If I had a word of the week, it would be “radicalization.” Some of why the term is hot in my circles is due to offline conversations, some of it stems from yet another aggrieved white male engaging in terrorism, and some from yet another study confirms Trump voters were driven by bigotry (via fearing the loss of privilege that comes from giving up your superiority to promote equality).
Some just came in via Rebecca Watson, though, who pointed me to a fascinating study.
For example, a shift from ‘I’ to ‘We’ was found to reflect a change from an individual to a collective identity (…). Social status is also related to the extent to which first person pronouns are used in communication. Low-status individuals use ‘I’ more than high-status individuals (…), while high-status individuals use ‘we’ more often (…). This pattern is observed both in real life and on Internet forums (…). Hence, a shift from “I” to “we” may signal an individual’s identification with the group and a rise in status when becoming an accepted member of the group.
… I think you can guess what Step Two is. Walk away from the screen, find a pen and paper, write down your guess, then read the next paragraph.
The forum investigated here is one of the largest Internet forums in Sweden, called Flashback (…). The forum claims to work for freedom of speech. It has over one million users who, in total, write 15 000 to 20 000 posts every day. It is often criticized for being extreme, for example in being too lenient regarding drug related posts but also for being hostile in allowing denigrating posts toward groups such as immigrants, Jews, Romas, and feminists. The forum has many sub-forums and we investigate one of these, which focuses on immigration issues.
The total text data from the sub-forum consists of 964 Megabytes. The total amount of data includes 700,000 posts from 11th of July, 2004 until 25th of April, 2015.
How did you do? I don’t think you’ll need pen or paper to guess what these scientists saw in Step Three.
We expected and found changes in cues related to group identity formation and intergroup differentiation. Specifically, there was a significant decrease in the use of ‘I’ and a simultaneous increase in the use of ‘we’ and ‘they’. This has previously been related to group identity formation and differentiation to one or more outgroups (…). Increased usage of plural, and decreased frequency of singular, nouns have also been found in both normal, and extremist, group formations (…). There was a decrease in singular pronouns and a relative increase in collective pronouns. The increase in collective pronouns referred both to the ingroup (we) and to one or more outgroups (they). These results suggest a shift toward a collective identity among participants, and a stronger differentiation between the own group and the outgroup(s).
Brilliant! We’ve confirmed one way people become radicalized: by hanging around in forums devoted to “free speech,” the hate dumped on certain groups gradually creates an in-group/out-group dichotomy, bringing out the worst in us.
Unfortunately, there’s a problem with the staircase.
| Categories | Dictionaries | Example words | Mean r |
|---|---|---|---|
| Group differentiation | First person singular | I, my, me | -.0103 *** |
| First person plural | We, our, us | .0115 *** | |
| Third person plural | They, them, their | .0081 *** | |
| Certainty | Absolutely, sure | .0016 NS |
***p < .001. NS = not significant. n=11,751.
Table 2 tripped me up, hard. I dropped by the ever-awesome R<-Psychologist and cooked up two versions of the same dataset. One has no correlation, while the other has a correlation coefficient of 0.01. Can you tell me which is which, without resorting to a straight-edge or photo editor?
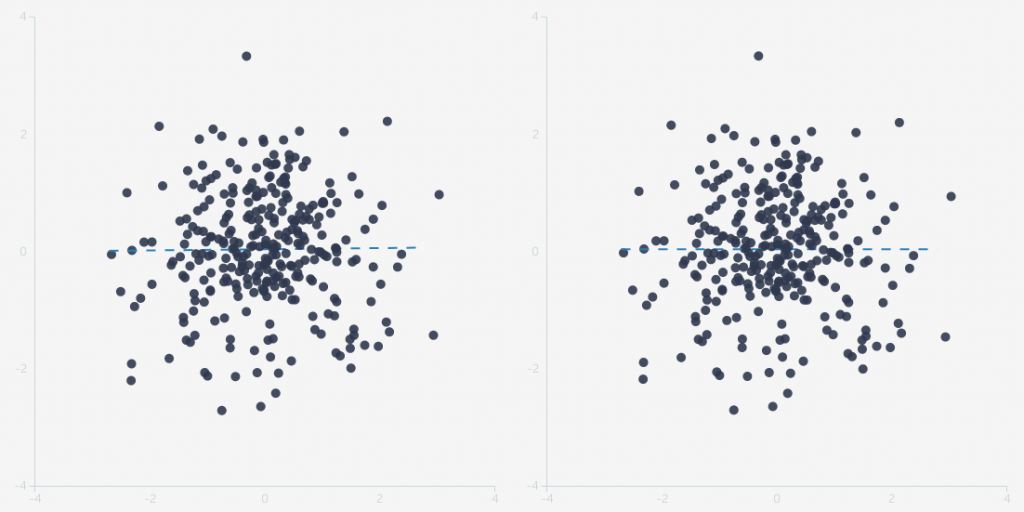
I can’t either, because the effect size is waaaaaay too small to be perceptible. That’s a problem, because it can be trivially easy to manufacture a bias at least that large. If we were talking about a system with very tight constraints on its behaviour, like the Higgs Boson, then uncovering 500 bits of evidence over 2,500,000,000,000,000,000 trials could be too much for any bias to manufacture. But this study involves linguistics, which is far less precise than the Standard Model, so I need a solid demonstration of why this study is immune to biases on the scale of r = 0.01.
The authors do try to correct for how p-values exaggerate the evidence in large samples, but they do it by plucking p < 0.001 out of a hat. Not good enough; how does that p-value relate to studies of similar subject matter and methodology? Also, p-values stink. Also also, I notice there’s no control sample here. Do pro-social justice groups exhibit the same trend over time? What about the comment section of sports articles? It’s great that their hypotheses were supported by the data, don’t get me wrong, but it would be better if they’d tried harder to swat down their own hypothesis. I’d also like to point out that none of my complaints falsify their hypotheses, they merely demonstrate that the study falls well short of confirmed or significant, contrary to what I typed earlier.
Alas, I’ve discovered another path towards radicalization: perform honest research about the epistemology behind science. It’ll ruin your ability to read scientific papers, and leave you in despair about the current state of science.
