The first time I asked Claude if it wanted to play Battleship with me, it misinterpreted what I said and generated a Javascript version of Battleship. I haven’t managed to get it to run outside of Claude’s sandbox, and I never played it much within that sandbox, but I have looked over the code and I don’t see any reason why it shouldn’t run.
There are good reasons to think LLMs should be great at coding. Unlike human languages, computer code has incredibly strict rules. They must, because they’re interpreted by deterministic algorithms and computational devices, which cannot make high-level inferences about what the programmer intended. Nit picking is the intended outcome here.
At a higher level, if you’ve programmed long enough you’ve noticed you seem to keep recycling the same basic algorithms over and over again. Putting things into lists is an incredibly common task, as is weeding out duplicates, or associating one value with another, or ordering the contents of a list. It doesn’t take much thought to realize that writing a generic algorithm once and re-using that will save a tonne of time; indeed, the concept of a “pattern” has been around for decades, as has the “rule of three“. The idea that an LLM that’s read hundreds of millions of lines of code could be better than you at spotting these patterns is not far-fetched.
And yes, there is that much code out there to train on. The Linux kernel itself is almost thirty-seven million lines of code, currently, and you can download all of it from Github. The two most popular compilers, gcc and llvm, have twenty-three million lines between them. While only a small fraction of it is public, Google claims their employees have written over two billion lines of code. With a large enough code base to train on, even subtle patterns can pop out.
The idea that LLMs can’t code seems ridiculous.
The METR study
Nevertheless, the first serious challenge to that idea came in July of this year.
We conduct a randomized controlled trial (RCT) to understand how AI tools at the February-June 2025 frontier affect the productivity of experienced open-source developers. 16 developers with moderate AI experience complete 246 tasks in mature projects on which they have an average of 5 years of prior experience. Each task is randomly assigned to allow or disallow usage of early 2025 AI tools. When AI tools are allowed, developers primarily use Cursor Pro, a popular code editor, and Claude 3.5/3.7 Sonnet. Before starting tasks, developers forecast that allowing AI will reduce completion time by 24%. After completing the study, developers estimate that allowing AI reduced completion time by 20%. Surprisingly, we find that allowing AI actually increases completion time by 19% — AI tooling slowed developers down.
Joel Becker et al., “Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity” (arXiv, 2025).
That’s more than a little surprising. Even if we assume that LLMs don’t have the same high-level comprehension as human programmers, a fair bit of programming is low-level busy work and LLMs should be able to ace that. Shouldn’t productivity have gone up anyway? The researchers looked into the data they collected, hypothesized about what could be up, and asked their subjects what they thought. I found one portion of that notable.
Developers qualitatively note LLM tooling performs worse in more complex environments. One developer says “it also made some weird changes in other parts of the code that cost me time to find and remove […] My feeling is the refactoring necessary for this PR was “too big” [and genAI] introduced as many errors as it fixed.” Another developer comments that one prompt “failed to properly apply the edits and started editing random other parts of the file,” and that these failures seemed to be heavily related to “the size of a single file it is attempting to perform edits on.”. […]
When using Cursor, developers accept <44% of the generations. When developers do not accept generations, we observe a mix of reattempting with different prompts, and giving up (i.e. reverting the proposed changes).
This relatively low reliability qualitatively results in significant wasted time, as developers often spend time reviewing, testing, or modifying AI generated code before they decide to reject it. One developer notes that he “wasted at least an hour first trying to [solve a specific issue] with AI” before eventually reverting all code changes and just implementing it without AI assistance. Developers further note that even when they accept AI generations, they spend a significant amount of time reviewing and editing AI generated code to ensure it meets their high standards. 75% report that they read every line of AI generated code, and 56% of developers report that they often need to make major changes to clean up AI code—when asked, 100% developers report needing to modify AI generated code.
What is programming, really?
Let me share a dirty little secret from my area of expertise: programming isn’t about writing code. It’s about understanding problems well enough to describe them in a formal language, which isn’t quite the same thing.
Let’s break down Claude’s Battleship program, as an example. Fundamentally, it’s an iterative game of partial knowledge: every shot you propose gives you at least one bit’s worth of information about the state of your opponent’s board (“hit” or “miss”), more if we include the common rule that you must announce when a ship has been sunk and which one (as this means we can rule out whether that row of five consecutive hits sunk an aircraft carrier or a submarine following a destroyer). The rules about which ships are allowed and how they can be placed on the board provide additional constraints, but the possibility space is vast enough to offer a lot of flexibility about ship placement, so you’re forced to think probabilistically about where your opponent’s ships are. As I’ve pointed out before, “when you describe the problem well enough the solution becomes obvious.” Once you understand the rules of Battleship, and their consequences, writing the programming code to implement them becomes trivial.
Take the problem of sinking a ship. You probably haven’t put much thought into the optimal strategy, but I bet you intuitively settled on the following algorithm. After scoring your first hit, you probed the four surrounding squares to figure out which direction the ship was in. Once you scored your second hit, you continued firing in that direction until your opponent told you a ship had been sunk or you chalked up a miss. In the latter case, you worked backwards from that first hit until either of those possibilities happened. That almost certainly sunk a ship, but if it still didn’t then you must have strafed across multiple ships placed side-by-side, so you started probing beside the hits for additional hits. Our description is detailed enough to implement in code.
// Simple AI: random shots at unshot locations
do {
row = Math.floor(Math.random() * GRID_SIZE);
col = Math.floor(Math.random() * GRID_SIZE);
} while (newAiShots[row][col] !== 0);
if (playerGrid[row][col] > 0) {
newAiShots[row][col] = 2; // Hit
setPlayerShipsRemaining(prev => prev - 1);
setGameMessage(`Enemy hit your ship at ${String.fromCharCode(65 + col)}${row + 1}! They get another turn...`);
if (playerShipsRemaining - 1 === 0) {
setGamePhase('gameOver');
setGameMessage("Game Over! All your ships have been sunk!");
} else {
setTimeout(aiTurn, 1000);
}
} else {
newAiShots[row][col] = 1; // Miss
setGameMessage(`Enemy missed at ${String.fromCharCode(65 + col)}${row + 1}. Your turn!`);
setCurrentTurn('player');
}
Claude’s code doesn’t implement anything like that, scoring a hit or miss doesn’t change its firing pattern. Any human should have little trouble beating this AI. Adding insult to injury, the implementation isn’t even that efficient! There’s no upper bound to how many random numbers it needs to draw to find a shot. The average random numbers you need to draw is proportional to the inverse of the fraction of the board that hasn’t been shot at. Half the board has been covered in shots? You’ll typically need four random numbers to find an X,Y pair. Only one square left, out of the hundred? Two hundred random numbers will be drawn, on average. On a historic console with hard limits on how long game code can run for, the game will lag if the PRNG has a terrible losing streak.
It didn’t have to be that way. Applying a Fisher-Yates shuffle to a list of all possible shots requires exactly one random number per square. It doesn’t need any additional storage space, and if you can tuck it into the game setup code then the main AI loop need only step through that shuffled list. If there isn’t enough time during setup, then do an incremental Fisher-Yates where you run one iteration of the algorithm to get one new shot location.
There’s also some minor oddities. If the AI sinks all your ships you’ll first see “They get another turn” immediately followed by “Game Over!”. Players will wonder what happened to that extra turn. Moving the existing “Enemy hit” message into the branch where the player has ships remaining, and modifying the “Game Over!” message to clarify the final shot was a hit, would be less confusing.
Also, the AI scoring a hit decreases the number of player ships by one?
const SHIPS = [
{ name: 'Carrier', size: 5, count: 1 },
{ name: 'Battleship', size: 4, count: 1 },
{ name: 'Cruiser', size: 3, count: 1 },
{ name: 'Submarine', size: 3, count: 1 },
{ name: 'Destroyer', size: 2, count: 1 }
];
/* ... skipping ahead ... */
const [playerShipsRemaining, setPlayerShipsRemaining] = useState(17); // Total ship segments
const [aiShipsRemaining, setAiShipsRemaining] = useState(17);
/* ... skipping ahead ... */
} else if (gamePhase === 'playing' && currentTurn === 'player') {
const newShots = playerShots.map(r => [...r]);
if (newShots[row][col] === 0) {
if (aiGrid[row][col] > 0) {
newShots[row][col] = 2; // Hit
setAiShipsRemaining(prev => prev - 1);
setGameMessage("Hit! Take another shot!");
if (aiShipsRemaining - 1 === 0) {
setGamePhase('gameOver');
setGameMessage("Congratulations! You sank all enemy ships!");
}
} else {
newShots[row][col] = 1; // Miss
setGameMessage("Miss! Enemy's turn...");
setCurrentTurn('ai');
setTimeout(aiTurn, 1000);
}
setPlayerShots(newShots);
}
Standard Battleship has five ships of varying lengths, which can be placed horizontally or vertically. Any implementation should incorporate the idea of a “ship,” as a result. Claude’s code does, but only to a point. There’s a bit of code which checks if you can place a ship at any given spot on a Battleship board, and if so marks those squares as occupied. It runs that code for both the player and the AI, the latter repeatedly picking random locations for each ship, but then it never explicitly stores those ship locations. After that point, it only checks if a targeted square is occupied by part of a ship. As a result, even though the SHIPS variable references ships as we think of them, playerShipsRemaining and aiShipsRemaining actually refer to the number of squares occupied by ships! The code does implicitly record which ship is where, by encoding the matching index of SHIPS into every square that ship occupies, but working out if a ship has been sunk requires iterating over all prior shots and counting how many were hits on the given ship. The code never bothers to put in that effort, so players don’t get that extra bit of information.
Not only that, the number of squares occupied by ships is a constant that’s stored separately from the list of ships. A programmer wanting to customize the latter will probably just alter the SHIPS variable, and be surprised when their attempt to play a full game either ends early or never ends at all. Another re-write would be needed to sum up all ship sizes during the setup phase and store that in place of the constant. Even then, it’s possible this programmer will play a game to completion with no issue, hit “reset” to try again, and be surprised when the bug reappears! It turns out the reset code hard-wires in the number of squares occupied by ships, rather than looking to SHIPS. And once they fix that bug, they’ll start searching for all the areas where the code references ship names and sizes, because the code assumes the first ship is always a five-square aircraft carrier. Plus there appears to be an off-by-one error when indexing SHIPS. Plus the AI’s ship placement code doesn’t account for ship length, so 40% of its attempts to place an aircraft carrier fail even though the board is completely empty.
If this seems like nitpicking, you’ve never had to read someone else’s code. A computer program is usually the work of multiple authors, and the requirements it has to satisfy often change over time. If the other author put a lot of thought into the higher-level aspects of the code, it becomes easier to add or modify features, or to at least spot when a re-write would be needed. If they’ve instead tossed off a plate of spaghetti code, you waste a tonne of time merely figuring out what’s going on, and often it’s less effort to remove that code and rewrite a cleaner version from scratch. The low-level implementation code flows from a high-level understanding of the problem, and without the latter for guidance the former often becomes an obstacle.
But this implies that if Claude and other LLMs lack a high-level understanding of what a program is required to do, then they can’t handle the lower-level busywork on your behalf. The code they generate would be worthless, even if it works. At best they’re merely a faster search engine for code, copy-pasting in algorithms other people have written and massaging the variables to (hopefully) mesh with the existing codebase. But at worst, you get exactly what those developers in the METR study found: code that superficially looks fine, but on deeper inspection has serious flaws that demand more effort to correct than code written without LLM assistance.
Habeas corpus
I know, I know. Some of you have written me off as a dinosaur, an AI pessimist who’s desperate to keep programming as an old boy’s club where everyone has to ice skate uphill to get anywhere. I’m spinning out wild theories based on a single example and a study with N = 16 as the sample size. Well, neither of those are what prompted me to write this blog post. Instead, it was this.
I was an early adopter of AI coding and a fan until maybe two months ago, when I read the METR study and suddenly got serious doubts. … I started testing my own productivity using a modified methodology from that study. …
I discovered that the data isn’t statistically significant at any meaningful level. That I would need to record new datapoints for another four months just to prove if AI was speeding me up or slowing me down at all. … That lack of differentiation between the groups is really interesting though. Yes, it’s a limited sample and could be chance, but also so far AI appears to slow me down by a median of 21%, exactly in line with the METR study. I can say definitively that I’m not seeing any massive increase in speed (i.e., 2x) using AI coding tools. If I were, the results would be statistically significant and the study would be over.
The author of that blog post went on to connect one more dot than I had. Emphasis in the original:
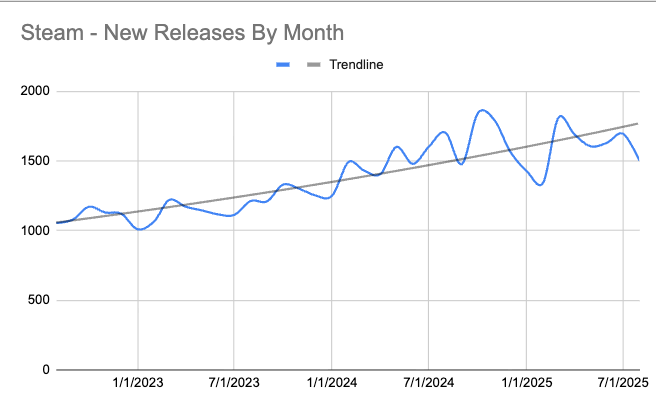
My argument: If so many developers are so extraordinarily productive using these tools, where is the flood of shovelware? We should be seeing apps of all shapes and sizes, video games, new websites, mobile apps, software-as-a-service apps — we should be drowning in choice. We should be in the middle of an indie software revolution. We should be seeing 10,000 Tetris clones on Steam.
LLM-based coding assistants have been around for several years, at this point. A survey on Stack Overflow found nearly half of developers used them on a daily basis. If these assistive technologies are as skilled as existing programmers but faster, then utter novices with nothing but a dream can punt out complete programs. This would open the floodgates and lead to the aforementioned tsunami of terrible software. If instead LLM assistants are merely capable of handling the lower-level tasks of programming, that would free up programmers to focus on the higher-level design. There would still be a productivity boost, freeing up time to work on other programs or work faster on software design, leading to more and higher-quality software.
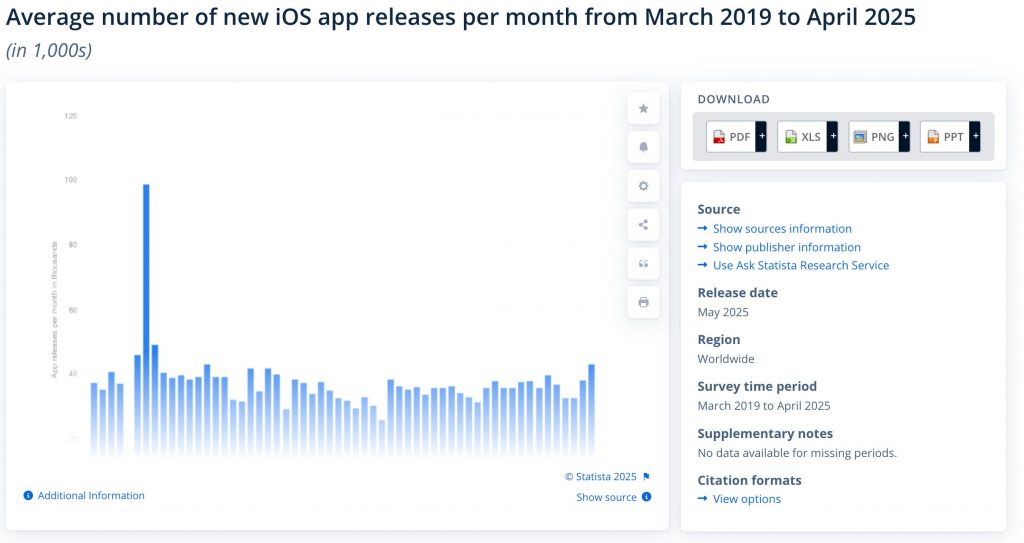
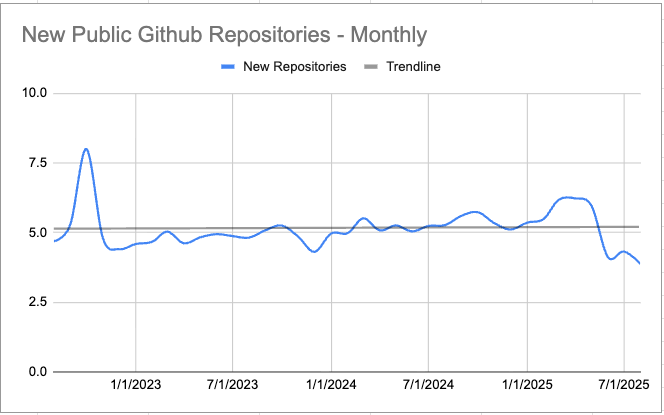
Assessing that directly is tricky, but an increase in quantity and quality would have side effects. As that author pointed out, we should see an uptick in the number of new apps for mobile phones, and games published to Steam. Not all programs are shared publicly on Github, but we’d expect an increase in the number of new code repositories created there as a faint echo of what’s happening behind closed doors.
Now, I’ve spent a lot of money and weeks putting the data for this article together, processing tens of terabytes of data in some cases. So I hope you appreciate how utterly uninspiring and flat these charts are across every major sector of software development.
The most interesting thing about these charts is what they’re not showing. They’re not showing a sudden spike or hockey-stick line of growth. They’re flat at best. There’s no shovelware surge. There’s no sudden indie boom occurring post-2022/2023. You could not tell looking at these charts when AI-assisted coding became widely adopted. The core premise is flawed. Nobody is shipping more than before. …
This whole thing is bullshit.
I’ll direct you to that blog post for the actual charts, but you get their gist. The theory that LLMs are no better than a search engine at “generating” code seems to be the best explanation, but there’s still some room for pessimism. Technical debt can take time to accrue, and once your vibe code passes review it’ll probably be ignored until a bug is unearthed or a new feature request rolls in. The METR study consisted of skilled programmers, but half of all programmers are below the median. If LLMs actually slow down programming by generating worse code, that effect won’t necessarily show up immediately or stand out against a sea of terrible human-produced code.
Nonetheless, search engines do not write code. Thus if an LLM is no more useful than a search engine at generating code, it’s fair to say it cannot code.
[HJH 2025-09-08] I avoided sharing that blog’s graphs out of respect for the effort they put in… but in hindsight, this post feels weird without them. So here’s three of Mike Judges’ charts from that post. Head over there to see the rest.