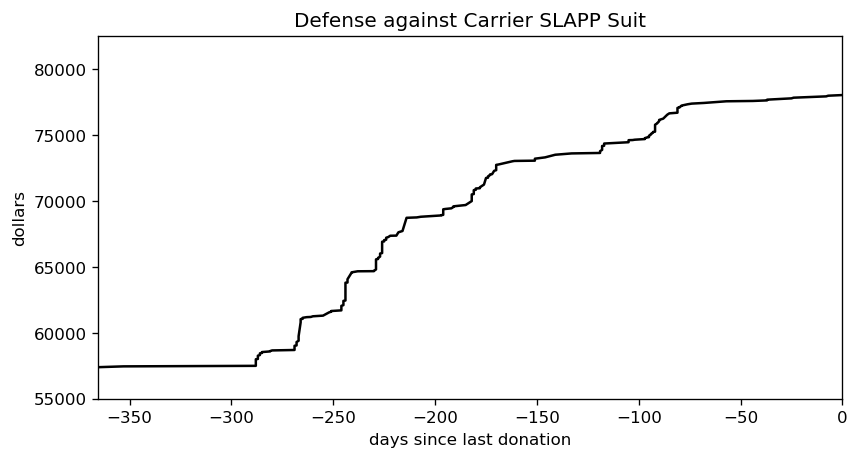
The average age of death from COVID in Alberta is 83, and I remind the House that the average life expectancy in the province is age 82. – Premier Jason Kenney, May 27th 2020.
That really caught my ear, when it came across the local news. What the hell is our Premier saying, that the elderly are expendable? It was so outrageous, I wanted to dig into it further and get the full context. The original news report I heard only had that one sentence, though, so I did a bit of research. I couldn’t find an unedited clip of his speech, but I did find a clip with one extra sentence in place.
Mr. Speaker, it is critical as we move forward, that we focus our efforts on the most vulnerable; on the elderly, and the immuno-compromised. The average age of death from COVID in Alberta is 83, and I remind the House that the average life expectancy in the province is age 82. – also Premier Jason Kenney, May 27th 2020.
That radically changes the meaning, doesn’t it? Still, I have to point out I’m getting mixed messages here. [Read more…]