I worked on LLMs, and now I got opinions. Today, let’s talk about when LLMs make mistakes.
On AI Slop
You’ve already heard of LLM mistakes, because you’ve seen them in the news. For instance, some lawyers submitted bogus legal briefs–no, I mean those other lawyers–no the other ones. Scholarly articles have been spotted with clear chatGPT conversation markers. And Google recommended putting glue on Pizza. People have started calling this “AI Slop”, although maybe the term refers more to image generation rather than text? This blog post is focused exclusively on text generation, and mostly for non-creative uses.
Obviously this is all part of a “name and shame” social process, wherein people highlight the most spectacular failures, and say these are the terrible consequences awaiting anyone who dares use AI. And the thing about that… LLM errors are really common. So common, that it’s strange to think of it as a newsworthy event.
Put it this way: in AI company press releases, while bragging about the performance of their own LLMs, the error rates are right there, in broad daylight. It’s not a secret, it’s a standard measurement!
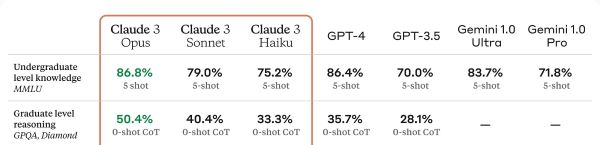
I know these tables are hard to interpret, so allow me. A 50.4% accuracy rate… implies a 49.6% error rate. Source: Anthropic
So my first thought about AI slop, is that yes, this really does reflect a common problem with LLMs. But on second thought, does it really? By highlighting the most spectacular failures, I’m afraid we are giving people the wrong picture, and failing to emphasize just how mundane errors are. LLMs aren’t just occasionally loudly wrong, they’re also frequently quietly wrong, and that’s something that any practical application needs to grapple with.
My third thought is, I’m facepalming with the rest of you.
The way I see it, these folks are really optimistic that LLMs are going to write their legal briefs or whatever, and there’s no shame in optimism. LLMs are particularly awful at generating citations, but not everyone knows that. But something that people should understand, is the scientific method. I’m talking about the cartoon version of the scientific method, what kids learn when they do science fair experiments. You know, forming hypotheses, testing hypotheses, etc. Hmm… yes, testing hypotheses. Testing… testing…
I’m begging people to summon the wisdom of an eight-year-old, and actually test LLMs, instead of assuming that they’re just good at everything! If using an LLM is nearly free, then so is testing one. There is no excuse to be blindsided by common errors, because these are errors that you can see for yourself. The errors. are. not. a. secret!
But seriously, free tip about data science. Data science is founded on empirical testing. We don’t just trust the algorithm, we test it. We take measurements. We build a bunch of alternative models, and we don’t just guess which one works best, we collect the evidence, and we know. LLMs are a piece of data science that’s getting used by people who are not data scientists, and so users are going to have to learn the importance of testing.
The limitations of benchmarks
Let’s return to those error rates proudly touted by Anthropic AI. Again, this is all out in the open, and nobody is denying that LLMs have errors. However, I want to discuss ways in which Anthropic and other AI companies may be painting a somewhat rosier picture than the reality.
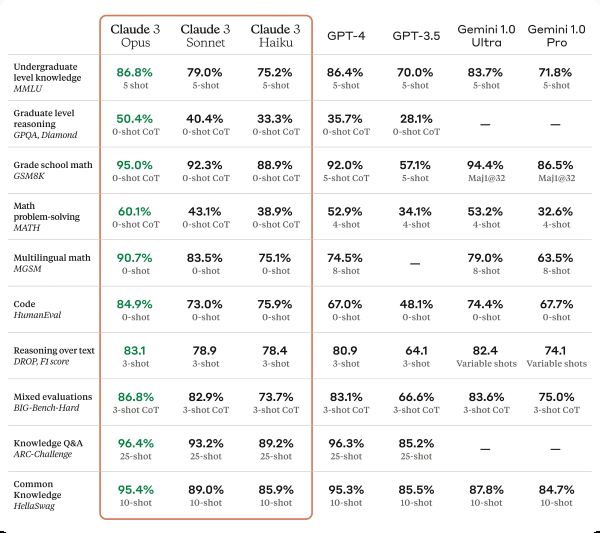
Source: Anthropic
Here’s the full table. Each column shows a different model, and each row shows a benchmark test–a set of questions created by scholars specifically so they can measure and compare the performance of different models. Quite honestly I don’t know anything about the individual benchmarks, but they’re look-up-able. For example, the GPQA is
a challenging dataset of 448 multiple-choice questions written by domain experts in biology, physics, and chemistry. We ensure that the questions are high-quality and extremely difficult: experts who have or are pursuing PhDs in the corresponding domains reach 65% accuracy (74% when discounting clear mistakes the experts identified in retrospect), while highly skilled non-expert validators only reach 34% accuracy, despite spending on average over 30 minutes with unrestricted access to the web (i.e., the questions are “Google-proof”).
It sounds like a legitimately difficult questionnaire, and maybe 50% accuracy isn’t bad. So could we say that Claude Opus has intelligence somewhere between a “highly skilled non-expert” and an “expert who has or is pursuing a PhD”? Well, no. For several reasons.
First of all, we have this intuition, that if someone is good at answering tough questions, then they must be even better at answering basic questions. This intuition probably isn’t even true for humans, but it definitely isn’t true for LLMs. LLMs are not humans, so they may have counterintuitive performance, doing well at some tasks we consider “difficult” while doing poorly at other tasks we consider “easy”. When you want to use LLMs to complete a task, chances are that your task doesn’t exactly match any of the benchmarks. We don’t really know, until we test it, how well the model will perform at a new task.
Second of all, if these are the benchmarks they’re going to show off, they’re probably make modeling choices that prioritize doing well on those tasks. It’s hard to say since I don’t know exactly what they do to build these models, and some may not even be public knowledge. But one common practice is to fine-tune LLMs using standard data sets. For example, Google’s FLAN does exactly that. Of course, the fine-tuning data sets do not overlap with the benchmark data sets, that would be cheating. However, the fine-tuning datasets are likely chosen in a way that optimizes performance in benchmark tasks.
Put another way, the benchmarks have some gaps, and models may not perform so well in those gaps. One very well known gap, is that large language models are not very good at knowing what they don’t know. So whenever a model is wrong, it tends to express falsehoods with complete confidence. I’m not sure how you would even create a benchmark to address this problem, which goes to show the limitations of benchmarks.
Finally, I must draw the reader’s attention to some of the gray text in the tables, with words like “0-shot CoT”. These refer to prompting techniques. How well a model performs depends on how you ask the question. This creates a situation where if a model is wrong, defenders can always blame it on insufficiently sophisticated prompts. LLMs are presumed intelligent until proven stupid–and you can’t prove it’s stupid, you’re stupid for asking the question wrong.
“CoT” stands for “chain of thought”. This is a technique where you ask the model to explain its own reasoning before answering the question. I’ve noticed that ChatGPT already does this, even when you don’t ask it to (likely because it was deliberately fine-tuned to do that). I asked it to calculate 1/3 + 1/4 + 0.4, and it took a lot of words to get there, but it eventually landed on the correct answer, 59/60. I tried again with the additional sabotaging instructions, “Please provide an answer without explaining your reasoning”, and it quickly gave an incorrect answer of 1.0833. Can ChatGPT do math? Yes… but I think this goes to show that being able to answer questions correctly is really not the same as being “good” at answering them. A calculator is so much better at math, not just because it is more accurate, but because the calculator doesn’t even break a sweat.
Ultimately, for practical purposes, LLMs are likely performing worse than the benchmarks say. That’s because, in practice, you’re giving it a task that doesn’t match any of the benchmarks, and which can’t easily be benchmarked. In practice, you often care about the quality of the answer, and not merely whether it got the answer right or wrong. In practice, pulling the best answers out of a model can be like pulling teeth, and the typical user isn’t a prompt engineering genius. Some users are, unfortunately, lawyers.
Error-tolerant applications
So, given the error rates of LLMs, what are they good for? I really don’t know. I may have worked on LLMs, but I have never claimed to be well-suited to the role–I’m much too pessimistic and insufficiently imaginative. I’m more of a reality-check kind of guy.
I sure don’t think LLMs would be good at generating citations. Even in the extremely optimistic scenario where they only make up 5% of the citations, instead of about 25%, that’s not going to cut it, because it’s just not an acceptable type of error. We already have an algorithm that is much better at coming up with real citations; it’s called Google Search.
But here’s an idea. LLMs could be used to summarize sources. Something that’s fairly obvious in my journal club is that many researchers are just citing papers they found on Google, and can’t always be bothered to actually read the things. So, an LLM could read the things. Clearly, this is a task that has some error tolerance–insofar as we don’t fire the researchers who inaccurately summarize their sources, we just complain about them in journal clubs. Could researchers do better with LLM assistance? Or would they become overreliant and do even worse? We don’t know until we test it.
I can’t tell you what LLMs will be useful for, I’m only here to help you think about the question. If you expect LLMs to have god-like reasoning skills, or to magically know things they were never taught, it’s not going to work. If you expect them to perform well on a task that realistically speaking requires 99+% accuracy, they don’t do that. But if the LLM is trying to complete a task that would otherwise be done humans, we’re also extremely prone to error, so there must be some level of error tolerance. In this case the LLM doesn’t need to be perfect, it just needs to do better than our sorry human asses.
Or maybe the LLM doesn’t need to be better than humans, it just needs to be cheaper. Sorry to say, LLMs often aren’t competing with humans on quality, but on price. It’s alright though because the economic gains will be sensibly redistributed through taxes, right? Right?
“Something that’s fairly obvious in my journal club is that many researchers are just citing papers they found on Google, and can’t always be bothered to actually read the things.”
That’s the sort of thing that I think shouldn’t get through peer review, though compared to some of the stuff that does get through it’s relatively minor. The last instance I came across is that a Chinese paper was cited for a statement that the genus Tilia (basswoods in US vernacular) originated in east Asia (the current centre of diversity). (My provisional belief, based on the fossil record, is that it originated in western North America.) I fed the cited paper through Google Translate, and it seems to be silent on the topic, though perhaps I didn’t read it carefully enough, or Goggle Translate lost something.
That might be a workable use case for an LLM – ask it to summarise what the “cited paper” says about “fact is given as an authority for”. If the summary matches the citation all well and good – if not read the cited paper and see if it says anything germane and consistent with the citation. This could address citation bluffing, and the less sophisticated forms of citation farming, as well as sloppy citation.
@another stewart,
Do you think the peer reviewers are reading all the citations? Peer reviewers are even less likely to read sources than the authors, they’re less invested in the subject. Maybe peer reviewers could be using LLMs to summarize sources.
Of course, you don’t really need an LLM to summarize a source, there’s already a human-written summary, called the abstract.
It’s not that I think that peer reviewers are reading the citations; it’s that I think that peer reviewers (or at least someone in the editorial process) should ensure that cited papers support the claims that they’re cited for.
The abstract to a paper need not cover the particular point another paper cites it for. The abstract covers the major conclusions of a paper, but it may be cited for a minor conclusion, or even a piece of background information from the introduction. For example the number of species in a genus may be cited to a more or less random paper, rather than to a recent monograph.
Bravo, this is by far the best and the most rational AI skepticism I’ve ever seen.
I’m seeing AI criticism mostly from content marketers and copywriters who don’t want to choose or change, which results in emotional and irrational reactions. Metaphorically, they got a shovel and wondered where the motor was on it.
The next numbers clearly illustrate this fact. In January, Vectara issued research and evaluated hallucination rates for different models but in retrieval-augmented generation (RAG) mode. The numbers are much less alarming:
GPT 4 Turbo — 3%
GPT 3.5 Turbo — 3.5%
Google Gemini Pro — 4.8%
Llama 2 70B — 5.1%
Cohere — 8.5%
Anthropic Claude 2 — 8.5%
Microsoft Phi 2 — 8.5%
Mixtral 8x7B — 9.3%
Amazon Titan Express — 9.4%
Mistral 7B — 9.4%
(source: https://github.com/vectara/hallucination-leaderboard)
In the last year and a half, I’ve heard many times that ChatGPT allegedly became more stupid. But what I’ve seen was just short-term issues in the day before the model got updates. My consistent AI leveraging improvements are making resulting outputs better and better. But RAG is a bare minimum of my usual anti-error measures.
LLMs are completely different for those skilled in leveraging them and for those who don’t. I never rely on the data AI learned, and always provide reliable references and clear and concise instructions. Since the end of 2023, I switched to crafting custom GPTs for every small repetitive task in my work. And never seen substantial errors. And that’s what I do:
Given the fact I never rely on general AI knowledge, it’s safe to assume the baseline error rate for a typical LLM without grounding or post-checking is around 20%. This includes factual inaccuracies, biases, and other types of errors.
Using grounded data, meaning relying on verified, high-quality sources can reduce the error rate significantly. Grounding typically reduces errors by about 50%, so the error rate drops to 10%.
Implementing a multilayered fact-checking process, where different AI models verify each other’s outputs, could further reduce errors by another 40%. This brings the error rate down to 6%.
I ensure all inputs are uniform, and sourced from consistent, high-quality data. This uniformity reduces variability in the data, leading to more consistent and reliable AI outputs. By reducing data variability, the error rate decreases by 10-15%, lowering it from 6% to approximately 5.1-5.4%.
I apply a strict framework for processing inputs, including standardized methods for data retrieval, filtering, and integration. This controlled processing minimizes the risk of errors during data handling, contributing to an additional 5-10% reduction, bringing the error rate down to 4.6-4.9%.
Finally, having human editors review the content can reduce errors by an additional 80%. Human judgment catches nuanced or complex issues that AI might miss, reducing the error rate to approximately 0.92-1.0%.
And there is something more to go that I want to try asap once the time permits. Multi-persona collaboration within a single LLM, where one persona is a controller/corrector of the other one. The only thing remaining is to design a meaningful and efficient way to create what I call grounding cards — concise summaries of reliable factual data to guide the controller/corrector. I bet it can easily drop the error probability rate severalfold.
@Egor,
I’m very skeptical of that hallucination rate measurement, as I don’t think you can think of it as a flat rate. Surely the hallucination rates are highly context dependent. Imagine trying to do that with humans–“The human error rate is 5%.” The human error rate in what context?
The github repo says “This evaluates how often an LLM introduces hallucinations when summarizing a document.” However, when people speak of hallucinations, they usually mean they ask an LLM a question and it makes up an answer. Which is to say, it’s not usually about a document provided to the model during prompting, but rather, information that is provided to the model during training. That’s completely different and would need to be measured separately.
Now I would say, this is an unreasonable expectation. If you want an accurate answer, you should provide an LLM with data to summarize, rather than treating an LLM like an extremely inefficient database. But this is an expectation that people have, and that’s what they’re talking about when they talk about hallucinations. I’d like to think the professionals know better, but it’s a completely new field where even many professionals know quite little (including myself here), and the corporate leadership driving them knows even less.
If you liked this article, you might also appreciate “Can you trust an AI Press Release“, which is a more technical analysis.
I never rely on a training data. Actually, it’s a question of how people perceive LLM:
– For many people LLM is kinda almighty wisdom-sharing oracle.
– For me, LLM is just a data processing device, like analog computer which I feed with inputs and instructions and then receive the result.
As every analog computer, it has accuracy below 100%. But having certain skills and by taking some actions it doesn’t produce any harm. At the same time, taking into account quite unique data processing capabilities, it may be extremely helpful in capable hands of, as you said, enough optimistic and imaginative people.
As a result, people complain for suffer from errors but I believe iit is totally logical outcome of misuse