If there is one cause of cancer, it would be genetic damage to somatic cells. So all we have to do to cure cancer is prevent all genetic damage! That’s not a very useful prescription, unfortunately; it’s rather like saying that all we have to do to prevent accidental deaths is prohibit all potential causes of injury. The causes of genetic damage are ubiquitous.
We’re familiar with some. Smoking, for instance, irritates and damages the cells of the lung epithelium, and increases the rate of cancer incidence. UV radiation damages DNA, so prolonged exposure to the sun increases the rate of skin cancer. Chimney sweeps would get covered in the carcinogenic compounds present in soot, which would accumulate in folds of skin, and had phenomenal rates of scrotal cancer. So don’t clamber around in chimneys, stay in the dark all the time, and never start smoking, and you won’t get cancer, right? Wrong. You’ve eliminated some factors that increase the incidence of cancer, but not all. You might think that if we just eliminated every cause of genetic damage we’d be safe, except that there’s one we can’t get away from.
Cell division can cause spontaneous errors. We have all kinds of error-checking molecules that try to prevent it, but nothing in the natural world can be perfect. The error rate in human cell division is very low, about 1 mistake in every 1010 cell divisions, but it’s not zero — it means that every third division by a cell line will introduce an error. Many of your tissues are full of cells that are constantly dividing — epithelia in particular are continuously shedding old cells and dividing to produce new ones — so retiring to a dark bunker and breathing filtered air and eating only pure foods untainted by carcinogens (which don’t exist) won’t reduce your cancer risk to zero. The act of living is a cause of cancer.
But, you might be wondering, how much does simple cell division contribute to cancer, compared to environmental risks? An analysis by Tomasetti and Vogelstein tries to quantify the relative risk, and comes to the conclusion that in many cases, the largest cause of cancers is simply bad luck, caused by stochastic errors in cell division, rather than any controllable environmental factors.
They accomplished this by doing a comparative analysis of different tissues in the body, by looking at the number of stem cell divisions required to produce and maintain that tissue over the lifetime of an individual, and comparing that to the frequency of cancers in that tissue. For instance, many of the cells of the brain are in a terminal state — they don’t divide any more, so the rate of cell division is relatively low. The lining of your intestine, on the other hand, is constantly shedding cells and reconstituting itself, so you’d expect the rate of stochastic genetic damage, and cancer, to be higher in the intestine than in the brain. By examining the cancer incidence in many tissues for which the number of generating stem cell divisions are known, we can get an estimate of the relative contribution of uninduced errors in cell division to cancer.
They produced a chart showing the correlation between the total number of stem cell divisions and cancer risk — it’s totally unsurprising. Actively dividing tissues are more prone to cancer.

The relationship between the number of stem cell divisions in the lifetime of a given tissue and the lifetime risk of cancer in that tissue.
The results showed that stochastic errors in cell division are the single greatest cause of cancer — it’s mostly due to bad luck, not simply due to reckless exposure to carcinogens.
A linear correlation equal to 0.804 suggests that 65% (39% to 81%; 95% CI) of the differences in cancer risk among different tissues can be explained by the total number of stem cell divisions in those tissues. Thus, the stochastic effects of DNA replication appear to be the major contributor to cancer in humans.
Again, I didn’t find the idea that chance dominates in causing cancer at all surprising, although apparently some people are a little shocked.
Now hang on, though, before you take up smoking, head off to the tanning parlor, and indulge in some naked chimney cleaning, on the assumption that we’re all doomed anyway, and we’re all going to get cancer no matter what bad habits we eschew…this is all about probability. If you were going off to the casino to shoot craps, you wouldn’t sneer at something that gave you a 10% edge on the table, would you? What these results are saying is simply that if you roll the dice, there is always the possibility of coming up snake-eyes, so you don’t get to play forever without crapping out. Unlike throwing dice, though, there are ways you can shift the odds to reduce the probability of error in real life situations.
Furthermore, we know that some environmental factors can significantly increase your risk of cancer. In the graph above, for instance, not that there are two separate entries for lung cancer, one for smokers and another for non-smokers. The Y axis is on a logarithmic scale, so you should be able to see that smoking increases your lifetime lung cancer risk more than ten-fold. Some cancers are clearly the consequence of elevated risk from environmental and genetic factors.
The authors attempted to identify which kinds of cancers were most often caused by simple bad luck (where environmental factors are not likely to be to blame) and those that are the product of additional, potentially controllable factors.
We next attempted to distinguish the effects of this stochastic, replicative component from other causative factors—that is, those due to the external environment and inherited mutations. For this purpose, we defined an “extra risk score” (ERS) as the product of the lifetime risk and the total number of stem cell divisions (log10 values). Machine learning methods were employed to classify tumors based only on this score. With the number of clusters set equal to two, the tumors were classified in an unsupervised manner into one cluster with high ERS (9 tumor types) and another with low ERS (22 tumor types).
What that means, basically, is that if you use the data that suggests a certain intrinsic rate of cancer formation that is based entirely on stochastic errors of replication, cancers that show a higher rate have an extra factor causing greater risk (ERS), while cancers with a lower rate are most likely not caused by external factors. They then let a computer classify different kinds of cancers to come up with a chart that classifies cancers into R-tumors, those that are most likely caused by uncontrollable errors in replication, and D-tumors, those that have significant environmental contributors.
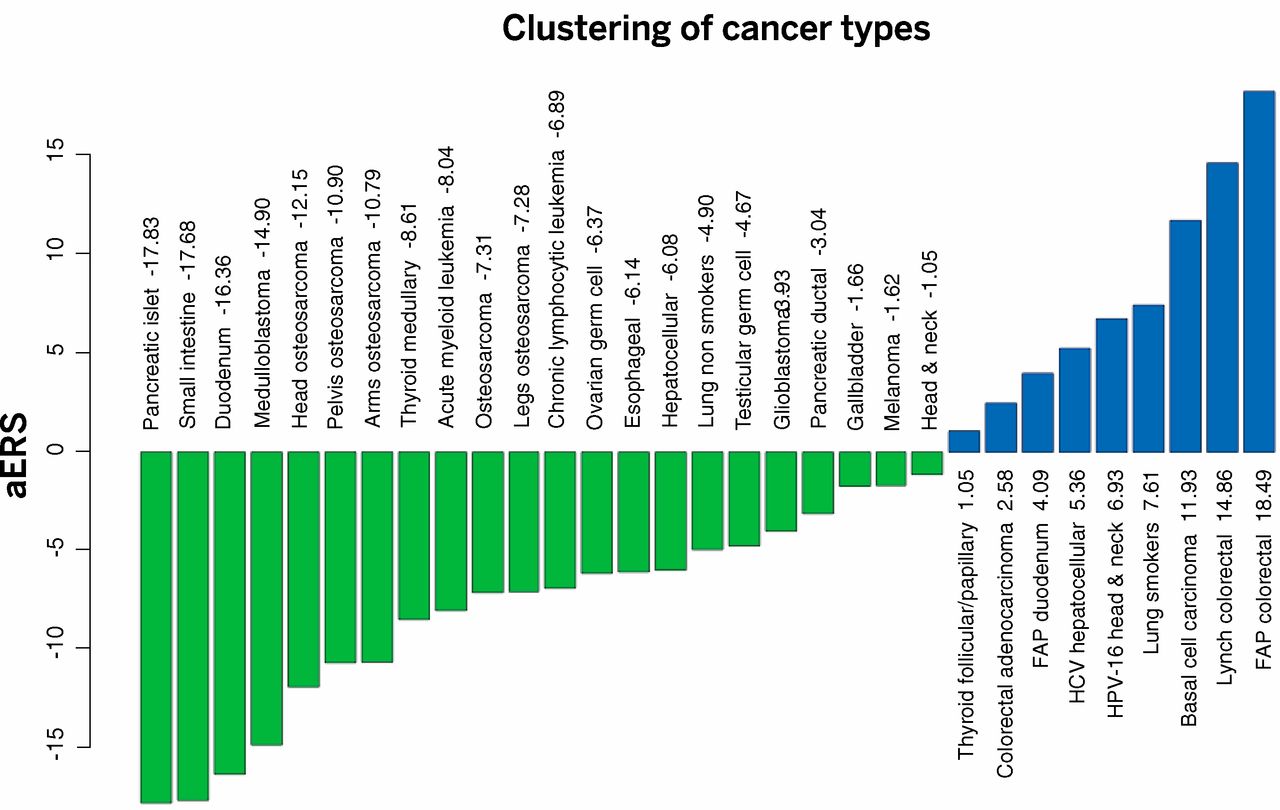
Stochastic (replicative) factors versus environmental and inherited factors: R-tumor versus D-tumor classification. The adjusted ERS (aERS) is indicated next to the name of each cancer type. R-tumors (green) have negative aERS and appear to be mainly due to stochastic effects associated with DNA replication of the tissues’ stem cells, whereas D-tumors (blue) have positive aERS. Importantly, although the aERS was calculated without any knowledge of the influence of environmental or inherited factors, tumors with high aERS proved to be precisely those known to be associated with these factors.
This is useful information. It suggests that it’s pointless to go searching for environmental causes of R-tumors — the incidence of pancreatic cancer, for example, is accounted for by the error rate in cell replication alone, and it’s unlikely that any factor in the environment makes a significant contribution in the general population (it does not mean that there is nothing that could cause pancreatic cancer, only that it can’t be a common risk factor). Meanwhile, colorectal and lung cancers do have a significant risk beyond what can be accounted for by stochastic errors, so pursuing a reduction in exposure to risk factors, like diet and smoking, can have a useful role in reducing the incidence of these cancers.
Another important caveat: this study says something about the nature of causal agents for certain kinds of cancer. It says nothing about the treatment of cancer. It says that cancer is an inevitable consequence of having populations of dividing cells, and that many cancers are probably not caused by external agents, but that does not mean, of course, that treatment is futile. It actually means that treatment is even more important — that we can never have a world where no one gets cancer, so we’d better be effective in stopping cancers once they start.
(By the way, I stole the title from Raup’s book, Extinction: Bad Genes or Bad Luck?, which says the same thing about the extinction of species. It’s often just a case of bad luck, and can’t be pinned on something specifically bad about the species or some factor in its environment. Chance is important at all levels of biology.)
Tomasetti C, Vogelstein B (2015) Cancer etiology. Variation in cancer risk among tissues can be explained by the number of stem cell divisions. Science 347(6217):78-81.
Bob O’Hara and GrrlScientist have serious reservations about the paper. I think they’re right that 65% number is rough and might easily wander as more data comes in, but I also think their objections are purely statistical and not well-grounded in the reality of the phenomenon. For example, this argument:
So where did this two-thirds ratio come from? It is the proportion of variation in the log of the cancer risk that can be explained by cell divisions. But this variation could be the same regardless of whether the baseline risk is high or low. For example, the depth of the water in the Marianas Trench goes up and down with the position of the moon, so this explains a bit of the variation in its depth. But that reveals bugger all about the absolute depth of the trench.
The first couple of sentences are exactly correct, and important for understanding the paper. They are only looking at the causes of variation in rates of different cancers. The rest is also correct in the abstract: conceivably, all of the cancer causes could be swamped in their magnitude by a great deep sea of completely unknown agents — so there could be a Mystery Factor X that is the primary cause of all cancers, which is just currently unidentified, so all Tomasetti and Vogelstein are looking at is minor causes of variations in waves on the surface.
Except…well, O’Hara and GrrlScientist even notice this little fact:
So, what proportion of cancers are due to bad luck? Unfortunately it’s difficult to tell from the paper. The figure from the paper is on the log scale, and if we extrapolate the model to zero (no cell divisions), we’d see it assumes there is no risk of cancer.
Exactly. That’s what we’d expect if the magnitude of Mystery Factor X was 0, and the baseline rate of somatic errors leading to cancer was set by the replication error rate.
I’ll also add that if they were correct, and there were a gigantic source of cancer-causing errors in all tissues regardless of their replication rate, that would only make Tomasetti and Vogelstein’s case stronger, that the controllable, environmental causes of cancer would be even smaller than the 35% suggested by their paper.
There is also some reasonable concern that the paper includes only a subset of cancers — there are some big, important ones like breast and prostate cancer that are not included. That’s because they could only include cancers in tissues for which they had data on the stem cell population and number of lifetime divisions; if you’re looking for correlations between X and Y, you can’t include data for which you only have X values.

Best way to avoid cancer is to stop aging. But the alternative to aging is worse.
Earlier detection of cancers would increase the odds of successful treatment as well, so it would make sense to come up with better cancer detection tests and making them more widely available to the public.
This article suggests that the bad luck angle is lazy journalism?
http://www.theguardian.com/science/grrlscientist/2015/jan/02/bad-luck-bad-journalism-and-cancer-rates
Daz
So that’s one up for the Grauniad!
Some people are ideologically opposed to the role of chance in our lives.
Surprising: melanoma is on the R side of the graph? (Albeit not by much). I thought the epidemiology (higher among whites living in sunny climes) had pretty much established that UV exposure was a significant risk factor. And basal cell carcinoma is well up on the D side. (I’ve had BCC, presumably as pay-back for all the sunburns I got when I was a kid running around shirtless in the July sun. Fortunately, it’s among the most trivially treatable and never-worry-about-it-again cancers).
Sad thing about smoking is that while cigarette smoking has decreased substantially, hookah smoking of tobacco (which is just as bad, if not worse, given the increased number of “puffs per hour” they induce) seems to becoming the latest fad among teens and young adults. I watch a fair amount of YouTube, and I can’t recall the last time I saw anyone smoking a cigarette while streaming, vlogging or involved in a podcast, but it’s not all that uncommon to see someone sucking on a hookah pen.
Looks like we’re going to have to bat down the “cool factor” of smoking all over again…
I may be missing something, but at first glance, it does seem that the authors are lumping anything that has a uniform influence across all cancers into the category of “luck.” That makes some sense. But is still a rather large assumption in the take-away message.
Can the data be used to estimate the “best” cancer risk that could be achieved?
Btw, natural radioactive radiation is another risk that is hard to avoid.
The Guardian article was terrible at explaining its problem with the science reporting, particularly since the two reports I’ve read seemed clearly to state that there were indeed cancers where lifestyle choices increased the chances of cancer, especially for lung cancer. I would have thought that an 18X increase in chances of lung cancer from smoking etc. could be interpreted as implying about 80 out of a hundred people “won” the lung cancer jackpot because smoking increased their. And if that sounds incredibly redundant, that’s because it is. The only takeaway I’m getting from the article is that it is right and proper to blame cancer victims for their poor choices. But that seems awfully harsh, so what am I not getting? Perhaps PZ would find it educational to discuss further?
Typo above, that should have been 90 out of a hundred!
Where is breast cancer? Where is ALL? Where is prostate cancer? These are big players! Seems to me if you are looking for a correlation then you should include all forms of cancer–otherwise–who knows where the line would go? There seems to be a lot missing here.
You mean i have been cultivating an almost transparent skin for nothing? Who am i kidding, i already knew that….
They only included cancers where the number of stem cell divisions to produce the affected tissue was known.
So glad PZ unpacked this article. When my Dad died of brain cancer in July I emailed PZ, as a fellow former Lutheran, on how to approach the eulogy I would be saying in my former church. The pastor called my Dad’s illness unnatural and the work of the devil. I am glad I got to speak after him and hope I negated the irrationality at least a little.
Daz365365 might care to read a bit deeper into the claim that “the bad luck angle is lazy journalism”.
At the end of the link you posted, but don’t seem to have followed, you will read that “bad luck” features in both the press release that accompanied the paper and the abstract of the paper itself.
The article here is the one that the person who wrote the drivel in The Guardian should have written. But, like their ability to do decent research before writing, their statistical skills probably weren’t up to it.
It is nice to see a proper debate of the paper rather than the over excited dribblings of the self-appointed scourges of the media, few of whom would recognise deadline if it bit them in the rear end.
“Chim chiminey. Chim chiminey. Chim chim cher-ee! A sweep is as lucky. As lucky can be.”
Maybe this applied to the ones who made it to adulthood without getting scrotal cancer.
Other than that, I agree that the results don’t seem too surprising. Genes and environment affect probabilities, but cancer almost always comes as an unwelcome surprise. There does seem to be a certain mindset that wants to rule out chance and explain everything in terms of things that are under human control. It’s natural for people to want to think that if they just “do everything right” that bad things won’t happen to them, but I would think that experience with games of chance, let alone real life, would correct this misconception.
Thanks PZ. But isn’t that a huge limitation on the conclusions?
It means the data set is limited, but is not necessarily a limit on the conclusions.
The authors of the study share a large portion of the blame. They write “Our analysis shows that stochastic effects associated with DNA replication contribute in a substantial way to human cancer incidence in the United States.”
This is patently false. They show that carcinogenesis correlates heavily with mutation rates. But what makes the mutation *harmful* is the key question. They assume it’s random but they have zero evidence that it is. What makes Russian roulette dangerous correlates with the frequency at which you play the game. But the cause of the harm is that the gun has a bullet. And there is nothing random about that.
Fact is, Science wouldn’t be interested in publishing a study that states a finding that is highly predictable (the more you mutate the worse you can get). They know what they’re doing. The writing was twisted precisely so that all the media of the world would pick it up with misleading titles blaming bad luck.
And people wonder why there’s such increasing skepticism toward science journals…
Perhaps a little honesty would help…
^Comment belongs to someone else, but they said it better than I could.
No, Virginia, there is no Santa Claus. Not any more…
The technical challenge here becomes the whole issue with screening tests, sensitivity, positive predictive value, incidence and false positive results.
Nick Nieves #20
So if I’m following, I think that by “it” you mean whether or not a particular copying error causes cancer. How would we assume harmful errors are distributed among all errors? The most reasonable null hypothesis is that they are distributed uniformly. So if you want to claim some other distribution, you would need to provide evidence to support that.
Saying, “we were unable to find evidence not explained by the null hypothesis” is a little more precise, but not really different from saying “mostly due to chance, as far as we can tell.”
I am not sure what kind of positive evidence you would accept to support the claim that it is due to chance. The best you can do is fail to find any correlation with a controlled factor (please correct me if I’m wrong).
Nick Nieves, I don’t even understand your argument.
So you’re proposing a non-random source of mutations? What?
But that’s an accurate description of the story, not misleading at all. They’re saying that controllable causes of cancer provide a smaller contribution to overall cancer rates than the baseline mutation rate — that even if you were living in a perfect environment that provided no external inducers of cancer, you’d still have a significant frequency of cancer occurrence. Do you think that’s false? Why?
After more reading on the issue, it appears as though I was incorrect in my opinion. If I could have my previous comments removed, that would be much appreciated.
Well, my friends have informed me that the root cause of all cancer is “holding on to resentment.”
I am trying to forgive them for that.
I wish I understood what this antipathy to chance was all about. Here’s another example:
Yes, it does. It’s saying that two thirds of cancers are due to chance events, and since the consequence, cancer, is invariably bad, I think it does mean that the cause is bad luck.
P Z Myers:
“They’re saying that controllable causes of cancer provide a smaller contribution to overall cancer rates than the baseline mutation rate — that even if you were living in a perfect environment that provided no external inducers of cancer, you’d still have a significant frequency of cancer occurrence.”
It still seems to me their analysis assumes that any external inducer (or preventive) will be selective in its action. If drinking coffee halves the rate of all cancers for those who drink it, their analysis would not see that, because cancers still would be determined by baseline mutation rate, in both coffee drinkers and the unlucky coffee abstainers.
True. But that assumes the existence of a cancer preventer of unknown identity…and also, unlike your coffee example, one that is universally used by all people, so that it doesn’t appear as a variation in incidence.
Looks like a nice paper.
Maybe I’m missing some subtleties, but the basic point about variation and systematic “elevated risk” seems completely consistent with the data as well.
If you assume that only dividing cells are at risk for cancer causing mutation(s), that mutations are essentially random, and that the presence of certain stressors increase mutation rates, you’d still expect the highest rates to be in rapidly dividing cells, and the rate in cells that don’t divide to be roughly zero. Basically it’s increasing “cancer risk per division.” (Some toxins trigger more division in response to damage–HCV hepatocellular tissues being an example if I understand correctly.)
In a crude model, the increase in risk would depend on the distribution of a stress factor and the rate of division in the tissue. So UV radiation only increases risk in the skin, and HCV primarily in the liver, but others would be more widely distributed.
Am I wrong in thinking this also supports the “no minimum dose” concept in modeling cancer rates epidemiologically? Slight doses of a carcinogen just give a slight possible increase to some number of cells of something ‘bad’ happening during division.
If you look at the cancers with the highest lifetime risks (~10% or more), there are six: lung (smokers), HPV head & neck, HCV hepatocellular, basal cell, lynch colorectal and FAP colorectal. Of those, all have known environmental or genetic risk factors. Even if the lifetime risks of many cancers (such as pancreatic or small intestine) is driven more by stochastic errors of replication than genetic predisposition or environmental factors, you are 100x less likely to get any of those cancers, so the overall risk of cancer in the population is still going to depend largely on genetic predisposition and environmental factors.
An inevitable consequence of having populations of dividing cells? We can never have a world where no one gets cancer? Thanks a lot, Un-intelligent Designer!
P Z Myers: “…and also, unlike your coffee example, one that is universally used by all people, so that it doesn’t appear as a variation in incidence.”
No. That’s my point. If half the population is doing something that reduces their risk of cancer, but reduces it the same for all kinds of cancers across the board, it seems to me the kind of analysis the authors performed would not see that. Their analysis is going to see the effect of external inducers (or preventers) only if those external causes act differentially on different kinds of cancer.
I may be missing something. But that sure seems a consequence of how they examined the data.
Now, I’ll admit, most things that jump to mind as an external cause, from tobacco use to farming, do act differentially. But it is a bit of a leap to lump everything else into luck, without at least noting the assumption behind that.
@33 garnetstar
Not necessarily. Neither blind mole rats nor the related naked mole rats develop cancer.
I’m not sure why this study caused such surprise either (well, I can see why it’s relevant data, but every article I read made something spectacular and baffling out of it). The process that pushes life forward is the same that also ends it. I do believe the oldest person ever to live was long-time smoker. Like everything else in the universe, it’s all down to probability. But our little reptilian brain is wired to rationalize us out of fear and uncertainty, so we rely on magic recipes: gluten-free, paleo, vegan, toxin-free (whatever that is), etc. You can try to better your odds, but it’s not certain.
That would nicely explain why cancer is limited to humans… oh. Oops.
Of course.
I’m sure they do, just less often than other mammals because their metabolism is so slow. (Breathing is a huge cause of cancer.)
Cancer (except where induced by viruses) is remarkably rare in birds, and nobody knows why; but it’s still not absent.
Naked mole rats are cancer-resistant. They do get cancer.
David Marjanović: “Cancer .. is remarkably rare in birds…”
And most birds have a metabolism that would make us look like … well, mole rats.
The literature also suggests that mole rats have some other adaptations to resist cancer: they seem to have a more aggressive apoptotic mechanism, and produce a couple of signals that somehow, in ways nobody seems to have explained, suppress cancers.
@40 PZ
The point being that cancer is not an inevitable consequence of having populations of dividing cells.
Man, logic really is not your strong suit.
Cite your refutation.
@43 Nerd
Sure Nerd. Here’s one.
tl;dr No spontaneous mutations and very resistant to carcinogens that induce cancer ~ 100% of the time in mice and rats. So yes, they can be ‘forced’ to develop cancer after long periods of time and treatment with very strong carcinogens but they don’t develop them normally.
Pronounced cancer resistance in a subterranean rodent, the blind mole-rat, Spalax: in vivo and in vitro evidence
Irena Manov1, Mark Hirsh2, Theodore C Iancu3, Assaf Malik1, Nick Sotnichenko4, Mark Band5, Aaron Avivi1*† and Imad Shams1*†
BMC Biology 2013, 11:91 doi:10.1186/1741-7007-11-91
Background
Subterranean blind mole rats (Spalax) are hypoxia tolerant (down to 3% O2), long lived (>20 years) rodents showing no clear signs of aging or aging related disorders. In 50 years of Spalax research, spontaneous tumors have never been recorded among thousands of individuals . Here we addressed the questions of (1) whether Spalax is resistant to chemically-induced tumorigenesis, and (2) whether normal fibroblasts isolated from Spalax possess tumor-suppressive activity.
Results
Treating animals with 3-Methylcholantrene (3MCA) and 7,12-Dimethylbenz(a) anthracene/12-O-tetradecanoylphorbol-13-acetate (DMBA/TPA), two potent carcinogens, confirmed Spalax high resistance to chemically induced cancers. While all mice and rats developed the expected tumors following treatment with both carcinogens, among Spalax no tumors were observed after DMBA/TPA treatment, while 3MCA induced benign fibroblastic proliferation in 2 Spalax individuals out of 12, and only a single animal from the advanced age group developed malignancy 18 months post-treatment. The remaining animals are still healthy 30 months post-treatment.
Chris61, while your post contains an abstract, there is no link to the original paper.
Gee, this isn’t a normal line but seems to have a mutation which is harder for normal mutations to make the cells carcinogenic.
And your point in toto is what?
@45 Nerd
Okay I’ll try again. Rodents are small mammals with, for the most part, short lifespans (2-3 years). They also develop cancers both spontaneously and in response to many of the same chemicals that will cause cancer in human beings. But unlike mice (of the genus mus) and rats (of the genus rattus), blind mole rats (of the genus spalax) have both very long lifespans (25+ years) and do not spontaneously develop cancers. Blind mole rats are ‘normal’ rodents in the same way that human beings are ‘normal’ primates; in other words they are the product of evolution.
Speaking as a statistician, in my judgment this paper goes completely off the rails at the point where they take the product of the two numbers (on the log scale), call that a score, and throw it at k-means clustering. If you tell k-means to give you two clusters, it’ll give you two clusters whether or not there’s actually two populations present. And in this case, they’re running it on 1D data, so all the clustering is doing is choosing the dividing line between two categories in a way not motivated by any particular scientific/statistical/predictive merit. All of the subsequent work (and in particular, the R vs. D dichotomization) is a kind of statistical confabulation masquerading as scientific reasoning.
In point of fact, that first 2D plot is a thing of beauty, and it readily displays all of the information in the data. Taking the product of the two numbers in order to dimensionally reduce the 2D data to 1D just throws away some of that information. I salute the authors for collating information about the 31 cancers and generating a truly scientifically valuable display of the way lifetime risk varies with stem cell division count across tissue types. I just wish they’d stopped there — but I guess a paper in Science can’t have just one figure.
(Karmakat #1: according to the graph, the best way to avoid cancer, at least on a tissue type basis, is to be made entirely of bone ;-) .)
I have a hard time believing that the conclusion of this study is that most cancers are a result of cell division-induced mutations. My question is: what would be the rate of correlation of cell division with cancer rates if cell division itself resulted in zero cancer-causing mutations?
As long as cancer usually requires more than a single mutation to get started, cancer rates will be highly correlated with cell division rates regardless of the cause of those mutations. If cancer requires two mutations to get going, for instance, then the initial mutation (regardless of cause) in a fast-dividing cell line may result in a much larger number of descendant cells which could then receive another mutation.
It may also be the case that since cancer is a disease of cell growth that slow-growing cell lines require more changes than fast-growing cell lines in order to result in a dangerous tumor.
Thanks very much for writing this. I’ve spent too much of the last 48 hours trying to say much the same thing. I’ve been baffled by the indignation that some people seem to show at the suggestion that random chance plays a role in out fate. It’s almost like the attitude of creationists to evolution.
Oh dear. My New Year resolution was to drink less, but it is only the 4th of January and biologists have been allowed to multiply logarithms together in Science.
I agree with Corey at #47. Just publish Fig 1 then stop.
Consider two cancers: gall bladder and AML. They have similar lifetime risks, about 10^-2.5 or 1 in 300. But gall bladder cells have about 1/1000 of the number of stem cell divisions. That leaves a massive unexplained cause of gall bladder cancer beyond stochastic errors in stem cell division. But their ridiculous Fig 2 classes gall bladder cancer as mainly due to stochastic errors.
Shameless self promotion. My Science-Based Medicine post for tomorrow discussing this paper will try to explain this very issue.
Yes, much of the criticism of this paper flows from an assumption that a lot more cancer is due to environment and thus potentially preventable than the evidence actually supports. More tomorrow. :-)
There are some things I found problematic with the paper.
First, the part I agree with and found interesting ; I am not surprised firstly that cancer risk should be connected to the number of stem cell divisions available – for it affords the time for cellular lineages to acquire additional mutations.
I have problems with them attributing everything that isn’t associated with lifestyle factors to be the product of stochastic errors in cell division; more precisely attribution to errors in cell division; this is because all mutagenic processes, pretty much, are stochastic – while it is possible to suggest, given a certain capacity to repair DNA damage and the rate of mutagenesis by carcinogens, be they external or internal , and while some of these mutagens have an affinity for certain DNA sequence motifs, ultimately, which of those sequence motifs gets hit by a mutation is a matter of chance.
The reason I disagree with them blaming cancer risk on cell division errors is that by and large the most ubiquitous mutational signature that exists is one that corresponds to aging (Ref 1) , which is generated by the spontaneous deamination of methylated cytosines – a stochastic process nonetheless, but not one comprised of errors in cell division. There are also multiple signatures associated with endogenous DNA damage that are not induced by cell division but are rather associated with repair defects or enzymatic activity of, for instance, the APOBEC family of enzymes. There are also Reactive Oxygen Species induced mutational processes to boot (Ref 2).
Ultimately, PZ, I think the dichotomy in your title is false; even with bad genes, you still need bad luck to get cancer, because often those bad genes (or for that matter, external carcinogens) only elevate the odds of you having bad luck – ultimately, even the most well defined collection of mutational processes is stochastic – external or internal, and where mutations occur, and what happens to the clonal variants they generate, both involve a great degree of luck and chance and probabilities.
References
Ref 1 – http://www.nature.com/nature/journal/v500/n7463/full/nature12477.html
Ref 2 – http://www.nature.com/nrg/journal/v15/n9/full/nrg3729.html
@Corey
You’re right – I am not sure they tested if 2 clusters were the most optimal solution; for most tumour classification projects that press clustering into service we’re required to demonstrate that the silhouette width/cophenetic correlation coefficient are indicative of the best fit. Also – I hadn’t picked up on the 1D partitioning (surely it would be more optimal to cluster with two dimensions and see what patterns emerge?).
PS – is it possible to split a 1-dimensional array into three or more points by k-means or another partitioning method and still evaluate what the most robust solution is?
As I wrote most of the Guardian piece, IU tihnk i have tpo correct a couple of PZed’s errors…
That argument would be correct if he authors had looked at actual cancer cases, and asked about the probabilities that an individual gets cancer. But the authors of the paper looked at cancer rates, in effect the estimated probabilities after averaging over a lot of dice rolls.
Trivially, all cancers are a result of bad luck: they strike randomly. What is more intersting is what affects the rates of cancer. The paper shows really nicely that rate of cell division explains some of the variation in what cancers people get, but it does little to investigate other possible causes. One of the commenters on our piece pointed out that the the cancer rates data average over all other factors(*), so they implicily exclude a lot of variation which they hthen dismiss as being minor compared to luck. It’s like using annual temperatures to argue that snowfall isn’t a problem in Minnesota.
You mis-understood our point, and what hte authors did (and didn’t do). The authors fitted a model assuming the magnitude of Mystery Factor X was 0, but never actually tested it. So the mystery factor could be much larger than zero, but they would never had noticed. More formally, if R is the cancer rate and D is the rate of cell division, then the authors for the model R = aR^b. But if there’s another factor that’s independent of cell division then the model should be R = aR^ b + c. You can’t simply set a priori c=0 and then argue that c is unimportant.
(*) for some cancers the authors do present figures for the cancer with different genetic and environmental factors, but don’t systematically look at this variaiton: they then treat every cancer as indepepndent.
I also thought the second chart was a bit weak. Why not just say some cancers have an incidence greater than is predicted from replication errors alone, and leave it at that? The attempt to find a statistical justification for lumping them into two distinct categories felt like reaching, to me.
@16 Michael Kenward
It’s not my claim I posted the guardian piece here to provide another opinion
I did follow it, but I got the impression that the whole point of the piece was to warn against relying on abstracts and press releases.
The guardian piece was written by a biostatisician and an evolutionary biologist so I’m sure their statistical skills exceed mine.
I’m not a scientist and as a layperson it’s not worthwhile for me to try to decipher scientific papers, so I defer to the experts, but as we see here with lots of healthy debate, sometimes the experts disagree.
We shouldn’t see this as a bad thing. It’s an example of science not being dogmatic, but we shouldn’t accuse others of ignorance because they came to a different conclusion. But rather, see it as a sign that maybe more discussion or research is needed.
I agree on the first part of the paper (with significant reservation for Figure 1 itself: why would you make a figure with no ticks on the axis?). However, I really cannot make sense of the second part.
From the supplementary, they simply used a product of two log values from Fig 1 as ERS (verbatim from their method: “ERS = log10 r x log10 lscd. Note that log10 lscd and log10 r are simply the log10 of the x- and y-coordinates of each point in Fig 1, …”).
So I really don’t agree with PZ that this product (ERS) “suggests a certain intrinsic rate of cancer formation that is based entirely on stochastic errors of replication”. Actually I really don’t think that ERS value represents anything at all. In the supplementary they said a product makes more sense than a ratio between the two values. But what I really want to know is: why would anyone use a product or a ratio between two log values at all? The math in me doesn’t check out.
Also, clustering on single dimension values, no matter what method they used, didn’t make sense to me either. So I would say, although this paper showed quite good stuff on the first part, the second one really ruined everything.
Of course I could be very wrong, and I really would appreciate it if someone can help me make sense of anything in the second part.
Seems that I should have read @ 47 and @ 50 before posting…..
Ok.. Kind of wondering.. My brother some times hears about things that I don’t, but then.. sometimes both he and my dad are total twits, and get some things wrong. So.. I here that there is some guy who, dying of cancer, has allowed himself to be a test subject for disease, because his cells are kind of missing *every* single receptor site that viruses tend to use to get into them.
Figured I would mention this, because, well.. its kind of a major drawback, if true, right.. Because one of the only likely long term solutions to cancer will be gene repair, and that sort of repair relies on existing viral agents, to delete and insert repaired genes into the broken DNA. But, if viruses can’t find any point to latch onto, to inject the repaired genes, then.. the only methods to fight cancer are chemo, and other, non-genetic ones. I.e., you would be effectively immune to everything on the planet, but.. getting cancer would be a virtual death sentence.
Whales can avoid cancer for 200 years: “Scientists sequence genome of bowhead whale—longest-lived mammal http://phys.org/news/2015-01-scientists-sequence-genome-bowhead-whalelongest-lived.html
Not if you can do whatever trick birds use.
(And I didn’t know mole rats used other tricks than just low metabolism.)
This looks like something a reviewer requested: “Haaa! You say there are two distinct categories – statistical test, or it didn’t happen!1!!!”
I’ve been that kind of reviewer myself. Fortunately I was set straight before the manuscript was accepted.
David Marjanović
Mole rats make a high molecular weight hyaluronic acid, an oligo/poly (where’s the cutoff point?) saccharide, to keep their skin supple. It helps to suppress tumors. Knock out the formation of the hyaluronic acid and the mole rats form tumors as would be expected.
Okay, so cancer is a statistical result of cell division, but what about externalities that affect cancer cell proliferation?
There’s been research that suggests that diet (i.e., certain foods, specifically those in the cruciferous and allium families) can profoundly suppress cancer cell proliferation (described here).
damiki @63: there are externalities that affect cancer cell proliferation. But if you have an inborn genetic risk of cancer (“bad genes”) of x, a cancer-causing mutation rate (e.g. “bad luck”) of y, and have an externality-induced risk of z, your probability of developing cancer is thus x + y + z. While z is likely nonzero, the point of this paper is that z is likely smaller than x or y, and that y is bigger than x (for most values of x – BRCA and such exist).
—
Nerd @62: nine. An oligosaccharide has < 9 monomer segments, and polysaccharide has ≧ 9.