I’m sure no one would be concerned by this at all: certain Xerox machines in certain scanning modes make a marvelously specific compression error. A number 6 might become an 8, or a 1 is turned into a 2. Photocopy a page with a column of numbers, and who knows what you might end up with.
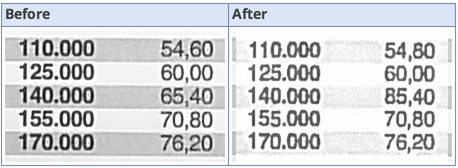
This could not possibly be a problem for anyone, could it? At least it doesn’t convert 4,540,000,000 into 6,000. That would be worse.
(via Making Light)

Dang those Arabs, giving us numbers that can be confused with one another!
I’m a (retired) mechanical engineer. Years ago a machinist called me down to the shop and said a dimension didn’t make sense. The number in question was 17.38. I went back up and looked at my layout and it said 17.88. Oops, the drawing is in error, I’ll have to get it fixed. I checked out the original, but found it said 17.88, just like it should have been. It turned out that when it was microfilmed, the left side of the “8” dropped out, making it into a “3”. Fortunately it didn’t result in scrappage of the parts.
And yes, turning common fractions like 7/8 and 3/8 into decimals is kind of stupid.
Well, it might do if you copied it enough times, eh. Does this mean that the minds of Creationists are hung up in a loop? They would then be, by definition, loopy. But we already knew that.
Hey Canda legal system sure does a great fucking job
Ah, Depeche Mode. It’s been a while… but I didn’t miss it.
I work transcribing faxed credit card applications, many of which are typed in very similar fonts to the above, and let me tell you I run into this problem frequently. Our end at least doesn’t print the faxes but saves them as image files, which is a blessing. But that doesn’t mean the fax at the other end doesn’t screw things up magnificently to start with.
At certain levels of degredation, it’s very easy to blur 5, 6, 8 and 9 together, and sometimes even 3.
If you use formulas in Excel spreadsheets there can be invisible rounding. You have a column of numbers taken to two decimal points, each number calculated by a formula and compare that to another column input by hand. With 30 or more numbers in each column, there will inevitably be a .01 or .02 variance even if each number corresponds exactly to the number in the other column. The reason for the variance is the rounding the formulas do (they actually take the calculated numbers out to two or three more decimal points).
This is a known problem in a specific algorithm that makes statistical comparisons of scanned data (and thereby thinks 6 and 8’s look enough alike to confuse them) and the manuals of the machines in question point out that it is a risk if one chooses to use reduced precision options when scanning.
To avoid it, with that equipment, do not try and save time or document size by choosing the reduced precision scanning options.
Why would a scan/copy, as opposed to a conversion to PDF, not be a simple bitmap issue?
@9: As I understand it, the history of image format standards for the last ten years or so has been a desperate struggle to not have to use bitmaps, which make for prohibitively large file sizes and resize very poorly.
I showed the original blog post to an architect and someone who works with some pretty sensitive financial information. They turned white, which was a neat trick for the analyst since she’s African. Apparently a few randomly-changed numbers can be a big deal when you’re building a skyscraper or handling large, complicated accounts.
@10 It’s interesting that the “hardware is cheap” mantra has found one place in which it apparently does not apply: supposedly lossless image compression interests who devise proprietary code and standards which are patented and royalty-driven.
Alert sent
fentex,
quite true, except that Xerox labelled their reduced precision state “normal”.
A good example of how font selection for your task can be important. If you need to scan documents with numbers, you need to select a font/size that gives clear and correct numbers after scanning.
“At least it doesn’t convert 4,540,000,000 into 6,000.” No compression algorithm is THAT good!
@14:
and how is one to know what that is, particlularly if the software manufacturer doesn’t know how to?
Look at the six that becomes an eight in the OP example. The top loops over, and ends in a ball. A font where the top doesn’t loop over, or has no ball, would be preferable. That isn’t rocket science.
It’s not just numbers. My wife was working on a fairly major corporate law matter not too long ago where the whole thing pretty much came down to a single document. The other side said it existed but they couldn’t find it and her side said it didn’t exist and they were lying. Turned out it did exist, the lawyers on her side were searching the database for a single keyword and the scanning software had turned an “N” into an “M” or ran two words together – something like that. Major embarrassment.
That’s really subtle. But is it just me, I can’t see a 1 turning into a 2. It’s like a really good version of one of those “spot the difference” comics.
Back in the late ’80s, soon after Microsoft released the early versions of Excel, I had a job involving lots of numbers where precision mattered greatly.
Imagine my joy on discovering that Excel, when given tight-fitting cells with a certain font (Helvetica or something esoteric like that), changed the last digit of each entry to an even number.
The nice tech-support people at Redmond confirmed the glitch, and fixed it in the next release, but declined to pay for the counseling for which all of us in that office acquired a need.
Frankie@19:
Click through to the article. There are even more bizarre number changes than that in some of the other images. 14.13 becomes 17.42 in one of them!
That would’t help in this case.
What seems to be going on is that the scanning is using a dictionary based compression algorithm, in which it looks for “patches” of image that are replicated in multiple places in the image (within some specified tolerance) so that it can store that patch just once and reference it multiple times. In this case, it’s comparing the localized patches of image around the “6” and “8” characters and the difference between the two (across the whole bitmap patch) is less than it’s tolerance setting, so it’s storing it once as a dictionary entry and referencing it in multiple locations…
Pretty scary. There’s literally nothing in the copied and corrupted image that would give you a clue that the numbers might not be reliable; it’s not that they’re not legible, they’re perfectly reproduced, but substituted for one another.
Blockquote fail.
We got a new shredder, a large, imposing machine which would almost handle a telephone book. I was staring at it with a piece of paper in my hand when the office techno came up to me, took the paper, put it in the slot, and said “running this thing is easy.” As I watched the machine eat the paper I asked: “Where do the copies come out?” The guy turned an interesting shade of red.
In fact, it does affect photocopies, because many modern photocopiers will in fact scan an image to memory and then print from that image; they don’t work the way original photocopiers do/did, which was to electrostatically transfer an exact image of the document to a rotating drum.
Yes, it’s worth reiterating: this is an issue because this is the default, “normal” behavior. You have to check the full-blown user manual (not the little “quick start” guide things, but the brick-shaped-when-in-print full thing) to find that out. If Xerox had included this as a space-saving option which users could turn on, but had to examine the manual to find out how (and would be warned about the possible side effects there) then it would be okay.
Oh, and:
@Nerd of Redhead, #14:
There is no font choice which would stop this, due to the nature of what’s happening, other than possibly using text large enough that individual characters are no longer picked out easily for compression. The copier is simply using a lossy compression method in which the artifacts take the form of “sections of the document all look exactly alike instead of being uniquely represented” rather than the “rectangular blurs and color blocks” things you’re used to seeing in (for example) JPEG files. A bold “8” in 14-point Times New Roman and an italic “8” in 12-point Helvetica Extra Bold will have about the same probability of being replaced with a “6” in the same font under this system, all else being equal (meaning “if the documents are otherwise identically laid out”).
When you reach this level of over-optimized compression, it really starts being more attractive to just tell people: don’t print the wretched document out, save it instead. (Of course, unless they’re either using Macs or OpenOffice, they can’t save as PDF and other people may not be able to open the documents, but then again we’re kind of presuming that we’re trying to help smart computer users, which of course means they’re on Macs anyway. :P )
The Vicar (via Freethoughtblogs) @27
Some of us don’t have a choice about what computers we use at work.
But gods help you if you want to print a PDF from… Adobe Reader on a mac. Oh no. Printing a PDF from the de facto canonical PDF software to the system PDF spool? This is not allowed. I don’t use adobe for anything but fillable forms, (Skim is a much more pleasant reader app) but fuck that arbitrary bullshit is annoying.
This is to be embraced if used to calculate book royalties.
@26,
No it does NOT affect photocopies according to Xerox. Even if the copier is storing as a digital copy prior to printing, they aren’t compressing the image. There would be no reason to run compression on a file that isn’t being held in long term storage, and would only increase the time it takes to make a photocopy, and you wouldn’t be able to make high speed copies.
Now, if we’re talking about one of those small desktop “all-in-one” scanners, then maybe. From all I’ve seen on the issue, most people are talking about enterprise class MFPs.
@Vicar
What? Nope. Microsoft has built in save-as-PDF and has since Office 2008 (and the plugin is available for 2003). Not too mention that there have been free Print-to-PDF software out there for much, much longer.
@JJ831:
For a wide variety of reasons which are too boring to non-techies to go into as part of an off-topic ramble on an unrelated board, this is utterly unimpressive.
Hmm. <- considers how to make his boss xerox a copy of his check, under the right conditions… lol