I keep an eye out for old criticisms of null hypothesis significance testing. There’s just something fascinating about reading this…
In this paper, I wish to examine a dogma of inferential procedure which, for psychologists at least, has attained the status of a religious conviction. The dogma to be scrutinized is the “null-hypothesis significance test” orthodoxy that passing statistical judgment on a scientific hypothesis by means of experimental observation is a decision procedure wherein one rejects or accepts a null hypothesis according to whether or not the value of a sample statistic yielded by an experiment falls within a certain predetermined “rejection region” of its possible values. The thesis to be advanced is that despite the awesome pre-eminence this method has attained in our experimental journals and textbooks of applied statistics, it is based upon a fundamental misunderstanding of the nature of rational inference, and is seldom if ever appropriate to the aims of scientific research. This is not a particularly original view—traditional null-hypothesis procedure has already been superceded in modern statistical theory by a variety of more satisfactory inferential techniques. But the perceptual defenses of psychologists are particularly efficient when dealing with matters of methodology, and so the statistical folkways of a more primitive past continue to dominate the local scene.[1]
… then realising it dates from 1960. So far I’ve spotted five waves of criticism: Jerzy Neyman and Egon Peterson head the first, dating from roughly 1928 to 1945; a number of authors such as the above-quoted Rozeboom formed a second wave between roughly 1960 and 1970; Jacob Cohen kicked off a third wave around 1990, which maybe lasted until his death in 1998; John Ioannidis spearheaded another wave in 2005, though this died out even quicker; and finally the “replication crisis” that kicked off in 2011 and is still ongoing as I type this.
I do like to search for papers outside of those waves, however, just to verify the partition. This one doesn’t qualify, but it’s pretty cool nonetheless.
Berkson, Joseph. “Tests of Significance Considered as Evidence.” Journal of the American Statistical Association 1942;37:325-35. International Journal of Epidemiology, vol. 32, no. 5, 2003, pp. 687.
For instance, they point to a specific example drawn from Ronald Fisher himself. The latter delves into a chart of eye facet frequency in Drosophila melanogaster, at various temperatures, and extracts some means. Conducting an ANOVA test, Fisher states “deviations from linear regression are evidently larger than would be expected, if the regression were really linear, from the variations within the arrays,” then concludes “There can therefore be no question of the statistical significance of the deviations from the straight line.”
Berkson’s response is to graph the dataset.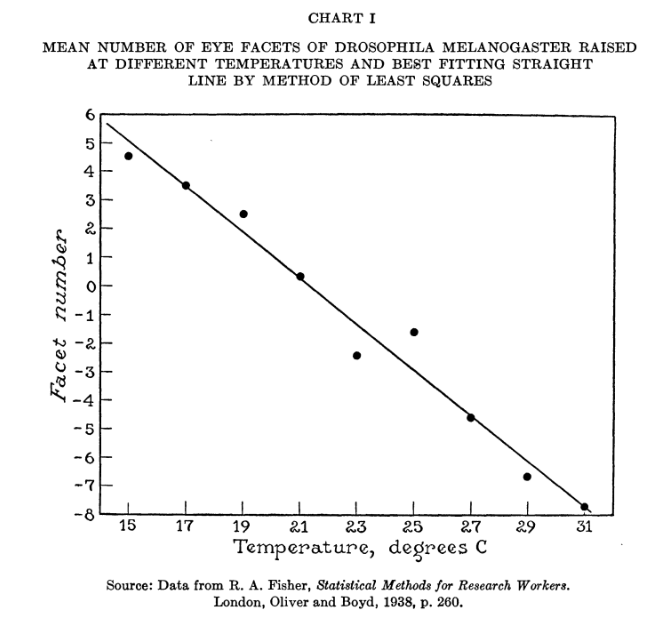
The middle points look like outliers, but it’s pretty obvious we’re dealing with a linear relationship. That Fisher’s tests reject linearity is a blow against using them.
Jacob Cohen made a very strong argument against Fisherian frequentism in 1994, the “permanent illusion,” which he attributes to a paper by Gerd Gigerenzer in 1993.[3][4] I can’t find any evidence Gigerenzer actually named it that, but it doesn’t matter; Berkson scoops both of them by a whopping 51 years, then extends the argument.
Suppose I said, “Albinos are very rare in human populations, only one in fifty thousand. Therefore, if you have taken a random sample of 100 from a population and found in it an albino, the population is not human.” This is a similar argument but if it were given, I believe the rational retort would be, “If the population is not human, what is it?” A question would be asked that demands an affirmative answer. In the hull hypothesis schema we are trying only to nullify something: “The null hypothesis is never proved or established but is possibly disproved in the course of experimentation.” But ordinarily evidence does not take this form. With the corpus delicti in front of you, you do not say, “Here is evidence against the hypothesis that no one is dead.” You say, “Evidently someone has been murdered.”[5]
This hints at Berkson’s way out of the p-value mess: ditch falsification and allow evidence in favour of hypotheses. They point to another example or two to shore up their case, but can’t extend this intuition to a mathematical description of how this would work with p-values. A pity, but it was for the best.
[1] Rozeboom, William W. “The fallacy of the null-hypothesis significance test.” Psychological bulletin 57.5 (1960): 416.
[2] Berkson, Joseph. “Tests of Significance Considered as Evidence.” Journal of the American Statistical Association 1942;37:325-35. International Journal of Epidemiology, vol. 32, no. 5, 2003, pp. 687.
[3] Cohen, Jacob. “The Earth is Round (p < .05).” American Psychologist, vol. 49, no. 12, 1994, pp. 997-1003.
[4] Gigerenzer, Gerd. “The superego, the ego, and the id in statistical reasoning.” A handbook for data analysis in the behavioral sciences: Methodological issues (1993): 311-339.
[5] Berkson (1942), pg. 326.