Getting infected with ransomware is management’s decision. They just don’t realize that they made that decision; it’s one of those things like driving under the influence of LSD: you may have plenty of time to regret it if it turned out to be a bad idea.
Back in the old days, lots of companies that used computers had IT departments and system administrators. Those were expensive, and they appeared to be “wasted money” because, well-managed computers didn’t have many problems; they just worked and stayed up and things happened the way they were supposed to. Sometimes security people (a sub-genre of system administrators) would say, “I think that’s a bad idea, and here’s why…” in a meeting. Meanwhile, some other companies had big parts of the system that were semi-automated. By semi-automated, I mean that there was a human who knew how the system worked, and controlled it at a meta-level. That human was incentivized, like the system administrators, to keep things running smoothly. But those systems had the same problem as the computers: if they were well-run, there were no problems, and things just hummed along. Of course there were badly-run systems, and badly managed systems, and they didn’t run so smoothly, but it was pretty easy to identify where the screw-up happened, and fix it. For example, one place where I worked had a system that failed regularly because I was not permitted to maintain it. Eventually management complained, and the producer of the system sent out a trouble-shooter who utterly demolished my management; it was an unforgettable experience. I believe I wrote a posting about it, but I can’t seem to find it (the search engine for wordpress is not great) if any of you remember the story I told of coffee-swilling Sylvan, that’s the incident.
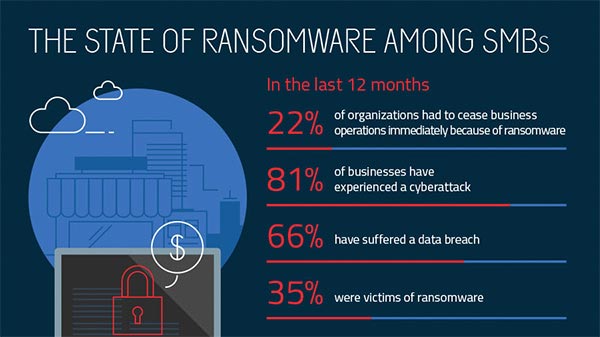
source: malwarebytes
The thing is that top-notch managers, let alone trouble-shooters were expensive. So management listened to vendors that told them “you can automate this, so that one guy with a cup of coffee at his desk, can run the entire system, without leaving their desk!” And the computer makers told the managers, “it’s so easy to run you can just leave it alone, and mumble mumble mumble (never install patches or perform any maintenance on it at all)” Those things were lies, but they were convenient lies for separating the stupid customers from the smart ones, and the money from the dumb ones. And, in the 90s, nobody cared: managers were getting promoted so fast and making lots of money, they knew they’d be comfortably retired before the wheels came off the pram and the whole mess went hurtling down the hill headed for a rock-crusher. I remember, literally, talking to CTOs in the 90s who said, “I’ll be on to something else in a few years anyhow, this stuff just has to hold together until then.” I made a lot of money in the late 90s and early 00s doing incident response for security breaches, and often my executive summary on my report to the board started with – in effect – “that thing I told you not to do, you did, and now it has failed like I warned you it would.” Back in those days, some of my recommendations were howlers, like: “inventory all internet-facing software that is publicly reachable, i.e.: you have an inbound firewall rule for, and establish a patch maintenance schedule so that you don’t wind up with a known vulnerability exposed to the entire internet.” And the reply was sometimes, “what?! That’s ridiculous! We don’t have the staff for that.” And I’d coolly reply (no, really, there was a time when I did icy professionalism very well; I was world class) “Then you don’t have the money to do IT and you should scale back your expectations.” Some of those organizations went on to have massive very public breaches; one of them paid off my mortgage completely in 2007, right before the big market implosion – my customer’s fail was sometimes my good fortune.
All over the place in the early 00s, companies were automating stuff. Someone would say, “you don’t need 6 people in 3 control rooms – you can have one guy in one control room in… let’s say, Dallas, TX, controlling the entire fuel pipeline via a single panel!” I was in some of the meetings that happened after that sales call, and I’d usually ask questions like, “has anyone done a good cost/benefit analysis?” because it never seemed much cheaper, to me, to build a global network in order to remove 2 out of 3 control rooms. It always seemed to me that having 6 people in 3 control rooms wasn’t the driving expense – the company was spending way more on executive management and bean-counters than on Homer In The Control Room. And Homer In The Control Room was … resilient? I’m not sure that’s the right word. Homer In The Control Room was sometimes the problem, sometimes the solution – unpredictable, mercurial, and human. I knew some system administrators who accomplished great things on 9/11 – they worked for CNN, and CNN’s server farm simply could not handle the load they were getting; it was approximately 100,000 times the normal load. So the systems administrators got hold of a panel truck from a guy who knew a guy who had one and ran down to CompUSA and bought everything with a processor in it (including laptops) and loaded OpenBSD on them and started slapping them in racks, and eventually stacking them on the floor. And they made it work. The one guy sitting in a control room 2,000 miles away is helpless. They’re like Sauron who made the one ring and then took a nap while Mordor caught fire.
Meanwhile, the vendors kept saying “buy our framework and you can let Homer In The Control Room go!” and then came The Cloud. You no longer need anything to do computing. Just give us money and the computing will magically happen! It’s so easy, even an idiot can do it – which is true, if what you need is the work an idiot can do – and many organizations fell all over themselves to de-skill their work-force in the name of saving not much money on IT. See, not having system administrators saves some money, but the cloud service costs a bit more. It turned out that the whole value proposition of the cloud was not having to pay medical insurance and other benefits for a few system administrators. And, besides, the systems run themselves, right?
And that’s why we have stories like every police department, local government, small/medium business, energy company, etc., that got rid of their painfully-acquired legacy knowledge and fired those people and now the good ones are Google millionaires anyway so “kiss my ass” is what they say if anyone ever calls them for help. The only people who’ll answer the calls of the desperate and stupid are insanely expensive trouble-shooters who can charge, in a week, what the organization “saved” by outsourcing the system in the first place. I’ve seen companies spend millions of dollars to recover the damage caused by saving thousands of dollars.
So, these clowns who have been hacked with malware/ransomware, and are struggling to regain control of their gas pipeline: they are just discovering an interesting fact; that their cost/benefit analysis was wrong. That’s it. It’s like when Napoleon Bonaparte was outside of Moscow in the looming Russian winter and discovered that his cost/benefit analysis was wrong. C’est la vie. I don’t know who’s doing the incident response for the energy company, but they’re making $500/hr, probably more. That is not a typo. And, since it sounds like the energy company is pretty thoroughly fucked, it’s going to take weeks or months to get things back to normal. The really sick part of the joke comes when the incident response is done and the consultants present management a list, “now, here are all of our recommendations.” Then management screams “WHAT THE FUCK!?” because the recommendations add up to several million dollars. I did one incident response you all heard about in the news, and the cost for tech that they should have already had in place (firewalls, log aggregation, a SOC, malware analysis, application whitelisting and configuration management) was about $5.6 million. If they had spent less than that, years before, none of what happened would have happened. I used to liken the situation to going into a gun-fight without a helmet and bullet-resistant vest. It doesn’t mean you won’t get hurt, but it dramatically reduces the butcher’s bill if you survive. Let me put that another way: none of the customers that ever called me into an incident response had good firewall rules, a squared-away log aggregator and a well-run SOC with malware detection and blocking – the reason they called was because they didn’t have that stuff. I never walked into a disaster drill and found that my client was adequately prepared. Because, otherwise, they weren’t my client. I do know a few of those guys – the super squared-away folks who ran a tight ship. We’d go out for sushi and sake while everyone else was screaming and pulling their hair out.
For example, the energy company with the ransomware could have built two networks. One, let’s say, is the “office automation network” and that’s where email, web surfing, porn, blog reading, etc., happens. And the other is the “production network” and they’re separate. All that exists on the production network is the operations center, management software, and programmable logic controllers and sensors in the field. But the client would say, “we don’t want to spend the $ to have duplicate copper, let’s just run it all on the same WAN and maybe segregate it a bit with some VLANs and stuff.” Sure. That’s cheaper. In the short term. I only saw this go down correctly at one client, and it was Exxon-Mobil, back in the day when I’d still work for petro-companies. I was in a meeting and suddenly there was a serious discussion about whether or not to spend about $150,000 for more copper runs and a duplicate switching fabric for a certain facility and I said, “I’ve served as an expert witness on court cases and let me tell you, if someone blows up a chunk of Dallas/Ft Worth because they exploit your pump control systems, I feel sorry for the expert who has to explain VLANs and firewalls to a jury. The guy who’d win is the guy who shows a picture and says, “see the red box on the wall, and the red wires? That’s the red network; it’s not connected to anything else and that’s what we use to control the pumps.”” And the CIO, who was in the room, said, “Ta. There’s the answer.” They got into it and the security team took their switches to a motorcycle paint artist and had them painted hot glossy dangerous-looking red. I wonder if those boxes are still there, or if they’ve switched to The Cloud.
It’s more expensive to build dual-rail systems, but in return for that expense you get what security people call assurance or assurance by design – i.e.: it works the way it works because it’s the only way it can work, so we don’t have to worry about it suddenly working differently. Meta-programmable wires (software-defined networking or VLANs or VM racks) can be changed to work differently when you least expect it; but you can’t hack copper wire without getting a person into a data center.
That’s the end-game for all of this and that’s why I’m a lot less sanguine about taking security seriously. If the bad guys want to up their game, they can begin physically penetrating systems by breaking into buildings or getting jobs on cleaning crews. The group of hackers who are currently causing multimillion-dollar distress for the petro line company, are like the guy in Hemingway’s Old Man And The Sea: they caught a fish that’s so big they don’t know what to do with it. In fact, some fish like that are more dangerous than they are worth. I was involved in a case where a hacker was threatening/extorting online gambling sites, and had tracked him down to a specific favorite workstation at a particular cybercafe in Amsterdam. Then, the FBI stopped talking to me about the case and I called and asked whether I had pissed someone off. “No, the case it closed. The Russian mafia found him first and the police found pieces of him in 4 separate dumpsters in a suburb of the city.” Not my idea of incident response but I’m not going to argue with the guys who did that. Anyhow, the bad guys have so much room at the top for doing nasty break-ins, that it’s impossible to adequately secure the systems we’re dealing with. Most of the stuff, with few exceptions, that has been put in place since the 90s is crap; it’s only inviolate because breaking into all that stuff is like a real job and who wants that. The Cloud has put all of that stuff out in the target-zone, and COVID hammered the “remote work” button so hard, I doubt there’s anyone left who manages a sensitive system by, you know, walking up to the console and physically logging in.
None of this is new and it’s only going to get vastly worse. Or, as I’ve put it elsewhere: it’s already vastly worse but it hasn’t yet revealed how bad it is. Back around 2011 I was promoting a mental framework I was calling “the anatomy of security disasters” which hypothesized (correctly, I still think) that we’re usually dealing with the mistakes and flaws from 10 years ago. The mistakes and flaws in the stuff we’re doing now won’t manifest for a while, because the bad guys are still having too much fun exploiting the 10 year-old stuff. A decade later I was predicting the the great move to The Cloud would be followed, a decade later, with the great Re-In-Housing, but I’m no longer sure about that; I think the loss of organizational knowledge may make Re-In-Housing impossible. Either way, there will be consultants making a hell of a lot of money on it.
Normally, I’d end this with a picture from the odious Scott Adams, but instead I’ll describe it: at Dilbert’s organization, Dogbert has been hired as a consultant to help improve things. The consultant’s conclusion: you hire too many consultants. Badum-Tschh.

If you’re doing anything wrong with a computer – sending racist emails, overthrowing governments, plotting murders, etc – anything: it’s already too late for you. But if you’re thinking about doing crimes or nasties, figure out how to go as old-school as possible. Meanwhile, all the police departments who’ve outsourced their email to Microsoft Office 365: they’re all going to get searched for racist jokes, etc., and what do you think people will find? All the politicians? Ha, we already know. The point is: everyone’s vulnerable at every level. Welcome to the new reality, it’s what your managers bought you when they listened to the salesguy from the vendor who said “it just works!”
This is a piece I wrote back in 2004 on my personal blog [ranum] back when I wrote about security whenever I was stuck overnight in an airport, which was often. It’s about the “Farewell Dossier” – an alleged collection of CIA documents about operations in the cold war, including one in which the CIA arranged to allow the Soviets to steal some oil pipeline control software that was backdoor’d and the CIA, allegedly manipulated line pressure and caused a gigantic explosion:
The technology topping the Soviets’ wish list was for computer control systems to automate the operation of the new trans-Siberian gas pipeline. When we turned down their overt purchase order, the K.G.B. sent a covert agent into a Canadian company to steal the software; tipped off by farewell, we added what geeks call a “Trojan Horse” to the pirated product.
“The pipeline software that was to run the pumps, turbines and valves was programmed to go haywire,” writes Reed, “to reset pump speeds and valve settings to produce pressures far beyond those acceptable to the pipeline joints and welds. The result was the most monumental non-nuclear explosion and fire ever seen from space.”
I don’t believe anything, or everything the CIA says about anything, but when you see US government officials wringing their hands about ransomware on the pipeline, that’s what they’re thinking about. And, you know what? They should have been thinking about that a while ago! It’s a bit late, now. On the flip side, if the Russians wanted to cause trouble, they’re hardcore – they’re not simpatico – they’re the kind of people who’d send people over “tourists” with high explosive and incendiaries and they’d just fuck some shit up the traditional way. A lot of this stuff is messaging. Blowing someone’s pipeline up is less the point than showing them that you can blow up their pipeline.
And do not try to extort money from the Russian mafia. Of course the guy didn’t know the website he was extorting was owned by Serious People. Do your research. If I were the hackers behind the oil pipeline hack, I’d be standing down my operations and trying to find a useful idiot who was interested in taking them over and being the new pipeline king, because they are going to experience some unexpected disassembly events. It’s all messaging, remember.
Google search string ‘coffee Sylvan ranum’ yields https://www.securityweek.com/true-white-knuckled-stories-metrics-action-sylvan
John Morales@#1:
Thank you! I had forgotten where I published that. It certainly explains why my search
freethoughtblogs.com: ranum stderr sylvan sylvan
came up blank.
Spoiler alert! There’s another book I don’t have to read.
An acquaintance of mine tells an anecdote of his early days working as a cop in Manchester. He was in the station office dealing with a little old Chinese chap who had been burgled. As he tells it, the chap was quite relaxed and ultimately just wanted a crime number to give to his insurance company. He didn’t seem bothered about anyone coming out to investigate or inspect the scene of the crime. Something about the situation felt wrong to the callow PC interviewing him, so he (the PC) went to see his boss. His boss popped by and eyeballed the victim, and instructed my acquaintance to issue the gentleman with a crime number, send him on his way and close the file. He – the old man – was the head of the largest and most powerful triad in Manchester. There was (per the boss) no point bothering to investigate the crime. The perps would already be in a cellar somewhere with no arms.
I was struck by the simultaneous vagueness and specificity of that last comment.
Heh, heh. I have not worked in IT, but I have seen this in my line of work too. Several times over. It always happened when people with MBA degrees from USA universities were in charge, for some reason.
It was a case of manufacturing complicated mechanical thingamajigs from molded plastic parts. Usually, the things went this way:
1) Beancounters negotiate a “competitive” price to win the project with little to no input from experts.
2) Actual experts say that the negotiated price is too low to make the product to specifications. Or sometimes at all.
3) The experts are told to shut up by the management and get it to work.
4) The experts do their best but inevitably they fail because physics can’t be fooled.
5) Huge financial trouble ensues.
6) The experts are tasked with implementing the things they initially said will be needed, but sometimes that is not possible and starting again from scratch is too expensive, so the company is stuck with the loss.
And some specific examples of how things went:
1) In one specific case the mold designer has requested three heating elements and three injection sites for each part because that was the only way to maintain the precision required for the parts to function properly afterward in the assembly. His budget was slashed and he was only allowed to implement one heating and injection point. The parts came out oval instead of round, he said “I told you so” and quit.
2) In that same project these highly paid geniuses negotiated a price that was actually lower than the price of raw materials.
3) I was once summoned to a meeting where I was expected to promise to the customers to finish in two weeks (gross total time) a test that – according to the customers’ own specification – took six weeks net time in the testing device only. Another time a manager simply promised a test with a timetable that was not doable and only could not blame me after it failed because I and my colleague have very loudly and clearly stated upfront that he wants the impossible.
4) In another project, managers promised to deliver cheap chrome-replacement technology that has previously failed several of the required tests.
5) In that regard, the technology has required a dust-free environment and a climatized room to work properly. Beancounters refused to pay for it and tried to run the production in impromptu settings right next to a dusty storage area. Only after racking up the bill for warranty complaints, replacement parts, and delay fines did they finally allow to build a small dust-free room. And someone got a bonus for finding this ingenious solution. Which was recommended upfront.
6) And as a last, one systemic issue. Initially, all projects went through several prototyping phases, first making prototypes, then forms from silicone, then forms from aluminum, and only after the aluminum forms proved to work, they were made from steel for the final products. Beancounters have decided that this takes too long and only “virtual” testing will be done for the forms and then hooray, let’s go directly into steel. The result was that the costs of the aluminum forms were subsequently spent several times over by optimizing things in the steel forms that were not possible to predict. Because – and that is something that American managers really, really cannot grasp – the reality is too complex and no amount of computer programming can replace real tests with real things. Even though this has happened in every single project since that change, for several years, both the companies and the customers refused to go back and insisted on this reduced prototyping scheme.
Oh, the memories of working for USA based company led by imbeciles with huge egos and bank accounts but no actual skill at doing anything useful.
Charly: The only answer is to LEARN MANDARIN
@ 5 Charly
People talk about Russiagate but they never notice that the evil fiendish communist ™ USSR funded the Harvard School of Business in the 1930’s.
If they built the system well they probably do still exist.
Maybe a lot of non-tech people don’t get the difference between IT infrastructure and consumer electronics, and just think that everything will need replacing in a few years anyway?