dehydrogenase molybdoprotein N-domain-like” F or family group. It’s relatives include not only the above CODH MO-N fragment (1C+1C) but is also in biotin carboxylase (1C manipulation), acetyl-CoA carboxylase (1C+2C, on the drawing), and pyruvate carboxylase (1C+3C).
No where else do I see a numerical progression like that. Where did aspartate come from for pyrimidines? Today cells can use pyruvate carboxylase to make oxaloacetate in initiating gluconeogenesis (glucose synthesis), which is also made into aspartate. Interesting.
This “CODH MO-N fragment” is also in 3 other purine biosynthesis genes, PurT, PurK, and PurP. They involve formate, and bicarbonate. Carboxylations use bicarbonate. The fragment is also in L Amino acid Ligase (LAL). And it is present in a few proteins without the ATPgrasp part: xanthine dehydrogenase chain B, Carbon monoxide dehydrogenase large chain (so 2 parts of CODH), aldehyde oxioreductase, quinoline 2-oxidoreductase large subunit, and 4-hydroxybenzoyl-coa reductase large subunit. I don’t know what to think about the things in this paragraph yet but I mention them for completeness.
The last thought on this fragment is that the general shape of the carboxy HO-C=O, or even the carbonyl C=O itself is maybe what it is about. I need to look at protein structures.
Ribose
I’ll finish with some thoughts on ribose. I’ve been hoping the origin of ribose comes out of this. There are different variables to consider in the abstract. The polynucleotides are the most complex part of this. Only counting genomes ribose:
1) Has 5 carbons with hydroxals on 4 and an aldehyde on one end. Each oriented the same (chirality).
2) Polymerizes using phosphate on the carbon on the end opposite the aldehyde (#5) and 2 carbons over (#3). So a 3-carbon segment for the backbone.
3) Provides a site for nitrogenous base binding at the aldehyde carbon (#1). This also provides a site for base pairing between strands.
Each of those variables is modifiable hypothetically.
Maybe there were things with erythrose-4P or shorter in the backbone of the polymer. This still allows for base pairing. With glyceraldehyde-3P maybe you still get the same but no ring.
But it’s the predictability of the ring that evolution can respond to. There is a huge diversity in things that bind ribose or things with it. Erythrose is only used in a few other places outside of the pentose phosphate pathway and the pathway that makes part of folate, tryptophan, phenylalanine, and tyrosine. And a 2-carbon segment in the backbone might be too close for 2 phosphates, steric hindrance (physically interfering).
If you get larger than ribose then you worsen the problem of self splicing, poly-RNAs of a certain size looping out and removing part of themselves and sealing the break. Removal of the #2 carbon reactive hydroxal that is removed in Deoxy-ribonucleotide genomes is bad enough, 2 would allow for more chemical possibilities than the relative stability of 1.
Getting outside of genomes carbons #2 and #3 bind amino acids in translation with class 1 and 2 aminoacyltransferases. Maybe there’s evidence of an erythrose backbone and only carbon #2 binding amino acids in the past there, but probably not.
Carbon #3 also binds phosphate in coenzyme-A and niacin in its anabolic mode (the NAD/NADP difference).
Carbon #1 binds lots of cofactors, mostly through at least 1 phosphate as the drawing shows. It also binds lots of other things for transport like sugars, membrane components, and more. Carbon #1 also binds all amino acids during the process of aminoacyl transfer in creating transfer RNA loaded with an amino acid, again on one phosphate, aminoacyl-AMP.
These carbons are also used in making signalling versions of nucleotides like cyclic AMP and cyclic GMP. The signalling functions of nucleotides is an area I’ve yet to get into in depth and integrate into this.
Finally the metabolism of ribose on the figure may provide clues to its origin. In the cofactor pathways ribose is often partially dismantled with pieces leaving, such that 4 or fewer carbons from ribose remain in the final molecule. At the least it makes me think about the assembly of ribose and its own abiotic concentration.
3C+2C?
4C+1C?
6C-1C?
3C+3C with loss of OCO?
I think the first and maybe last follows the most likely routes. 3 comes after 2 and if 2 is already around… It’s maybe thiamine related.
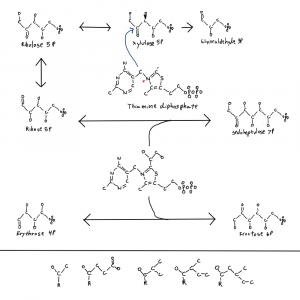
Common ancestry between the purine and thiamine pathways is possible and likely given the use of AIR in making HMP. Attaching glyceraldehyde and glycoaldehyde could be a route. Now how would acetate and pyruvate become sugars? Something between oxaloacetate, gluconeogenesis and the pentose phosphate pathway maybe.
What a terrific post — I love how you dig into refining approaches by revisiting earlier ideas. “Again, but better” really resonates — iteration is where real growth happens.
papa’s games are a popular series of time-management and cooking simulation games developed by Flipline Studios.
There is a vast variety of substances that can bind with ribose or related compounds.
At the center of hollow knight’s appeal is its tight, responsive gameplay, which balances precision with exploration. Combat is simple on the surface—slashes, jumps, and a limited set of abilities—but it demands mastery and patience.
This analysis thoughtfully explores ribose’s structural versatility, trend gamesevolutionary advantages, and biochemical centrality in genomes, cofactors, signaling, and metabolism.
In the world of cookie clicker, you’ll go from a humble baker to the owner of a multiverse empire, hiring grandmothers to bake and building global cookie factories.