Code Obfuscation’s really neat stuff. Or, it can be.
Other than the rare programmer such as the one guy I encountered in a certain university’s database research group in 1988, most programmers write somewhat readable code. It has to be readable because the compiler/interpreter’s parser is almost always more strict than a human would be – programming languages have a specific syntax that strikes a balance between the computer’s ability to be sure what the programmer wants to do, and the programmer’s laziness about expressing it. There are fun philosophical debates among programming language proponents as to the degree to which the computer should try to figure things out. For example, in old K&R C you might write:
foo(i, j) int i; char *j;
That’s part of the declaration of a function “foo” that takes an integer and a pointer to a string as its inputs (the inputs are pushed onto the stack by the calling function). In some other programming language, you might just write:
foo(i, j)
and the programming language would use other means to figure out which is an integer or which is a string. The subject of the debate is the degree to which “let the compiler figure it out” breeds sloppiness because the programmer can no longer keep track of what’s what, or whether forcing the programmer to declare variables is “extra, wasted, work.” No matter how you slice it, though, the computer has to have enough information to figure out what it was you wanted it to do, or it won’t run correctly. Where it gets fun is that the computer is a lot better at dealing with deliberately gnarlified code than a human is. So you can take a pretty clear piece of software and run the code through an obfuscation tool – sort of a “compiler from hell” that emits a harder-to-read version of the code. This is generally necessary with scripting languages that are run in an interpreter: to run them you ship the source code to the interpreter which ingests it and runs it. That’s different from compiled programs where you hand the code to a compiler which produces object code or bytecodes that are run in a virtual machine; the compiler can leave out all the flow control and comments and variable names, etc, since it knows where they are.
For example, in a piece of C I might declare a string as:
char prompt[] = "Romani ite domum:";
In the code it’s useful for the human at the keyboard to call that string “prompt” because I don’t know where the compiler is going to store that string in the heap of the object code that comes out the other side. So, let’s say that the compiler decides to store that string at memory address 3735928559 – the compiler points all references to “prompt” at that address and “prompt” is no longer needed as a crutch for the human and can be discarded and not put in the object code. In a scripting language, your variables names are part of the code that gets pushed across the web and into your browser (or whatever) so it has to be preserved. Which means that someone who runs your program, has a copy of your source code.
Enter obfuscation!
If I’ve got to give you a copy of my source code, why not turn “prompt” into “0x000010” or something less readable? Why not turn all my variables into unreadable crud? What if my variables look like: “01oI00”, “0I00Ioo” and so forth? And all my function names can be changed, and my strings can even be removed. Let’s say that I have an output function that prints my prompt and my obfuscator turns
print("Romani ite domum");
into
print(d(0.s,o.b,o.j,o.q,o.p,...));
In other words, my neat clean string is replaced with a function called d(…) which constructs the string from a bunch of other memory objects that the obfuscator exploded it into. And, of course, a proper obfuscator would rename the print(…) function somehow, if the programming language permitted it, or replace the call to print(…) with a wrapper function
oI00I(d(0.s,o.b,o.j,o.q,o.p,...));
Then, somewhere, is a function called oI00I(…) that calls print(…) with its parameters.
I believe that an argument can be made that, if a Turing machine can run a piece of code, a human can figure it out. It just might take forever, and an infinitely long tape. A human might not be able to tell if it halts or not, but, basically, you interpret the code like the CPU would, and build your own map to all the pieces of memory, stick variable names on them, name all the functions, and follow all the control-flow branches. Back in 1983/4/5 I helped clean up code for a decompiled version of Peter Langston’s EMPIRE game: someone took a copy of the compiled PDP-11 object code, ran it through a decompiler which produced very ugly C code indeed, but the C code could be run through a compiler on a different architecture and – it worked! Debugging it was living hell because the decompiler produced all the control flows as cascaded GOTOs. But it worked enough that we could play EMPIRE, once the basic I/O routines were rewritten for the new platform.
A decompiler for a scripting language is a form of “pretty printer” or an interpreter – it ingests the source code, reformats it into something designed to be readable and it (in theory) will run the same way as before. In other words, it’s a compiler that produces source code instead of object code. I find the whole process fascinating because, really, it depends on how much information is available to the pretty printer: if it knew how you usually like to name variables and constants, it could fix them up for you, etc.
In computer security this stuff comes up repeatedly. Back in 2007 I was doing an incident response at one company, and we determined that several hundred web servers had been infected with a piece of malware that someone had installed using a server flaw. The malware was a remote control trojan (or RAT – “Remote Access Trojan”) that allowed the attacker to do – something – using commands contained in HTTP requests. We couldn’t tell what it did because the code, which was PHP, had been run through an obfuscator. It looked like garbage, MUMPS, or APL code. But here’s the thing: for an interpreter to be able to run it, it had to be correct and consistent, so we ran it through a PHP prettifier, which spit out more hard-to-read glarp. What the hacker had done was very clever: some code-paths led to errors, but the code flow was designed so those errors would never happen – to figure out what it did, we had to interpret it enough to suss out the basic flow of the thing and figure out what branches never got taken. It was a great big pain in the neck, so we called upon a friend of mine who absolutely loves that sort of thing, and he dropped what he was doing and de-obfuscated it for us in a day or so. The thing is that the glarp had all the variable names in Romanian. The first thing we figured was that the malware was actually not Romanian because if you’re obfuscating your code, why would you not obfuscate your variable names? [remember: obfuscating variable names is pointless in compiled languages, but matters in interpreted languages] There are obfuscators that allow you to provide your own vocabulary for translation tables.

some of my old code (/dev/random device driver, 1992) run through a beautifier
There used to be a thing called for C code which would prettify and reformat, and could remap variable names and function names, and I know a guy who used it to change all of a co-worker’s code to use names from Star Trek. You can imagine the screaming if you opened your source and found stuff like:
while(phasers_locked_on) photon_torpedoes--;
In the screenshot of the pretty printer code whacking at my old source, you can see it munged the #includes at the top. Apparently double-spacing #include headers is too old-style for the pretty printer. Serious effort gets expended on turning code into unreadable stuff:
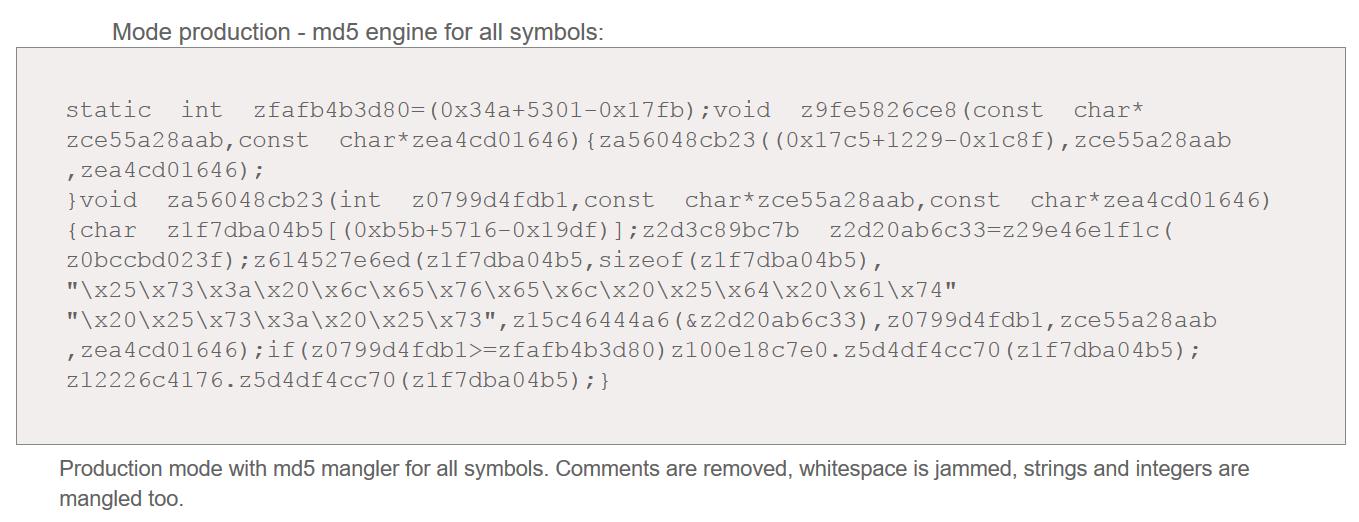
example of Stunnix obfuscator in action [source]
And, if you’re an intelligence agency like NSA or CIA you’re going to want your own, too. The NSA’s obfuscation is particularly good (because they can afford the very best!) [ixia] But, like the “Romanian” hacker we dealt with in 2007, nobody with any understanding of the tools that are available is going to assume that Romanian variable names means the hacker is Romanian. It’s particularly interesting when you see something like Kaspersky’s report on NSA/”Equation Group” malware,[kaspersky] which appears to use the same obfuscation techniques as other pieces of NSA code. The obvious conclusion is that outgoing code is ‘sanitized’ with some kind of tool that automatically does certain obscuring transformations. The intent is not to hide the fact that it’s malware. It’s not to hide what the malware does. It’s to make it harder to figure out what the malware does, and it’s also to make it harder to figure out who wrote the malware. Imagine if Programmer Jane tends to use a particular indentation style and variable naming: if you can identify ‘signatures’ in Programmer Jane’s code, you might be able to search online for other code with the same techniques – it’s basically the same idea as identifying whether Bacon wrote Shakespeare through word frequency ‘signature’ comparison. The government agencies that are developing malware are absolutely aware of those techniques, because they invented them.
This is why the leak of the CIA’s “Marble” obfuscator is damaging [sophos] – the signature of the tool can be determined, even if the output from the tool cannot be reversed. So, if someone writes a piece of malware and stuffs ancient Roman names into their code, or translates their strings to Arabic, and then obfuscates the whole mess with Marble, an analyst can tell that the obfuscation technique is the CIA’s even if the code doesn’t contain anything identifiable.
The NSA’s “Equation Group” (they call it Tailored Access Operations – TAO, and probably have 300 other classified names for it) has been lying a bit low since the Shadow Brokers blew a great big hole in their tool chain; now a lot of antivirus makers (oddly, the American antivirus makers are pretty quiet for some reason!) like Sophos and Kaspersky are confidently attributing attacks to NSA. And, to most of the security professionals I know, the attributions are good: the tools were first detected deployed on the internet, then the tools’ methods and finally the tools themselves were identified as coming from NSA through a variety of NSA leaks. The same thing appears to now be happening to CIA. Maybe CIA will lie a bit low for a while, too. My bet is they are building new tool chains and will be back to “hack the world” in a couple years.
This is relevant because we don’t want the US going to war with some poor bunch of saps due to a falsified attribution. That’d be like the Gulf of Tonkin Incident for cyberspace: a manufactured incident that gets a lot of people killed. Not on my watch, please.

How to target a signature (make your hack tool look like it was written by someone else)[wikileaks]

“figure out what it was you wanted it to do, or it won’t run correctly…” – that’s also a part of a debate on software reliability. Many scripting languages allow you to write code, invoke it (so that it’s running and doing stuff) and then it can get part way through doing stuff and encounter a programming error and crash, leaving things partly done. That’s a big difference between compiled code and interpreted code – some interpreters do the error-checking at run-time, whereas generally compilers do most of the error-checking that they can do, at compile time. As a person who likes reliable software, I’m a proponent of doing as much error-checking as possible, as early as possible – which means that I think it’s absurd to launch a program on the fly and accept that it may encounter a fatal syntax error halfway into updating a customer database or something like that. I loathe most web scripting languages because I feel they promote unreliable software, yet are used for computing that ought to be reliable.
3735928559 – is one of my favorite addresses, in hexadecimal it’s “0xDEADBEEF”;
The first “pretty printer” I used on code was “RENUM” on old BASIC code in the late 1970s. When I started coding in C professionally, I used to use a thing called “indent” and eventually adopted its preferred structuring rules in my own code, to the point where I could run “indent” on my code and it wouldn’t change anything.
De-obfuscating friend: The guy in question is the CSO of a FORTUNE-500 company. It’s kind of daunting to call someone like that up and say, “hey, what are you doing tonight and would you like to de-obfuscate some Romanian malware?” Different strokes for different folks. He had a blast, apparently.
“because they invented them” – William Friedman, the cryptographer who invented statistical analysis applied to code-breaking, got his start as a cryptographer trying to determine if Bacon had written Shakespeare. Friedman went on to establish the NSA’s mathematical code-breaking efforts.
I was (unfortunately!) a user of Bjarne Stroustrup’s first C++ compiler, ‘cfront’ which ingested C++ and output C source code as its object code. You then ran the C code through a C compiler and – later – much later – had a gigantic, bloated executable. But: you had an executable! Yes, at the time, there were many jokes that C++ was the ultimate code obfuscator, because what came out bore very little discernable resemblance to what went in, other than being much, much larger.
“There used to be a thing called for C code which would prettify and reformat” — I had no interest in having anything to do with such an abomination. I think it was a script that ran code through the macro preprocessor or a great big sed(1) script, and then repaired the formatting afterward by running it through indent. Whoever wrote it probably was trying to repair some code from some programmer who was drawn and quartered by whoever came afterward to maintain their code.
“one guy I encountered in a certain university’s database research group in 1988” — for starters, all variable names were in ancient Greek. And he changed his own style repeatedly in the same module. Imagine a guy who keeps flipping back and forth between K&R C, ANSI C, and C++-looking weirdness done with the macro processor. In the same file.
Thanks for the invitation to imagine (lol), but I’d rather not. I like maintaining my own sanity. My colleagues are enough (lol).
EnlightenmentLiberal@#1:
If you want to hurt yourself, are you familiar with Duff’s Device? [src] Start reading from the bottom, unless you don’t mind spoilers.
I’ve decompiled parts of Win32 programs in x86 assembly language back to passable c++ code.
Good times!
It’s a bit like a shitty detective story….what’s that memory location doing, is it part of the runtime, or a user defined type?
Brian English@#3:
I’ve decompiled parts of Win32 programs in x86 assembly language back to passable c++ code.
I’m sorry. Those are hours of your life you’ll never get back.
Nice article, it should make sense even to a neophyte programmer.
—
Brings back memories, too. Back in the days of BBSs (early-mid 80s) a friend of mine started a home BBS but couldn’t afford to pay for games. I was a hobbyist programmer back then — took pride that every computer I bought more than paid for itself — and as a friendly gesture ‘cracked’ a couple for him.
It was easy even without a decompiler — I just ran DEBUG.EXE and changed the opcode at the instruction where the program without the key would normally exit. Didn’t even need to know what was being compared with what.
(Trivial case, I know, one where obfuscation wouldn’t really matter)
What’s that, Marcus? You mean Marble isn’t a program intended to slip random paragraphs of Russian gibberish into attack code in a way that would be a blatantly obvious red herring? It has fuck all to do with what you were trying to say it was only a few days ago? It isn’t actually proof of anything you’ve been saying?
It turns out that it’s exactly what I said it was? And nothing like what you claimed it was?
Well who’d have thought.
Rather then write any posts about how you fucked up majorly, you’re just going to inform people about what code obfuscation means. Good job. I mean, I already explained it to you when you were still trying to claim that marble was a program intended to insert foreign languages into attack code, because you fucked up so badly that you forgot that the language analysis part of the fingerprinting was done on the emails and the released documents, not not on the attack code. But good job, you finally managed to write a long, meandering post about exactly what I already explained to you.
It turns out that the NSA leaks matter because they’ve proven you to be a shameless hack who will try to turn anything into evidence of an NSA or CIA false flag operation. You’re just a liberal Alex Jones. You don’t care if the leaks have fuck all to do with what you’ve been babbling about. And you won’t even acknowledge if you’ve just pivoted 180 degrees away from what you were just claiming mere days ago.
[meta]
Nomad:
<snicker>
Um, what you claimed he was “babbling about”. Claims with as much merit as this one.
(But kudos for your malevolence and your negging — exemplary effort)
Nomad@#6:
I didn’t fuck up at all, that’s why I’m not apologizing.
I didn’t say anything about evidence of CIA false flag operations, either. If you’re going to attack my postings, please restrict yourself to attacking things I’ve actually said. And if you’re going to accuse me of being inaccurate or dishonest, you probably would do well to demonstrate a higher level of accuracy and intellectual honesty, yourself.
PS – I’m not sure we’d agree what a “liberal” is but I’m fairly sure I’m not one. If you’re going to start throwing labels around you’re going to get tedious pretty quickly. Maybe you should define your terms.
I seem to remember an annual code obfuscation contest back in the 1980s or so. The idea was to write C code that did something but was almost impossible for the average programmer to follow. The real trick was to make sure that the program was tiny, thus, the result looked like just a half page of random symbols. Once you throw #defs and typedefs in there along with pointer side effects, you can create some serious weirdness.
I teach my freshmen Python. Second years learn C. I tell them that Python is like a nice hatchback and C is like a Ferrari: The performance of a Ferrari can be stunning but you don’t want to give those keys to an uninitiated 16 year old with a learner’s permit. In C, you miss one * or &, or put a ; in the wrong spot, and your code goes off into never-never land.
jimf@#9:
The obfuscated C code contest was a thing in the 80s. There were some incredible howlers produced from that. There’s an archive here.
Once you throw #defs and typedefs in there along with pointer side effects, you can create some serious weirdness.
The joke I heard was that C++ ruined the contest by making it so easy that anyone could play. I remember someone posting code that did:
printf(“%d\n”, 2 + 2);
and printed 5.
USENIX also used to have an ‘obfuscated/abuse of UNIX tools’ contest, which I have the distinction of winning in 1991.
Re: Python VS C – I agree, though I find that compiled code is almost always easier to debug. One of the things that drives me nuts is that new programmers are taught how to write code in environments for which debuggers do not exist. That’s a big problem with webby distributed systems wherein it’s very hard to tell what’s actually where, and debugging consists of whacking page reload a bunch and seeing what happens. C has its problems, but newer programming environments manage to be worse and produce slower code.
python has the amusing property that you cannot reliably determine what a name (a variable, or whatever) refers to without running the program. So it is in fact literally impossible to understand the text of the program without executing the program.
You can “execute” it in your head if you like, or use a symbolic execution system to discover collections of possibilities for what the use of “foo” at line 287 of blat,.py refers to, and often that collection will only contain one thing, so you’re done. But not always.
… which produces the interesting case of code which appears to be completely readonable, completely comprehensible, but which is in fact completely opaque! You think you know what’s going on, but you’re wrong.
Andrew Molitor@#12:
That sounds awesome!!!
… if you’re writing malware.
(Though I think the best tools for writing malware remain /bin/sh and troff.)
There was a cool thing years ago, a competition to make the smallest .exe or .com 16 bit executables written in assembly that did something interesting. I remember downloading some of the examples which were so small, and what they did was very cool.
There’s something spartan about assembler that is almost romantic, but fuck that, I’ll happily work in C# or whatever.
Andrew Molitor@#12:
Is that python-specific or a more general statement about any language where “everything is an object”?
For my own python programming and the benefit of my IDE’s inspection tools, my code is littered with lines like these:
assert isinstance(object, type_to_confirm)
I think this site (well, not this site as it’s a mirror), but I think it has the stuff I was talking about:
http://ftp.lanet.lv/ftp/mirror/x2ftp/msdos/