
I’ve been informed that I’ve been at war for a while. I was surprised. Apparently, Perry Marshall thinks he’s been firing salvo after salvo at me…I just hadn’t noticed.
My blog war with @pzmyers continues: https://t.co/dgjMeNvGRg
— Evolution 2.0 (@cfingerprints) January 9, 2016
Oh, OK. I would just ignore him, but he’s presenting some fascinatingly common misconceptions. One of his boogeymen is chance, and I’ve noticed that a lot of people hate the idea of chance. Uncle Fred got hit by lightning? He must have done something very bad. It can’t just have been an accident. There are no accidents!
Yes, Virginia, there are accidents, chance events, and random happenings, and solid scientific explanations have to include chance variation as a component. Even consistently predictable events on a macro scale often have a strong stochastic element to their underlying mechanisms.
Marshall, unfortunately, has this wrong idea that invoking chance is a cop-out — that randomness is bad and unscientific. So one of his salvos is a whole page of synonyms for random
, which actually do more to reveal his ignorance than expose any problems with chance.
I don’t know
I don’t care
Can we go to lunch now
POOF!
Flying Spaghetti Monster
Magic
It wasn’t God so it must have been something else
Vague un-testable assertion that excuses me from doing my science job
Oh, rubbish.
Judging a pattern of variation to be random is determined by the actual properties of the data set. Randomness is an empirical conclusion.
Here’s a simple example. I have a six-sided die. I throw it 666 times and record the result of each throw. What do you expect?
You probably expect about 111 “1”s, 111 “2”s, 111 “3”s, 111 “4”s, 111 “5”s, and 111 “6”s. But not exactly 111 of each; you expect some deviation from that number. You might actually suspect a non-random result if you got exactly 111 of each, because that would suggest some regularity. If the data showed that the first 111 throws all produced “1”, the second 111 produced “2”, etc., you’d immediately recognize that as non-random. That we can identify non-random series implies that we have some properties that we can examine to determine randomness.
We can even quantitatively predict properties of random sets of data; there are statistical theories and tests that can estimate how much variation we might expect from a given number of trials, how often and how long a run of repeated results should occur, etc. We can use these parameters to test for faked data, for instance.
To demonstrate this to beginning students of probability, I often ask them to do the following homework assignment the first day. They are either to flip a coin 200 times and record the results, or merely pretend to flip a coin and fake the results. The next day I amaze them by glancing at each student’s list and correctly separating nearly all the true from the faked data. The fact in this case is that in a truly random sequence of 200 tosses it is extremely likely that a run of six heads or six tails will occur (the exact probability is somewhat complicated to calculate), but the average person trying to fake such a sequence will rarely include runs of that length.
I’ve read whole books on the mathematical properties of randomness. I got into it for a while because of a problem that bugged me: I was watching the formation of peripheral sensory networks in zebrafish, which has both random and non-random aspects. Random: neurons grow out and branch in unpredictable ways; they don’t form a methodical pattern, like a fishnet stocking covering the animal. The specifics of branching vary from animal to animal. Non-random: the dispersal of the branches has to demonstrate adequate spacing — you shouldn’t have clumping, or large gaps in the coverage. There were rules, but they played out on a game board where chance drove the particulars.
Or on a grander scale, read David Raup’s Extinction: Bad Genes or Bad Luck?. The answer to the question is both, but luck is the best way to describe some large scale events in the history of life.
That’s the important thing: many phenomena have an underlying basis in chance, and are subsequently shaped by non-chance processes: you can’t model enzyme kinetics without acknowledging random molecular interactions given a direction by the laws of thermodynamics, for instance, or regard evolution without seeing the importance of chance variation, winnowed by selection.
And contra Marshall and a thousand other creationists, chance isn’t simply the answer we give when we don’t know what is going on. There are criteria. We have statistical tests for randomness and non-randomness, and we also use chance as a tool.
For example, one of the things I’ve been doing over this winter break is prepping some fly lines for mapping crosses my students will be doing in genetics next term. We use chance events to peek at the structure of the chromosome. Here’s how it works.
We set up flies with pairs of traits (actually, we’re doing three at a time, but that’s more complicated to explain), and we generate heterozygotes that we are going to cross to homozygotes (or in this case, because these are X-linked traits, we can cross to hemizygous males…but see, it’s already getting complicated). To keep it simple, here’s an example of a fly that is heterozygous for two genes, one for body color and one for eye color. Wild type flies are gray-bodied, and we have a recessive mutant yellow that gives the body a yellowish cast. Wild type eyes are red, and we have another recessive mutant that has white eyes.
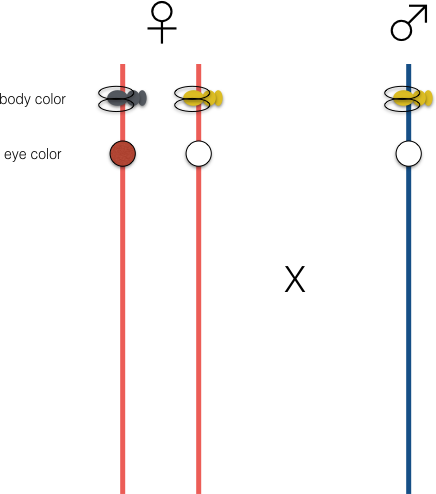
The female, on the left, has a gray body and red eyes, because those traits are dominant, but she’s heterozygous, or a carrier for both recessive traits. The male has only one X chromosome, so he can only pass on the yellow and white traits, and he is also yellow bodied and white eyed.
As I’ve drawn them, if there is no other process in play, the female can pass on either a chromosome carrying yellow and white, or a chromosome carrying the gray and red traits (Note that I’ve faded out the male contribution: he’s just donating solely recessive alleles to allow the female contribution to be expressed in the phenotype, so you can ignore him*). So by default, we’d expect that the result of this cross would be that half the progeny would be gray bodied and red eyed, and the other half would be yellow bodied and white eyed. Note that the half and half distribution is also a product of chance — in most situations, which X chromosome gets passed on is random.

But there is another process in play! During meiosis, the female can swap around portions of her two X chromosomes in a process called recombination. This is a chance event. One chromosome is broken at a random point along its length, and the other chromosome is broken at the equivalent position (a non-random choice), and they’re re-stitched together to form an intact chromosome with a different arrangement of the alleles. That allows some of the progeny to express a different pair of traits.
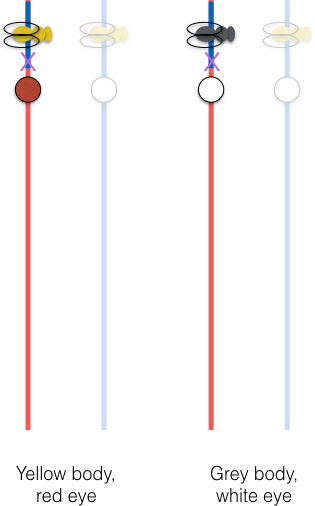
Every time you see a fly with red eyes and yellow body, or white eyes and gray body, in this cross, you are seeing the phenotypic expression of a recombination event between the two genes.
We can use this chance event to make a map of genes, an insight that came to Thomas Hunt Morgan and Alfred Sturtevant around 1911. Yes, genetics has been using chance to study genes for over a hundred years.
The way this works…imagine you have a barn. On the side of the barn, you paint two targets: one is a square 2 meters on a side, and the other is a smaller square, 1 meter on a side. You then blindfold a person with a gun, and tell them to blaze away in the general direction of the barn. At the end of the afternoon, after they’ve gone through a few boxes of ammo, you tell them the results: most of the time they completely missed the targets, but they hit the first one 18 times, and the second one 4 times.
Can they estimate the relative size of the two targets?
Of course they can. And the more shots they take, the more accurate their estimate will be.
That’s what Sturtevant and Morgan were doing. They couldn’t see genes, they could barely see the chromosome, but they could use recombination to take random shots at the arrangement of alleles on the chromosome, and they could see whether they hit that spot between two genes, like yellow and white, by looking for the rearrangement in the phenotype. The frequency of those rearrangements relative to misses also told them the relative size of the target — how far apart yellow and white are on the chromosome.
(FYI, yellow and white are fairly close together, and we see recombination between them in only 1.5% of progeny of the cross. This gets reported as a map distance of 1.5 between yellow and white.)
You cannot predict ahead of time whether a specific individual produced in this cross will be wild type, or white-eyed and gray-bodied, or any particular possibility. It is a random process with a stochastic distribution of results that has some general predictability, just like an individual bullethole produced by the blindfolded shootist.
This seems to baffle creationists. They have a deep antipathy to randomness on principle, but even worse, they seem incapable of realizing that scientists can be simultaneously studying chance events that have statistically predictable outcomes — like genetics, or evolution, or the physics of sub-atomic particles. It’s a guaranteed way to blow their minds to point out that on one scale a phenomenon might be chance driven, but stepping back and looking at the whole reveals a regularity and pattern.
At which point they stagger back and declare that the small-scale events have to be determined and specified and predictable too, and therefore nothing is random. They just don’t get it.
*Misandry!

Casino owners must love these people…
Sorry, PZ. I was wondering why you were having an argument with Laverne of TV’s “Laverne and Shirley.” Then I saw it was Perry Marshall, not Penny Marshall.
Never mind. (Same level of slapstick comedy, though!)
Oh for fuck’s sake. Hey, Perry, it seems you don’t know what synonym means. Here’s a bit of help.
Going along with your bit of idiocy, however, God, Designer, and Bible are no longer allowed. Nor are any euphemisms allowed, such as God did it, or Word of God, and so on.
Whereas, the chance-deniers care so deeply that they might not only not know, but may be forbidden by the laws of the universe from knowing something, that they are more than willing to invoke God, the Flying Spaghetti Monster, or magic.
And, sadly, you don’t have to be a creationist to get caught up in chance-denial. Even some very prominent evolutionary biologists don’t get it. They can even accept that chance (or the Bohmian equivalent of a deterministic state dependent on unknowable factors in the absolute elsewhere) is undeniably part of quantum mechanics, but can ‘t see that this means that the chemistry of mutational events must also be unpredictable in detail. I’ve been banned from a prominent evolutionary science blog for even suggesting it.
This was a neat post, although:
*Misandry!
Is clearly the best part. Thanks for that.
As Thomas Hardy put it, eloquently:
If but some vengeful god would call to me
From up the sky, and laugh: “Thou suffering thing,
Know that thy sorrow is my ecstasy,
That thy love’s loss is my hate’s profiting!”
Then would I bear it, clench myself, and die,
Steeled by the sense of ire unmerited;
Half-eased in that a Powerfuller than I
Had willed and meted me the tears I shed.
But not so. How arrives it joy lies slain,
And why unblooms the best hope ever sown?
—Crass Casualty obstructs the sun and rain,
And dicing Time for gladness casts a moan. . . .
These purblind Doomsters had as readily strown
Blisses about my pilgrimage as pain.
Creationists love to state that God knew your name and every hair of your head before you were born. Everything is predetermined, yet we are guilty for the sins we commit (and those of Adam and Eve). I’ve had an email exchange with a well educated but blinkered evangelical Christian who said that indeed God is holding together every atom in the universe and without His grace, everything would instantly turn to chaos.
With that type of worldview, then when a scientist attributes something to chance, they scoff, and to them this is consistent with their worldview that God is in charge of even the smallest details.
But there is a more subtle point he could have attacked which, while wrong, would have been more defensible.
The naturalistic view is that everything is physically determined. There is no chance in the way the dice tumble, as the outcome had to happen given the initial state of the universe. So that would seem like the scientist who blames chance is wrong, since there is no such thing. So it comes down to how you define chance. I’m not sure of the best definition, but off the cuff, it would be something like this. Even though outcomes are due to purely physical properties, in practice most of the time we are unable to or it is impractical to determine the exact state of the physical system in order to calculate the outcome, so we call it “chance.”
Quantum mechanics says “no”*. Sure, a great many things which look random are simply very, very difficult “initial conditions” problems, but some things really are genuinely random.
[* To the best of our current understanding.]
@jaybee: Yeah, that seems about right. I was actually about to mention that – I don’t know a lot about chaos theory, but given my understanding of what it means for something to be “chaotic” (variations in the initial conditions so minor that we cannot adequately model or reproduce them produce huge swings in the result)… it sounds like we could just replace every instance of “random” in PZ’s model above with “chaotic”, and suddenly Perry has nothing to complain about. (As long as we don’t pull in QM, at least.)
Dunc, when you roll dice, 99.999whatever% of the time, the outcome can be determined without considering quantum mechanics. Most of what we attribute to chance is due to our inability to gather the state of the system. Sure, if you hooked up a geiger counter and amplified the ticking noise so that the person throwing the die could hear it, that could affect the outcome. But 99.999whatever% of the time that doesn’t happen.
I’ll start worrying about chance when the god-botherers convince me that humanity is a predetermined result.
Isn’t that what I just said? OK, I didn’t use the specific example of dice, but yes, a die roll is just a “very, very difficult ‘initial conditions’ problem”.
The interesting question is exactly where the dividing line lies…
On the other hand, since the recombination events PZ talks about in the OP occur at the molecular level, there’s a very good chance that they are at least influenced by quantum events, and so genuinely random…
Went to look at his blog – he seems to be doing his best to milk his “war” with a well known atheist. Your name is right up there in the nav menu, PZ! A place of honour!
Every time I see something like his arguments – and his most recent blog post actually attacks your description of recombination – It always comes down to someone relatively untrained reading a scientist who’s used a metaphor or “simple” language and taken the words to be literal.
It’s sad, really – we can’t win! If you stick to complex, arcane technobabble then no one understands it and you get to be an ivory-tower academic who doesn’t know how the ‘real’ world works. If you use metaphor and accessible language, they mistake (or gleefully assume) the metaphors are indication of some sort of intelligent design instead of taking them for what they are.
not just “initial conditions”, but also accounting for every variable to the Nth degree and completely the equation of motion explicitely, to accurately predict the result.
@Dunc
On QM don’t we just change 100% this-determines-that to something more like “this event has X% chance of causing Y% outcome”? Isn’t that still physical determinism, just of a different sort?
@7
While the philosophical question of “if everything is deterministic from the boundry conditions of the universe is anything truly random” can be interesting, this is why I prefer a more utilitarian definition of ‘random’: A random system is a system which obeys the laws of probability.
If you are trying to predict what will happen when PZ rolls his die 666 times it may (depending on the underlying cause of the effects of quantum mechanics) be true that given a perfect understanding of all the laws of physics, the exact conditions under which the universe formed down to the tiniest potential fluctuation, you could extrapolate through billions of years to eventually figure out what would come up…. or you could say “hey, this is a random system, so I predict 111 ones, 111 twos, 111 threes.. etc. within these boundaries”.
So whether or not the die roll was pre-determined at the universes origin, it *still* obeys the laws of probability, so I can still usefully define it as ‘random’. Interestingly, this definition means you have to consider how the system is observed. Imagine PZ rolls his die and writes down every result. Put a wall between him and me, and have him read off the numbers. To me the numbers are ‘random’ – I can’t predict what will come next – but of course PZ knows exactly what comes next.
Wikipedia link to Quantum Mechanics section of Determinism:
https://en.wikipedia.org/wiki/Determinism#Quantum_mechanics_and_classical_physics
@Rogue Scientist
Everything obeys the laws of probability. So you are saying everything is random?
Also, another thought about QM determinism, it still ultimately could be a sort of “100% this causes that”, except that the “this” and the “that” are specific probability distributions.
PZ, I hope you will do a post about this some day. This boggles my mind how a random break in one chromosome can be perfectly matched in the other chromosome.
Scientismist:
Kind of difficult to parse this.
They’re not “equivalent,” because according to BM it’s all deterministic as you noted. If the configuration starts with a psi-squared distribution, then it’s simply a fact that it remains that way in every other state. (Not sure what you mean by “the absolute elsewhere” — because it’s just the spatial configuration of all of the particles that we don’t know exactly, their actual positions here and there and “elsewhere” if you like.) Probabilities can enter the picture because you’re using them to characterize a configuration like the initial conditions for example, which is not to suggest there is a frequency of something as you might mean when you use probabilities in other contexts. You could still get a kind of deterministic chaos from that as well, which isn’t the same thing as randomness.
Anyway, that’s not equivalent to saying the dynamics itself is stochastic, or in some other way that it’s all fundamentally indeterministic, as some other quantum theories claim. That would be like saying P = not-P. Sure, they’re both using probabilities (in different ways), but the more interesting and important point is that they’re telling you very different things about what the world is like.
Of course, one sense in which they are “equivalent” or “just as good” is that both types are empirically adequate or both will give correct predictions. In other words, we can’t tell (currently) which is probably right by looking at some data and ruling one out because the data tells us to do that. Other non-empirical criteria could help us decide which type of theory we prefer, like simplicity, clarity, if it avoids (or introduces) certain logical or conceptual problems, if it’s comprehensible as a realistic fundamental theory which is meant to tell you something substantive about the universe (or if it’s just taken instrumentally, as a set of tools to predict what will happen in experiments, not a full-fledged theory of the universe), and so forth.
Well, if what you mean by chance is unpredictability, then obviously it’s their problem that they can’t see that it means what it means. So what’s the difficulty? Or how could they be confused about something like that? One way of understanding it is that it’s a statement about our inability to make certain kinds of predictions, not a statement about how the actual world itself behaves (independently of what we’re able to do or think about it). You could mean that it’s a fact about the limitations of our epistemic states, or you could mean to make the claim that the world actually has (or is) random elements/properties/processes/etc. Since you were okay with saying they’re equivalent above (presumably because they’re empirically indistinguishable), I take it that you’re making an epistemic sort of claim, but it’s not clear what if anything is supposed to follow from that when we’re talking about how the actual world is. Because a deterministic theory is also empirically adequate (but we can’t tell if it’s true or if an indeterministic one is true), then realistically speaking the world itself could be either way, at the level of QM or at any other level like chemistry or biology.
jaybee says:
I don’t think you can say that. We don’t consider QM in trying to “determine” (predict) a die cast, because we can’t gather the data even to a helpful macro level above the level of QM. That’s why you don’t see any sensors more sophisticated than the security cameras at a casino craps table — it’s futile for the house to try to predict the outcome of a particular rolling of the dice. Casinos calculate their expected margin on the basis of the chance events that they cannot predict, and which they are confident that no-one else can predict either.
Dunc has it right:
The important thing to realize is that the detailed course of every event in biology (or craps — the heat of the hand, the effect of the atmosphere, the resilience of the table surface) depends upon molecular level events, and so is predictable only in a stochastic sense (the house knows it’s going to win in the long run), unless a great deal of effort is made to overcome the random factor. That kind of effort (as in DNA replication and repair) is a large part of what life and evolution have been working (by harnessing energy flow and chance and necessity) to achieve.
While randomness makes them cry, what they’re really terrified of is causality. Religion depends on a very simplistic view of cause and effect: that you can point to a web of influences on an event and say “there! that’s the ’cause’!” Of course reality doesn’t work that way. It doesn’t even work that way for the faithful but they can’t bear to confront it: who created the universe? god. who is the cause of sin? is it me, or god, or my parents, or society, or …? They worship a god that simultaneously is the cause of all that’s good and not responsible for anything bad. Explain to me again how that works? Oh yeah: jesus!
consciousness razor — Your comment 21 is most interesting.. I think we have no serious disagreement, but I am not sure.
I have been a fan of Bohr over Bohm (or other deterministic QM interpretations) for nigh onto 50 years, but I will readily admit that my choice (as a biologist, not a physicist) is completely subjective (even emotional). What I dislike about the deterministic interpretation is that it has, in my observations, led to many pseudo-scientific defenses of absolute knowledge. Once one is convinced that “the answer is out there”, it is a short step to the claim that knowledge of the exact future, and/or the exactly right and proper future course of human events is manifest, if only you have the right “sensitivity”, and that there is something existentially wrong with those who disagree. (“The future is hidden to lesser intellects.. I however…”)
The “absolute elsewhere” is a phrase I came across many years ago with regard to events that lie in that portion of space-time outside of our knowledge, as limited by the speed of light. It is the hidden realm where the answers all lie in those deterministic and gnostic interpretations. The wave function of that photon from deep space that is right now affecting some Earthly historic event (a mutation, perhaps) is correlated with the wave functions of every particle that ever interacted with the physical system that emitted that photon, and the exact solution to the calculation that would predict how it would affect our reality here and now (the possible mutation) must depend on further events that are happening that involve those particles at this moment on that distant star system.. but no knowledge of such subsequent events at that distance will be available here and now to allow such calculations for perhaps millions of years. Perhaps the physical world is deterministic, but the calculation (prediction) of events is just as limited as if the exact state of a particle were to have a truly random component, as Bohr would have it.
QM truly has an element of chance. Forget dice. If you have a radioactive nucleus you can never, ever predict when it will decay. It is not that you don’t know enough, or that the technology is not good enough, you just can’t.
Classical chaos theory is deterministic but unpredictable. If I rewind a chaotic system and start it over with exactly the same initial conditions it will result in exactly the same final state. However if I tweak the initial conditions even slightly (the butterfly wing flap in China) the final state will generally be vastly different.
Marcus @ 23:
Others have noticed that too (even without Jesus):
Marcus:
And that really is a lesson that we should take away from quantum mechanics. (Unlike the purported lesson that reality is indeterministic, because we don’t know if that’s the case, only that people with a particular sort of interpretation believe that.)
Entanglement is a counter-example to “causality,” or simply a violation of it, in the ordinary sense that most people would use it intuitively or pre-theoretically (or given a classical theory). That is, some states are correlated, in a way that they are “influenced” by one another somehow, but they can’t have anything like a simple cause-and-effect relationship, because it’s a nonlocal phenomenon (so “locality” is also violated). This sort of influence is instantaneous and invariant no matter how far they are from each other, and there’s nothing special happening in the space between that you could somehow associate with a causal chain of events propagating from one toward the other (or vice versa). You could imagine building some kind of a wall to try to stop the propagation (if there were anything propagating) but it will make no fucking difference because nothing is acting as a signal that would move (superluminally) from A to B.
They’re just somehow not separable states, so that it appears doing something over here to this state just is doing something over there (although of course we can’t control the statistics of either to do superluminal communication). Anyway, it’s not a causal relationship in the ordinary sense of the words, with one thing here causing another thing there or else the reverse — it’s neither. The world just doesn’t care about respecting that concept in these situations, but on the other hand, it’s incredibly useful in our everyday experience to describe the kinds of events that really do work that way.
A favorite example of mine from everyday life concerns road fatalities. Nobody has the first clue as to who is going to die on the roads this year, but we can predict with a very high degree of certainty that around 33,000 Americans will die.
Religious people like to invoke a higher power whenever a traffic accident results in a tragic loss, or miraculous escape, yet it becomes hard to justify such invocations when you zoom out and look at the overall statistics.
And as the “will of God” vanishes, the power of human agency is revealed in those statistics — better car safety features, changes in the law, better road design, etc. etc. That’s where the real power to save lives (or destroy them) lies.
Well, okay, some might do that I guess. (Not Bohmians obviously, but you’re paranoid about the possibility, given that others have made similar sorts of claims.)
But the fact is that the world is a certain way, either. And the fact is that we have no knowledge of which way it is. You’re worried that, if it is a certain way, some might abuse that somehow. Okay. This is clearly an appeal to consequences, so that doesn’t imply it’s wrong. Therefore, you shouldn’t conclude on this basis that it is wrong.
If you have some better and non-fallacious reason to reject a deterministic theory (or presumably all of them), then please tell me about that reason. But I don’t think you have one.
Well, I have no idea what you mean by “gnostic,” but nonlocality, as I described in response to Marcus Ranum, is a feature of all versions of QM (or any future theory that might eventually replace them) that can make the correct statistical predictions. You simply don’t have the option to discard determinism in order to save locality somehow. That’s a false choice, unless you think it’s worth it to make the wrong predictions or to toss out actual phenomena in the real world that you’d rather not think about.
Bell’s theorem is fairly theory-independent, but it does implicitly assume that once an experiment’s over it has a definite outcome, so it can’t tell you that a Many-Worlds interpretation must be nonlocal (could be nonlocal anyway but the theorem doesn’t apply) since in MW there is no definite outcome, whatever it may be that MW says is supposed to happen in the world (which isn’t at all clear to me). However, MW is a deterministic theory (it’s just the Schrodinger equation which is linear), so even with that option on the table (if you think it’s worth entertaining at all) we’re still not presented with a choice between nonlocality on the one hand or indeterminism on the other. If you liked, you could hope to make some kind of a local MW theory, but the most you can say is that this hasn’t been proven impossible (not yet). But for any other sort of theory, except those that propose huge and utterly implausible cosmic conspiracies of some sort, it’s logically impossible. Hasn’t happened, won’t happen, can’t happen.
whoops, didn’t finish my sentence:
“But the fact is that the world is a certain way, either [deterministic or indeterministic].”
Random thought:
I wonder if hating the idea of chance is in any way connected to privilege?
It’s certainly true that successful people tend to overemphasize their competence and under-emphasize the role of chance in their careers…
Presumably, any time the universe “branches,” the particle being either or there has something to do with the entire universe immediately — the claim is that there are multiple universes after all, not just multiple positions of a single particle — which makes it nonlocal, if you take spacetime and the matter in it to be the things that are real and fundamental.
But to be fair, I really don’t know (or care)… maybe you could develop some other kind of MW theory which works differently somehow. If you thought the real thing is just the wavefunction (forget about matter in three-dimensional space) then maybe in some sense you could say it’s “local” in that wacky place where the wavefunction lives. But that’s going very far afield of the claims being made about locality/nonlocality in ordinary spacetime with some matter, which people normally take to be what physical reality consists of.
consciousness razor @ 29:
gnostic: 1. pertaining to knowledge. 2. possessing knowledge, especially esoteric knowledge of spiritual matters.
OK, it may be stretching the dictionary definition a bit, but I use it here to mean a pretense to the possession of knowledge that is humanly unobtainable. And I hope that we can agree that, determined or not, the full information is not available here and now.
I’m not sure I can agree with that. I think it is an unanswerable question, and speculations about the answer, being ultimately and truly “unspeakable,” are best left unspoken. I believe the important point is that since the two make the same predictions, it doesn’t really matter, except as a point of departure for misinterpretations. And that is not just a possibility and a fuel for paranoia, but an entire existing genre of new-age-ish, Templeton prize-winning, literature.
As the old comedians used to say, “That ain’t the way I heerd it.” You’re probably more up-to-date than I am on the subject, but my favorite paper on the trade-offs available was Bernard D’Espagnat’s 1979 Scientific American article (I think I have that issue stored away somewhere, but fortunately it’s also available on-line). He narrowed it down to three postulates, one of which has to give way; which he labeled (1) naive realism (or determinism, rejected by Bohr in favor of a true randomness), (2) Einstein separability (or locality, rejected by Bohm in favor of quantum entanglement), or (3) logic (which nobody seriously tries to do). (But with regards to that last one, I did read one article in the early 80’s that concluded that all attempts to do so up to that time were actually logically equivalent to rejecting either postulate 1 or 2 — but I don’t know if that was before or after rejecting logic itself. That one got too messy for me to follow.)
So my understanding is that, far from not having the option to choose, D’Espagnat was saying that we must indeed choose. And shortly after writing that paper, he did choose, in favor of an interpretation that saves realism and determinism, at the sacrifice of separability and locality. And I would not care in the least, except that the Templeton Foundation was delighted that he had found a place for God in physics.
Now, if D’Espagnat’s entire discussion of the subject has since been properly rejected, and what he saw as his own Deity-friendly favored choice is now no longer a choice, but is somehow forced upon us, I’d like to know the references for that (hopefully as lucidly presented as in his own Scientific American paper. He was a good writer, even if I do think he later went off the rails).
Because in fact the world is neither deterministic nor indeterministic, but something else? What other possibility is there? That’s what you’d have to disagree with, if you’re going to disagree with it.
You don’t need to know or speculate about which it is, to agree that the world is such that one or the other of them is the answer. If you think there’s some third option, then feel free to specify what that other sort of possibility is like. I’ll give you one logical possibility, just for the sake of argument: there’s no universe, so it’s neither deterministic nor indeterministic, because it’s nothing. That’s not an option you’re going to pick of course, but it would be something.
But “I won’t say” isn’t actually a coherent description of reality, and I think your rule that we shouldn’t speak about certain things is a bullshit rule. Reality doesn’t care whether or not you speak about it, or what you happen to say — it just is the way it is — and the concern here is the way reality is, not you or how willing you are to say something.
Note that, until I interrupted, you were the one who was certainly not leaving anything unspoken but making an actual claim about which is the correct answer: that it’s indeterministic. This was something you took on board, and it was the basis on which made other claims about nature, having to do with things like chemistry. I’m saying, on the other hand, that we don’t know any such thing — yet this is for no sensible reason what you’ve decided to call “gnostic” position.
Anyway, where did you get this knowledge, if you understand the important point is that you couldn’t have gotten it from any empirical evidence? In fact, you don’t have that knowledge, you just think you do (until I corrected you at least), because it’s a very commonly repeated misconception about QM.
I don’t know about the popular article you mentioned, and to understand it you don’t have to be any more up-to-date than Bell’s paper about EPR (of course, there have been many experiments since to confirm it, but there isn’t anything new to think about).
Anyway, “determinism” doesn’t mean the same thing as “naive realism.” Indeed, one just has nothing at all to do with the other. You can use words however you like, I guess, but I’ll have no idea what you’re saying if it’s going to be like that.
What? How the fuck could that have actually created a place for God in physics?
Why wouldn’t you complain about any scientific theory, if you genuinely care that the Templeton Foundation happens to be delighted by it ? (Or if not Templeton, certain types of creationists, or whoever you’d use to make physics guilty by association…. Hitler maybe.)
The Big Bang, for example — is that wrong or does it seem at all suspicious to you, because some people think the universe having a beginning (possibly) is better news for theism (that’s when their creator created it, they say), compared to having evidence (and a corresponding theory) that the universe is infinite in the past? If their bullshit is not a good reason to reject the Big Bang, what the fuck does it matter in this case? Or, some people think evolution by natural is a fantastic way for their very powerful and intelligent creator to do the work that it wants to do…. because there’s no reason why bullshitting people can’t think whatever bullshit they want to think — in any case, the point is that you’re not rejecting evolution, definitely on the basis of some nonsensical bullshit that some people happen to say.
So, I could also argue that I don’t even get how determinism is supposed to be helpful for theism, because I really don’t see the connection. But even if it were the case that it’s somewhat helpful for theism in some convoluted way or another, the question at hand is how is your reasoning in your argument supposed to work? Do you apply it consistently? If not, why not?
Like I said, it’s been understood (by some at least) since Bell’s actual paper on EPR. Various groups inside and outside of physic have sown a lot of confusion about it since then, but that (along with the EPR paper) is the primary reference, and that’s all you need to get. Those are relatively clear and easy to read, at least when it comes to theoretical physics.
I don’t like the word random very much. Not even quantum events are totally random. Probabilism is better – and everything is probabilistic. What we call causal for instance is nothing but a probability of nearly 1 or 0.
consciousness razor@#27
And that really is a lesson that we should take away from quantum mechanics. (Unlike the purported lesson that reality is indeterministic, because we don’t know if that’s the case, only that people with a particular sort of interpretation believe that.)
I was a psych major back in 1983 when I took my one pass/fail physics class. Ouch. I vaguely fobbed the professor something about that I wanted to write poetry and he cut me a lot of slack; I think he was afraid I’d throw off the curve. But, anyhow… Yeah.
I wasn’t even thinking at the quantum level, though of course when you want to talk causality, that’s everywhere. Even at the macro level causality is something we humans just don’t think about very well. My evo psych “just so story” is that we evolved in a world where it was useful to have a limited instinct for mapping cause and effect for survival purposes. Why did the deer die? Because I was hungry and it was near the bush with the berries. That works for the environment our brains were evolved to work in. But causality is a great big intermeshed web or, if you prefer, a massive expression with a whole lot of “and” sub-expressions. The deer died because: (it was thirsty) && (I was hungry) && (I’m pretty good with throwing stick) && (I had throwing stick) && (daylight!) && (deer evolved) && (that deer’s parents mated successfully) && (the big bang) … Even human philosophers seem to like to collapse causality down to a single chain when, really, there’s no sensible way to point at any particular sub-expression and say “that one!” Aristotle tried to sort through this, at least, with his mum-mumble about ‘proximal causes’ and ‘ultimate causes’ and whatnot but really I think his take on the issue was more illustrative of how badly we think about cause and effect. No disrespect to Aristotle intended.
Why did the chicken cross the road? The big bang.
Why is Donald Trump such an asshole? The big bang.
Actually, The big bang and his parenting and the kid who made fun of him in elementary school and, and, and, and. We humans simply can’t get anything done unless we arbitrarily point at the list and say “that’s the cause” but no condition is sufficient by itself and if you want to argue that any one of the causes of a situation, down to the quantum level, is probably “the” cause. Well, it gets really hard to say “jesus” (I mean, mary was a precondition for jesus. OK some people consider mary to be an important part of the whole jesus thing but mary’s mom was exactly as important as mary and mary was exactly as important as jesus…) it all falls apart. Since, basically, religion is a blame game, causality has to be simplified ridiculously:
Jesus: “let him that is without sin throw the first stone…”
Causality skeptic in the audience: “If it’s not something I caused, can I have sinned? Because sure I kill people but it’s really the romans’ fault because if they didn’t come here for me to kill them I wouldn’t have done it…”
Jesus: /facepalm
Science’s great task is isolating causes. We say something causes something else when those conditions always result in the conditions that follow. But you can always widen your scope until everything’s a result of the big bang (even jesus, because mary’s mom was a result of the big bang..)
I’m not being silly about this, I swear. We just aren’t any good at thinking about causality; whenever I try my head spins and I just sit there staring at my navel and it’s all because of the big bang. No, actually, it was because my mom and dad met at that movie in 1950. All I can say for sure is I was just a helpless bystander. Really.
They’re just somehow not separable states, so that it appears doing something over here to this state just is doing something over there (although of course we can’t control the statistics of either to do superluminal communication). Anyway, it’s not a causal relationship in the ordinary sense of the words, with one thing here causing another thing there or else the reverse — it’s neither.
Yeah. That always makes me want to sit and play with my toes while I think about it. (no, I am not drunk right now but maybe I should go grab a bottle from the basement if I am going to continue with this…)
But what caused the entanglement?
I think it’s that we simply can’t survive if we try to think of cause and effect as the great big web/lattice/whatever it really is (technically, I think it’s actually called ‘reality’) and we’re so well-adapted at deciding where to focus at any given time, and call that focus the “cause”, that it just seems natural to us. I guess that’s because if we tried otherwise we’d just wind up playing with our toes. Even philosophy, which is supposed to be trying to think rigorously about this stuff, constantly flattens causality down inappropriately: “So, suppose A pushes B in front of a train, is B’s horrible death A’s fault?” Uh, no, it’s just as much the fault of the guy who designed the train as it is A’s. No, wait, I blame jesus.
I suppose you could say that, if you’re looking at large ensembles of results… But the individual events are random – as Bill Buckner says at 25, you simple can’t predict the radioactive decay of individual atoms, because it’s a genuinely random process, although the probabilities are well-known.
I think part of the problem is that we don’t have a particularly good vocabulary for these types of ideas – words like “random”, and “probablistic” have well-understood technical meanings amongst specialists, but they are overloaded with so many other shades of meaning in general discourse that it’s difficult to use them without confusion. To me, “determinisistic” means that you can plug some numbers representing the initial conditions into an equation, and get a number out that tells you exactly what it going to happen, as in classical mechanics.
Marcus Ranum @37:
Conservation laws. For example, a positively charged pion has zero spin (intrinsic angular momentum). It usually decays to an anti-muon and a muon neutrino. They both have spin ½ħ (ħ is the Planck constant). If you measure the spin of the anti-muon, a measurement of the neutrino would have to give the opposite spin to add to zero, because angular momentum is conserved. So the spin state of the decay products is, apart from an overall constant (μ for the anti-muon, ν for the neutrino),
|μ+>|ν-> + |μ->|ν+>
where the signs indicate spin along some axis. This is an entangled state, which just means you can’t write the whole wavefunction as an anti-muon part times a neutrino part.
What makes this case even more interesting is that the muon neutrino is a combination of different mass states (as are the electron neutrino and tau neutrino). So conservation of energy and linear momentum mean that the final state is kinematically entangled as well as spin-entangled.
@Marcus Ranum
Good points about how inter-meshed it all is.
My thinking:
Like you said, we look for causality for practical purposes. When people ask for a “cause” they are usually bracketing off an event or item as a black box and looking for some other event or item that interacted with the boundary of that box. Of course the answer is different if you make the box bigger in space or time, because that amounts to asking a different question. So I think any confusion about what someone is asking probably boils down to the fact that they just asked for the “cause” but didn’t specify the box clearly enough (plus there are often causes that we already know and often don’t care about) or didn’t specify the level of abstraction (are we interested in molecular-level causes? Psychological causes?).
To go back to the big bang, you would have to stretch the box temporally to encompass Donald Trump’s particles (or some other level of abstraction) throughout all time (rather than just the last century or whatever).
We could ask any of these questions, but because we have practical aims we usually just focus on the ones we think will be useful for our purposes (so that we know which boundary conditions to choose etc.).
https://en.wikipedia.org/wiki/Free_body_diagram
And if you ask why Trump is such an asshole, I would assume you want to deal with the psychological level of abstraction for the duration of his lifetime.
consciousness razor @34:
Thanks. And sorry — I didn’t mean to rile you. I am pretty sure my understanding of these matters is faulty (ok, even dead wrong). But, I must respectfully submit that your reading of what I wrote seems also to be wrong. Or maybe I just didn’t make myself clear. Or maybe you didn’t. Quite honestly, it sounds like you are taking a hard position here on an issue on which you agree there is no evidence one way or another, while criticizing me for taking an opposite position, when I have been trying hard NOT to take a hard position.
What I said, back in #4, was that the role of chance, or of the Bohm equivalent (“entanglement” is, I believe, the most accepted term) means that physical and chemical events must be unpredictable in detail. I subsequently tried to make it clear that, while I may have a personal preference to think about it in the old-fashioned terms of “randomness,” I don’t think it really matters, except when some may want to (mis-) use QM to make rhetorical points; and that neither interpretation (nor any other that I am aware of) can actually be used as a coherent justification for religious and political claims of access to absolute knowledge.
I don’t think there is an answer to “which one is correct,” because both are (I believe) correct. They make the same predictions (don’t they?), and I agree that the fact that one has been used perhaps more than the other as a springboard for rhetorical nonsense is no reason to favor the other. The argument that one is more friendly to theism than the other is not mine, and is in my view inconsistent, so don’t ask me how to apply it consistently! For that you might read D’Espagnat’s later writings, or Arthur Peacocke for a “scientific” defense of absolute knowledge; or any of a raft of philosophical scientific foundationalists.
You don’t like the idea of not speaking of the unspeakable:
The idea that there are things that should be taken as “unspeakable” I got from “Speakable and Unspeakable in Quantum Mechanics”, the title of the collected papers of John Bell. As I understand it, he didn’t really like that advice, either, and leaned toward Einstein’s “hidden variables” and hoped, until his untimely death, that some new experimental breakthrough would show that the early results on tests of his inequality would be proved wrong, and that the real world could be correctly described as locally causal.
But I would make an additional point. “I won’t say” can indeed be a coherent ethical choice when “I can’t say” is a coherent description of our knowledge of reality, as I believe it is here. I thought that you agreed with me that there is no observational evidence to favor one over the other — am I wrong about that?
The concern here is not “the way reality is,” but what we can (or should) say about it. Or on another level, what we can say about what we can say about it. Theories, and interpretations of theories, are not reality. You’re right, reality doesn’t care what we say about it; but humans do. Theories are metaphors, which aren’t necessarily “true”, but can be “apt”. The concern is whether saying reality “is” A (and not B), when A and B don’t make any differences that we can (or could) observe, is apt; whether making a commitment in spite of a lack of evidence, is suited to our human purposes.
I’m no expert on QM. It was 50 years ago, winter quarter 1966, that I took my one and only course (undergrad physical chemistry) that covered some of QM. I got a good grade most likely because I was good at using the college’s new IBM 1620 computer to calculate the wave function (or the “probability function”) for a particle in a box and graphing the result on the output typewriter terminal. It was only a few years later that I began to believe that the “randomness” and “uncertainty” of QM might have some importance to human ethics. If you are at all interested in that idea, read Jacob Bronowski’s “Science and Human Values”, or better, read or watch his “Ascent of Man”, episode 11 on “Knowledge or Certainty”.
I don’t think it is bullshit to exercise caution in expressing supposed certainty. There are only a couple of things concerning QM about which I feel at all comfortably close to certain. One is that I don’t understand it sufficiently to do more than express an opinion (perhaps mostly an ill-informed one; or perhaps, like Bell’s own opinion, just a hope). And the other is that, in my opinion (or hope), QM is consistent with the notion that the certain, exact, capital-T-Truth may not even exist; but that even if it does exist, nobody can really know it. If that hope is way off base.. well, there are a lot of folks shouting that they’ve found it and will be happy to tell us all what to do about it; but I may just be too old to start looking for the right guru.
That’s what I have absorbed in the last half-century from many sources that seemed to know a lot more than I did about QM, and who also sounded trustworthy. Beyond QM, I will state with very little hesitation that claims to certainty, scientifically justifiable or not, have been a bane of humanity.
Again, sorry to have somehow riled you.
Re: #20 by moarscienceplz:
Short answer: because the DNA strands are perfectly matched up end-to-end in a double helix and tightly wound together, so most things that break DNA strands cause a double break at the same spot in both strands. Think of cutting a pair of twisted threads with one snip of the scissors … See the Wikipedia article on chromosomal crossover for a brief introduction.
Long answer: oh, hell no. Seconding the request for an article from Prof. Myers. :)
Thing is, that’s pretty much all the experts can do too… The arguments about the various different interpretations of QM are increasinlgy coming to be seen as an irrelevance. This is commonly known as the “shut up and caclulate” interpretation, which argues that it’s impossible for us to really know what QM actually “means”, or that the question may not even mean anything, and that all we can do is use the maths.
Note that creationists prefer to speak of “mere” chance. Like that actually means anything.
How about “mere” creation?
@39:
Bad wording. Should be
The overall constant is just 1/√2