[Part 1]
the concept of “learning” within the Standard Social Science Model itself tacitly invokes unbounded rationality, in that learning is the tendency of the general-purpose, equipotential mind to grow—by an unspecified and undiscovered computational means—whatever functional information-processing abilities it needs to serve its purposes, given time and experience in the task environment.
Evolutionary psychologists depart from fitness teleologists, traditional economists (but not neuroeconomists), and blank-slate learning theorists by arguing that neither human engineers nor evolution can build a computational device that exhibits these forms of unbounded rationality, because such architectures are impossible, even in principle (for arguments, see Cosmides & Tooby, 1987; Symons 1989, 1992; Tooby & Cosmides, 1990a, 1992).[1]
Yeah, these people don’t know much about computer science.
You can divide the field of “artificial” intelligence into two basic approaches. The top-down approach outlined modular code routines like “recognize faces,” then broke those down into sub-tasks like “look for eyes” and “find mouths.” By starting at a high level and dividing these things down into neat, tidy sub-programs, we can chain them together and create a greater whole.
It’s never worked all that well, at least for real-life problems. Take Cyc, the best example I can think of. It takes basic facts about the world, like “water is wet” or “rain is water,” and uses a simple set of rules to query these facts (“is rain wet?”). What it can’t do is make guesses (“are clouds wet?”), nor discover new facts on its own, nor handle anything but simple text. Thirty years and millions of dollars haven’t made a dent in those problems.
Meanwhile, the graphics card manufacturer NVidia is betting the farm on something called “deep learning,” one of several “bottom-up” approaches. You present the algorithm with an image (or sound file or object, the number of dimensions can be easily changed), and it maps it to a grid of cells. You toss a slightly smaller grid of cells on top of it, and for each new cell you calculate a weighted sum of the nearby values in the previous grid, weights that are random to start off with. Repeat this several times, and you’ll wind up with a single cell at the end. Assign this cell to an output, say “person,” then rewind all the way back to the start. Wash, rinse, and repeat until you get another single cell, then at least enough single cells to handle every possible solution. All of these single cells have a value associated with them, so that “person” cell might give the image 0.7 “person”s. Having cataloged what’s in the image already, you know there’s actually 1.0 “person” there, and so you propagate that information back down the chain. Prior cell weights which were pro-person are increased, while the anti-person ones are decreased. Do this right to the bottom, and for every input cell, then repeat the process for a new image.
It’s loosely patterned after how our own neurons are laid out. Biology is a bit more liberal with how it connects, but this structure has the virtue of being easy to calculate and massively parallel, quite convenient for a company which manufactures processors that specialize in massively parallel computations. NVidia’s farm-betting comes from the fact that it’s wildly successful; all of the best image recognition algorithms follow the deep-learning pattern, and their success rates are not only impressive but also resemble our own.[2]
Heard of the AI that could play Atari games? Emphasis mine:
Our [Deep action-value Network or DQN] method outperforms the best existing reinforcement learning methods on 43 games without incorporating any of the additional prior knowledge about Atari 2600 games used by other approaches … . Furthermore, our DQN agent performed at a level that was comparable to that of a professional human games tester across the set of 49 games, achieving more than 75% of the human score on more than half of the games […]
Indeed, in certain games DQN is able to discover a relatively long-term strategy (for example, Breakout: the agent learns the optimal strategy, which is to first dig a tunnel around the side of the wall allowing the ball to be sent around the back to destroy a large number of blocks; …). […]
In this work, we demonstrate that a single architecture can successfully learn control policies in a range different environments with only very minimal prior knowledge, receiving only the pixels and the game score as inputs, and using the same algorithm, network architecture and hyperparameters each game, privy only to the inputs a human player would have.[3]
This deep learning network has no idea what a video game is, nor is it permitted to peek at the innards of the game itself, yet can not only learn to play these games at the same level as human beings, it can develop non-trivial solutions to them. You can’t get more “blank slate” than that.
This basic pattern has repeated multiple times over the decades. Neural nets aren’t as zippy as the new kid on the “bottom-up” block, yet they too have had great success where the modular top-down approach has failed miserably. I haven’t worked with either technology, but I’ve worked with something that’s related: genetic algorithms. Represent your solutions in a sort of genome, come up with a fitness metric for them, then mutate or randomly construct those genomes and keep the fittest ones in the pool until you’ve tried every possibility, or you get bored. Two separate runs might converge to the same solution, or they might not. A lot depends on the “fitness landscape” they occupy, which you can visualize as a 3D terrain map with height representing how “fit” something is.
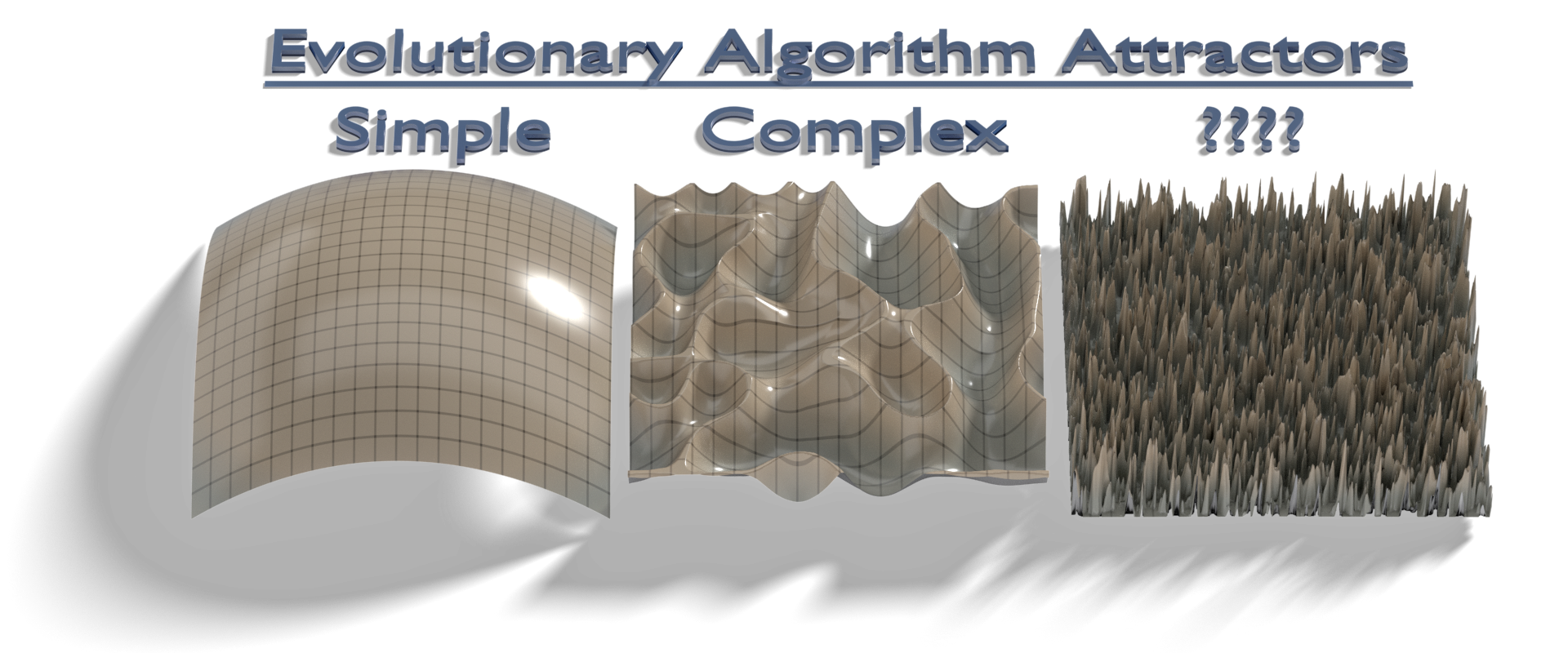 That landscape has probably got more than three dimensions, but those aren’t as easy to visualize and they behave very similarily to the 3D case. The terrain might be a Mount Fiji with a single solution at the top of a fitness peak, or a Himalayas with many peak solutions scattered about but a single tallest standing above them, or a foothills where solutions are aplenty but the best solution is tough to find.
That landscape has probably got more than three dimensions, but those aren’t as easy to visualize and they behave very similarily to the 3D case. The terrain might be a Mount Fiji with a single solution at the top of a fitness peak, or a Himalayas with many peak solutions scattered about but a single tallest standing above them, or a foothills where solutions are aplenty but the best solution is tough to find.
All of these take the “bottom-up” approach, the opposite of the “top-down” one, and work up from very small components towards a high-level goal. The path to there is rarely known in advance, so the system “feels” its way there via evolutionary algorithms.
That path may not go the way you expect, however. Take the case of a researcher, Dr. Adrian Thompson, who used an evolutionary algorithm to find the smallest computer processor that could sense the difference between two tones.
Finally, after just over 4,000 generations, the test system settled upon the best program. When Dr. Thompson played the 1kHz tone, the microchip unfailingly reacted by decreasing its power output to zero volts. When he played the 10kHz tone, the output jumped up to five volts. He pushed the chip even farther by requiring it to react to vocal “stop” and “go” commands, a task it met with a few hundred more generations of evolution. As predicted, the principle of natural selection could successfully produce specialized circuits using a fraction of the resources a human would have required. And no one had the foggiest notion how it worked.
Dr. Thompson peered inside his perfect offspring to gain insight into its methods, but what he found inside was baffling. The plucky chip was utilizing only thirty-seven of its one hundred logic gates, and most of them were arranged in a curious collection of feedback loops. Five individual logic cells were functionally disconnected from the rest— with no pathways that would allow them to influence the output— yet when the researcher disabled any one of them the chip lost its ability to discriminate the tones. Furthermore, the final program did not work reliably when it was loaded onto other FPGAs of the same type.
It seems that evolution had not merely selected the best code for the task, it had also advocated those programs which took advantage of the electromagnetic quirks of that specific microchip environment. The five separate logic cells were clearly crucial to the chip’s operation, but they were interacting with the main circuitry through some unorthodox method— most likely via the subtle magnetic fields that are created when electrons flow through circuitry, an effect known as magnetic flux. There was also evidence that the circuit was not relying solely on the transistors’ absolute ON and OFF positions like a typical chip; it was capitalizing upon analogue shades of gray along with the digital black and white.[4]
Evolutionary approaches are very simple and require no understanding or insight into the problem you’re solving, but they usually requires ridiculous amounts of computation or training merely to keep pace with the top-down “modular” approach. The fitness function may lead to a solution much too complicated for you to understand or much too fragile to operate anywhere but where it was generated. But the bottom-up approach may be your only choice for certain problems.
The moral of the story: the ability to do complex calculation can be built up from a blank slate, in principle and practice. When we follow the bottom-up approach we tend to get results that more closely mirror biology than when we work from the top-down and modularize, though this is less insightful than it first appears. Nearly all bottom-up approaches take direct inspiration from biology, whereas top-down approaches owe more to Plato then Aristotle.
Biology prefers the blank slate.
[Part 3]
[1] Tooby, John, and Leda Cosmides. “Conceptual Foundations of Evolutionary Psychology.” The Handbook of Evolutionary Psychology (2005): 5-67.
[2] Kheradpisheh, Saeed Reza, et al. “Deep Networks Resemble Human Feed-forward Vision in Invariant Object Recognition.” arXiv preprint arXiv:1508.03929 (2015).
[3] Mnih, Volodymyr, et al. “Human-level control through deep reinforcement learning.” Nature 518.7540 (2015): 529-533.
[4] Bellows, Alan. “On the Origin of Circuits • Damn Interesting.” Accessed May 4, 2016.