Marcus reminded me of the common claim: “AI is just remixing existing works”. Or the more colorful version, “AI just regurgitates existing art”. This is in reference to creative uses of AI image generators or LLMs.
While there may be a grain of truth to the claim, I have difficulty making sense of what it’s even saying. It’s basically an unverifiable statement. I think both pro- and anti-AI folks would be better served by a more technical understanding. So, instead of being stuck at an impasse, we might be able to actually find answers.
Initial reactions
First, let’s get some quippy thoughts out of the way. We all have them, leave yours in the comments.
1. I am an origamist who posts original designs alongside recreations of other people’s designs, and readers seem to enjoy them in an ordinary fashion. If AI is just remixing existing work, I cannot see how this isn’t even more blatantly true of origami.
2. Having worked on non-creative uses of LLMs, I have to say that the creative spirit of AI is an honest to god barrier to replacing human workers with robots. I suspect that in the use cases that most inspire investors, they don’t want AI to be creative, they just want it to produce the right answer.
What does that even mean?
I do not know what people mean by “AI is just remixing existing work”. One could imagine an algorithm that, when asked for a dog, retrieves a bunch of dog pictures, and copies little rectangles from each of them, and stitches them together into a frankendog. I’m not a stable diffusion expert, but that’s very obviously not how stable diffusion works, and I don’t think anyone is seriously claiming that it is.
Maybe it’s doing something more subtle, like taking different elements from different images? For example, it might take the outline of the dog from one image, the colors from a second image, and the textures from a third image. This is likely closer to the mark, although the elements that stable diffusion borrows from existing images do not neatly correspond to any human concepts. e.g. it is unlikely that the neural network has a single neuron corresponding to “fur”.
If an LLM model were doing nothing more than taking a sentence from Dickens, a sentence from Shakespeare, and a sentence from Twain, we might be able to agree that this is a form of regurgitation. But if it took a word from Dickens, a word from Shakespeare, and a word from Twain, isn’t that just how language works? Obviously, every word we use is just a word that we have seen others use.* So where do we draw the line between “regurgitation” and “how language works”? And what is the equivalent dividing line for elements of the visual language?
*Okay, humans can invent new words, but so can ChatGPT. If you know anything about tokenization, you’d know this is not a trivial fact, but it’s one I’ve tested and you can too. I used a random name generator and asked ChatGPT to generate portmanteau couple names. e.g. Ricky Alyson + Rowland Zeb produced “Rilyand” or “Zeblyson”. …I’m not claiming that ChatGPT is good at this.
“AI is just remixing existing work” is an unverifiable claim, because on the one hand, this could describe ordinary language, and the other hand, could describe the frankendog. Nobody knows what anyone is trying to say! It depends on how finely we chop the pieces, but where do we draw the line? How can we possibly draw a line, when the “pieces” taken from the training data are not literal rectangles or phrases, but something altogether more abstract, and human-uninterpretable? No wonder the argument goes in circles.
What about quoting Wikipedia verbatim?
There is a real problem in here, for both LLMs and image generators, that sometimes they generate large recognizable chunks from known sources. For example, quoting Wikipedia verbatim, or reproducing Claude Monet’s The Water Lily Pond.
My informed speculation is that most cases are the result of duplicates in the training data. This is an acknowledged source of error in natural language generation, as I read in this review paper:
Another problematic scenario is when duplicates from the dataset are not properly filtered out. It is almost impossible to check hundreds of gigabytes of text corpora manually. Lee et al. [134] show that duplicated examples from the pretraining corpus bias the model to favor generating repeats of the memorized phrases from the duplicated examples.
The cited study found that over 1% of output was quoting verbatim from the training data. They were able to reduce this by a factor of 10 by removing duplicates in the training data.
There are a few takeaways. First, this is only happening in 1% of the output. That figure is a measurement on a particular model, and it could be wildly different for ChatGPT or Midjourney, but it’s not the 100% of the time that people seem to imagine.
Second, if ~90% of the problem comes from duplicated data, this is much more likely to happen to “well-known” texts or images. People see verbatim quotes of Wikipedia, and they imagine everything else ChatGPT says is a verbatim quote from more obscure sources. But that’s probably not true; there is something special about Wikipedia that makes it particularly likely to get quoted.
Even at ~1%, this is obviously still a serious problem that AI companies have a vested interest in addressing. What happens when a user inadvertently reproduces a copyrighted work? Who will the courts find liable? I’m sure they have whole legal teams and maybe even a fraction of a data scientist thinking real hard about how to shift blame onto users.
Are AI models overfitting?
Apart from duplicates in the training data, there’s also a broader problem that AI models could potentially suffering from. Are AI models overfitting their training data?
“Overfitting” and “underfitting” are important concepts in data science, long predating so-called generative AI. You can find plenty of explainers and helpful images, like this one:
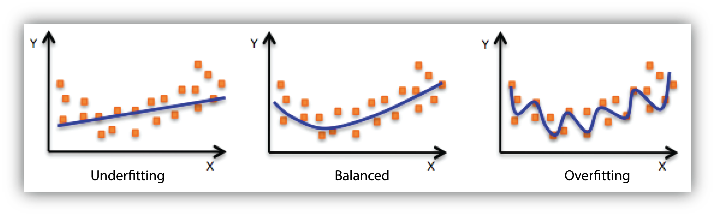
Source: AWS
When a model is overfit, it works too hard to reproduce the training data, at the expense of its ability to generalize. Overfitting makes a model look better, if you’re not careful about the measurement, while actually making the model worse. Overfitting is more likely when you have a very flexible model with insufficient training data; it can be addressed by making the model less flexible and/or collecting more training data. Another way to think about it is that underfit models suffer from bias, while overfit models suffer from variance (which I’ve discussed here).
In the context of creative generation, I am not exactly sure what this would look like, but it might manifest as a decreased ability to extrapolate towards artistic styles that do not exist within the training data. It might also manifest as recognizable reproductions of existing work. (To be clear, overfitting and duplications in the training data are distinct problems, though they may have overlapping symptoms.)
So are AI models overfit? I believe the conventional wisdom among experts is that large language models are overfit. There’s a well-known paper that argues current LLMs would benefit more from additional training data rather than additional parameters, and that implies some sort of overfitting. Google also turned up a paper that addresses the question more directly by measuring performance on grade school math.
At least for LLMs, there are some obvious incentives that cause models to be overfit. LLMs used to brag about how many parameters they have, under the theory that bigger models are stronger—but this likely made the models just more expensive and more overfit. And as I mentioned before, overfitting will make the model look better if you’re being uncareful with measurements. AI companies have an obvious interest in making their models look better, and it’s perfectly within their power to be uncareful. (See this discussion or my discussion of why you shouldn’t trust AI press releases.)
Common image generation models are a different story. I couldn’t find a concrete answer to whether they are overfit, but I’m not an expert in that area, so maybe the research is somewhere out there.
I don’t think image generators suffer from quite the same incentives as LLM models do, since they’re not producing press releases pumping up how good image generators are at grade school math. To be quite honest, image generators are kind of a footnote to LLMs–OpenAI is far larger and richer than Midjourney, inc. Companies like Midjourney probably just do the cheapest thing they can get away with.
Conclusion
It’s clearly a significant problem that both LLMs and image generators will sometimes reproduce recognizable chunks of well-known works. This could be symptomatic of duplicates in the data set, and/or model overfitting, or maybe something else. There’s good reason to suspect that LLMs are overfit, and this very well could be the result of perverse capitalistic incentives.
However, there is little reason to believe that every single output from an AI model is simply reproducing existing works. To the extent that this occurs in current models, it’s a property of the models rather than a universal property of AI. (And really, it’s still a problem even if it only happens some of the time.)
While there may be a grain of truth to the claim that “AI is remixing existing works”, it’s not a good way of understanding the issue. Likewise, the counterclaim “All art is just remixing existing work” is not very helpful. Both claims are too vague to be verifiable. And perhaps that’s by design, to produce an unresolvable disagreement.
To find a path forward, we need a more technical understanding, based on overfitting and training data quality. Though the research is limited, it’s a question for which we could in principle find answers. So I say, go forth and demand some answers.
So there’s a mathematical reason why uneducated people from noncosmopolitan environments suffer from bias … the models in their heads are underfit.
If only it were easy to convince them that their biases ought to be seen as a problem, rather than objects of pride.
I think you’re making a pun and I’m not going to respond to it. But in case you’re not, “bias” is a technical term that means something else.
I haven’t heard the “remixing existing work” comment, but I would guess it means “an AI can’t be truly creative, like a human can” but how do you measure that, and does it matter? There must be a lot of tasks that don’t require new creative ideas, but just need to produce something within the range of what people typically produce. (Like translation- my husband uses ChatGPT for translation a lot.)
I’m also curious about what overfitting would mean for an LLM. I’ve tried programming demos with neural nets before but I’m not familiar with how LLMs work.
Subjectively, I feel like models used to be more creative when they were worse and generated lots of stuff humans never would.
Many conversations involving real live people just consist of them regurgitating ideas and phrases they’ve heard elsewhere.
On a more artistic note, anybody who is at all interested in folk music must be well aware that much of that is just remixing previous work. There are entire song trees which are very obviously the result of this, for example The Raggle Taggle Gypsy and all of its variations and descendants. And there’s one verse of that (“Go saddle up my milk white steed…”) which crops up in lots of other, otherwise unrelated songs.
I’m pretty much with Marcus on this point – as far as I can see, almost all human creativity is some form of remixing.
I saw a great demonstration of this just the other day. Go to ChatGPT and ask it as nicely as you like to produce a picture of seven watches, all set to three minutes to one. Or twenty five past five. Or quarter to nine.
It’ll think for a moment, then proudly announce something along the lines of “here you go, a picture of seven watches all showing three minutes to one”… under a picture of seven watches, all clearly showing ten minutes past ten. And you can call it out, and point out that it’s wrong, and it will try again, and again, and again, and fail every time and NOT NOTICE every time.
And this is because the training data – every picture of a watch that has been posted on the internet, stolen and repurposed for training – has EVERY SINGLE watch set to 10:10, because for some reason related to liking smiling that’s what the industry has decided makes a watch look nicest. And thus as far as the AIs are concerned, that’s what a watch looks like REGARDLESS OF WHAT TIME IT’S SHOWING.
If I’d learned this two years ago, when this stuff was shiny and new and full of novelty and magic, I’d have chuckled and assumed that now that it was known it would be fixed in days, maybe weeks at the outside. But the problem has been known since before that point… and here we are in 2025, and it hasn’t gone away. I assume this is because despite appearances the models don’t “know”
(a) what a watch IS
(b) what time IS
(c) what it means for the one to be indicating the other.
As someone said – if your job can be taken away by an AI, maybe you didn’t have a proper job in the first place. To anyone whose work requires anything approaching skill, experience, knowledge or however you want to define “intelligence”, I can only see AI as another tool.
As a chemical engineer, I can look back to a time when I was still in/had just graduated university. Large chemical companies at that time still employed draughtsmen (and it was in my experience 100% exclusively men), making marks on large piece of paper with pencils to represent designs, and model-makers who would take those designs and realise them in 3d plastic constructions designed to allow people to spot glitches in the layout of huge constructions before anything more expensive than a scale model was built.
Then the computers got better.
There are still piping and instrumentation diagrams – they’re just done in AutoCAD instead of pencil.
And there are still 3d models – it’s just they’re done in packages that allow you to strap on an Oculus or similar and feel like you’re walking round the plant.
I see AI in the same terms. For people doing real jobs, it’s another potentially labour-saving device. ChatGPT, here’s a few basic facts, spin me up a presentation to the board, seven slides on subject X that I just briefed you on. OK, that structure is OK apart from these bits and this point is simply wrong… but you’ve broken my writer’s block and given me the bones of something to start with. It’s been two years and while what it can do is certainly impressive to someone who never expected chatbots to get much better than ELIZA in my lifetime, I can’t help thinking that we’re finding things they’re shit at faster than the techbros are finding ways to make them any better. They’re a useful tool for a limited number of tasks, in the right hands. And like any tool, in the wrong hands they can turn out useless shit.
The problem is, look around at (for example) the US electorate. Useless shit is what they want, what they’re prepared to vote for, what they’re prepared to buy. Who can blame techbros for connecting a pipe to your house to deliver a thousand gallons of diarrhoea every hour given that you (or enough of your neighbours) have demonstrated a willingness to sign up for that subscription service?
It’s worth noting that ChatGPT basically calls DALL-E for image generation. ChatGPT doesn’t really know what DALL-E is doing, it just trusts DALL-E to get it right–and the trust is frequently misplaced.
While the image generators inspire a lot more public discussion, my impression is they’re a lot less advanced than the LLMs–it’s a harder problem, and there’s less money in solving it. When image generators can set aside creativity, and just like, generate an accurate graph, that’s when I’ll be afraid of them replacing a lot of jobs.
Re Siggy’s comment at number 4
I liked the phase where the models added eyeballs to everything. That was creepy
Hopefully all of this LLM, generative “AI” hype settles down and we can get back to useful applications for machine learning
It’s clearly a significant problem that both LLMs and image generators will sometimes reproduce recognizable chunks of well-known works
Amazingly, that does not seem to be happening. You’d think that, if that was what was happening, there would be all sorts of “I asked for my picture back out of Midjourney and here it is” postings.
When Dall-E first came out, if you didn’t put any thought into the prompt, you’d get something very crude back; perhaps people were mistaking it for a Picasso? /s
(Addendum: I’ll do a posting on this topic. Short form is that the claimants in the copyright lawsuit regarding AI art generators stealing, cheated. I have to catch up on the case but I sure wish I was an expert for the defense, because the plaintiff’s argument is simultaneously stupid and dishonest)
I have seen posts along those lines, although I never looked too deeply at any of them. Obviously it’s impossible to assess the scale of the problem based on social media posts, or to even verify examples. Researchers should look into the question.
I have made a few thousand AI images by now and I can say with confidence the idea they’re reproducing chunks of existing images must be from some kind of cheating on the side of the person claiming it. For example, using the image directly in the prompt and rolling the dice a few dozen times, and cherry picking the ones that came closest to doing so.
Even then, the results are arguable legally different enough that it’s functionally the same as a human artist using a visual reference for a pose, which – with sufficient difference in end product – is still not only legal, but not anything any body has *ever* expected to involve credit to the original artist. In fine art, recreations of the same subject matter (the rape of leda, the pieta, the last supper, etc) get “by Fuckoglio, after Buttsacchino 1692.” But if it was Jimmy Deviantart taking the hand pose from a fashion photo for his picture of the Joaker, no credit has ever been asked for.
There are a rare few extremely over-represented images you can get reproductions of out of AI, like the coca-cola logo or the mona lisa, but even very famous art with not as many copies in existence, like the last supper? Does not come back with accurate results at all.
If the results aren’t creative enough, break the program a little. Ask for nonsense, use an image prompt that has nothing to do with the words you’re using, mash up contradictory art styles. My personal shit is quite weird – and those are the more sensible results.
–
The GothamChess YouTube channel ran a Chatbot Chess championship, with 6 chatbots and 2 genuine chess bots. The ChatBots play good openings (with a penchant for the Ruy-Lopez), but fall apart in the midgame, both playing illegal moves and making blunders that even a novice human would only do rarely (as opposed to multiple times in the game). Against Stockfish (the world’s best chess player) the chatbots would cheat themselves to a winning position and blunder it away.
It seems that there is enough board positions in the training data that the bots have done something equivalent to memorising openings, but when it comes to the point where understanding is needed it becomes clear that they lack it.
LLMs and generative art systems aren’t good at accuracy. But not all applications require accuracy. If you want a landscape for a desktop background image it doesn’t matter if it’s not an accurate depiction of a real world location. On the other hand, if you want a diagram for a scientific paper accuracy does matter (see various retracted papers). Or from personal experience, I couldn’t get a botanical illustration of a daffodil good enough to be worth using as a starting point.
Given how AIbots like ChatGPT and Midjourney work, I don’t see how anyone can argue that they *don’t* “remix… existing work”. I mean, what do you think the “training data” they’re explicitly exploiting is, you know?
@cubist,
That doesn’t seem responsive to the OP. What does that even mean to you?